KalmanFilter
https://github.com/tbmoon/kalman_filter
https://github.com/DonghoonPark12/Book_KalmanFilter
https://m.blog.naver.com/skwd123/221827247721
https://minding-deep-learning.tistory.com/33
칼만 필터는 시스템의 상태를 추정하는데 사용되는 통계적인 방법입니다. 주로 시간에 따라 변하는 시스템 상태를 추론할 때 사용됩니다. 예를 들어, 자율 주행 자동차의 위치를 추정하거나, 로봇이 자신의 환경을 파악하는 경우에 활용될 수 있습니다.
칼만 필터는 두 가지 주요 구성 요소로 이루어져 있습니다: 예측 단계와 업데이트 단계입니다.
- 예측 단계: 시스템의 현재 상태를 예측합니다. 이 예측은 이전 상태와 시스템에 대한 모델을 사용하여 이루어집니다. 모델은 시스템의 동작을 설명하는 수학적인 방정식으로 표현됩니다. 이 예측은 현재 상태에 대한 추정치와 오차 공분산을 생성합니다.
- 업데이트 단계: 측정값을 사용하여 예측한 상태를 업데이트합니다. 예측 단계에서 생성된 예측치와 측정값 사이의 차이를 계산합니다. 이 차이를 이용하여 예측된 상태와 오차 공분산을 보정합니다. 이렇게 보정된 값은 더 정확한 상태 추정치를 제공합니다.
칼만 필터는 미래 상태의 예측 오차와 현재 측정값의 불확실성을 이용하여 시스템의 상태를 추정하는 데 사용됩니다. 이를 통해 노이즈와 불확실성이 있는 측정 데이터를 처리하고, 예측 오차를 줄이며, 시스템 상태 추정 결과를 최적화할 수 있습니다.
Recursive Filter
1. 평균 필터
데이터를 실시간으로 처리해야 한다면 배치식(데이터를 모두 모아서 한꺼번에 계산하는 식)이 아닌
재귀식(이전 결과를 재사용하여 값을 계산하는 식) 형태의 필터가 필수입니다.
평균필터(재귀식)를 사용하면, 직전 평균값과 데이터 개수만 알아도 쉽게 평균을 구할 수 있습니다.
특히 데이터가 순차적으로 입력되는 경우, 평균필터를 사용하면 데이터를 저장할 필요가 없고 계산 효율도 높습니다.
ex) 센서 초기화 : 디지털 체중계 (여러가지 이유로 영점이 바뀌므로, 전원 킬 때 일정시간동안 센서 출력값의 평균으로 영점을 잡는 초기화 작업 –> 평균필터 사용)
2. Moving 평균 필터
이동평균은 모든 측정 데이터가 아니라, 지정된 개수의 최근 측정값만 가지고 계산한 평균입니다.
이동평균 필터는 측정 데이터의 잡음을 제거하는 데 유용합니다. 평균 계산에 포함되는 데이터 개수가 많으면 잡음 제거 성능은 좋아지지만 측정 신호의 변화가 제때 반영되지 않고 시간 지연이 생깁니다. 반대로 데이터 개수가 적으면 측정 신호의 변화는 잘 따라가지만 잡음이 잘 제거되지 않습니다. 따라서 측정하려는 신호의 특정을 잘 파악해 이동 평균의 데이터 개수를 선정해야 합니다. 끝으로 이동 평균 필터는 평균 필터와 달리 알고리즘을 재귀식으로 바꿔도 별 이점이 없었습니다.
이동평균 필터를 변화가 심한 신호에 적용하면, 잡음 제거와 변화 민감성으 동시에 달성하기 어렵습니다.
3. 저주파 통과 필터 (exponential weighted Moving 평균필터)
저주파 통과 필터는 저주파 신호는 통과시키고 고주파 신호는 걸러내는 필터입니다.
대개 측정하려는 신호는 저주파이고, 잡음은 고주파 성분으로 되어 있기 때문입니다.
(저주파만 통과시키는 특성을 가진 모든 필터를 총칭하는 일반 명사)
저주파 통과필터는 오래된 측정값일수록 더 작은 가중치를 부여하는 필터입니다.
1차 저주파 통과 필터를 지수 가중(exponentially weighted ) 이동평균 필터라고도 부릅니다.
1차 저주파 통과 필터의 수식은 매우 단순해서 구현하기도 쉽습니다.
게다가 이동평균 필터와 달리, 최신 측정값일 수록 가중치를 높게 주는 좋은 특성을 가졌습니다.
이 덕분에 측정 신호의 변화 추이를 이동평균 필터보다 더 잘 감지해냅니다.
Kalman Filter
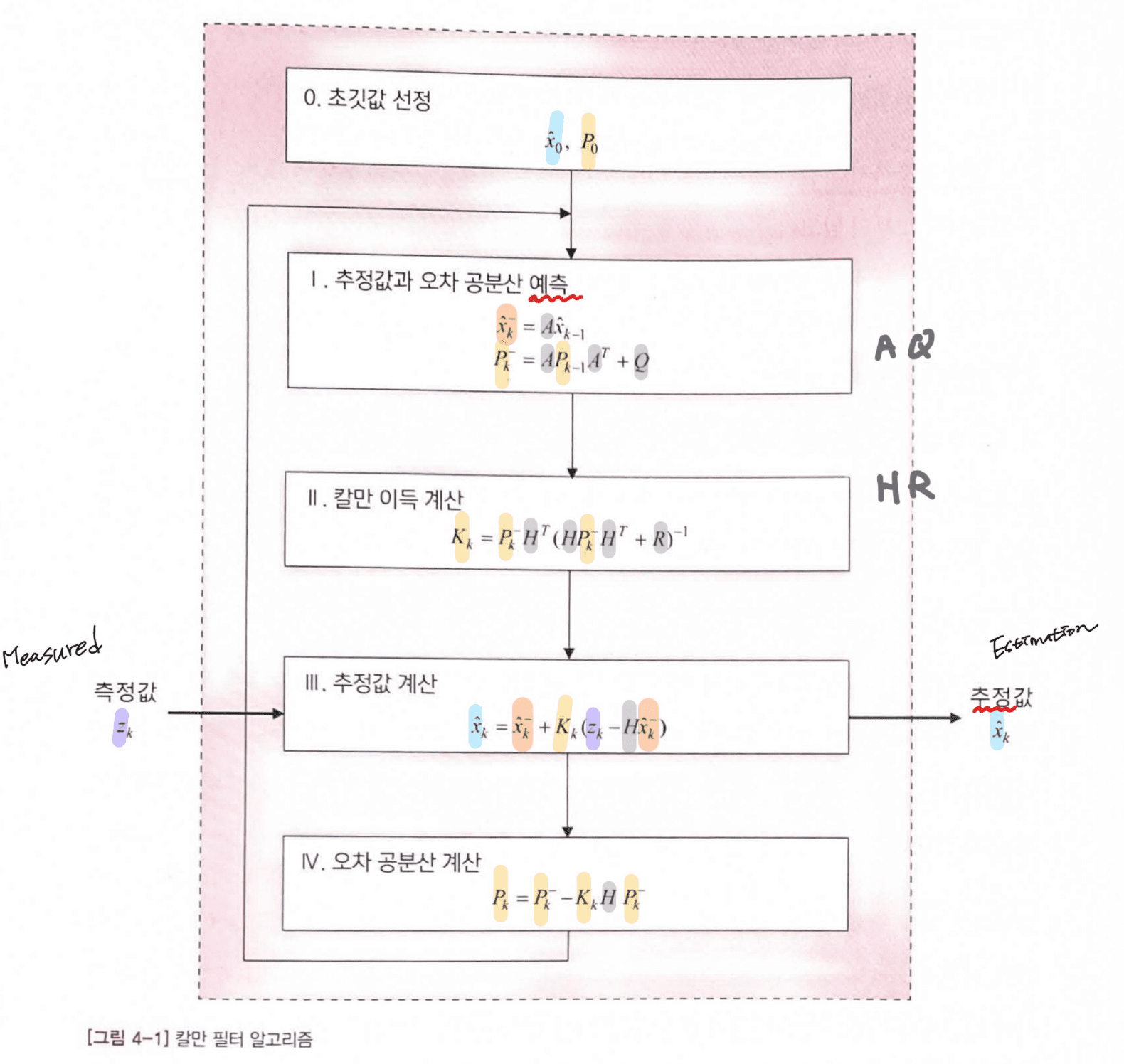

0) 초깃값 선정
[예측 과정](입력: 직전 추정값, 오차 공분산 / 출력: 예측값 / 사용 시스템 모델 변수: A, Q)
Ⅰ) 추정값과 오차 공분산 예측
[추정 과정](입력: 예측값,측정값 / 출력: 추정값,오차 공분산 / 사용 시스템 모델 변수: H, R)
Ⅱ) 칼만 이득 계산
Ⅲ) 추정값 계산 (저주파 통과 필터와 관련이 있습니다.)
Ⅳ) 오차 공분산 계산(오차 공분산은 추정값이 얼마나 정확한지를 알려주는 척도로 사용됩니다.)
칼만필터를 사용할 때는 시스템 모델과 관련된 네개의 변수 A,H,Q,R만 수정을 하여야 합니다. 칼만 필터의 성능은시스템 모델이 시스템 모델이 실제 시스템과 가까울수록 좋아집니다.
1. 시스템 모델 (A,Q)을 기초로 다음 시각에 상태와 오차 공분산이 어떤 값이 될지를 예측합니다.
2. 측정값과 예측값의 차이를 보정해서 새로운 추정값을 계산합니다. 이 추정값이 칼만 필터의 최종 결과물입니다.
3. 위의 두 과정을 반복합니다.
5. 추정 (2,3,4)
칼만 필터는 1차 저주파 통과 필터와 비슷한 방식으로 추정값을 계산(Ⅲ)합니다.
그런데 가중치를 조절하는 칼만이득(Ⅱ)은 고정되어 있지 않고, (일정한 공식에 따라) 매번 새로 계산됩니다.
즉 추정값 계산식의 “가중치”가 계속 바뀝니다.
칼만 필터 알고리즘에서는 추정값의 오차 공분산(Ⅳ)도 매번 계산하는데, 이 값이 추정값의 정확도를 나타내는 지표 역할을 합니다.
6. 예측 (1)
같은 시각에 측정값을 받아 계산하는 과정이 ‘추정’이고 ,
다음 시각으로 이동하면서 행렬A를 거치는 과정이 ‘예측’입니다.Ⅰ
‘칼만 필터는 측정값의 예측오차로 예측값을 적절히 보정해서 최종 추정값을 계산한다.’
이때 칼만 이득은 예측값을 얼마나 보정할지 결정하는 인자가 됩니다.
칼만 필터의 성능은 시스템 모델에 달려있다고 할 수 있습니다.
시스템 모델이 실제 시스템과 얼마나 비슷한지에 따라 예측의 질이 달라지고, 예측값에 따라 추정 성능도 좌우되기 때문입니다.
7. 시스템 모델
- 시스템모델 : x(k+1) = Ax(k) + w(k) , w(k) ~ N(0, Q)
- 측정모델 : z(k) = Hx(k) + v(k) , v(k) ~ N(0, R)
시스템 모델은 우리가 다루는 문제를 수학식으로 표현해 놓은 것(≒function)을 말합니다.
진짜 어려운 작업은 시스템을 수학적으로 모델링하여 시스템 모델을 유도해내는 일입니다.
만약 참고할 만한 시스템 모델이 전혀 없는 완전히 새로운 분야에 칼만 필터를 적용해야 한다면, 선형 시스템과 시스템 모델을 바닥부터 차근 차근 공부하는 정공법을 선택하는 것이 나을 겁니다.
단순히 칼만 필터를 가져다 쓰는 경우,상태 모델의 개념을 이해하고, 관련 수식의 의미를 읽어낼 수는 있어야 합니다.
행렬 A는 시간에 따라 시스템이 어떻게 움직이는지를 나타냅니다. 즉 시스템의 운동 방정식을 담고 있습니다.
행렬 H는 측정값과 상태 변수의 관계를 나타냅니다.
Q가 커지면 칼만 이득도 커집니다.
측정값의 영향을 덜 받고 변화가 완만한 추정값을 얻고 싶다면 행렬 Q를 줄여야 합니다.
w의 공분산행렬 => 시스템에 대한 지식과 경험.
R이 커지면 칼만 이득은 작아집니다.
칼만 이득이 작아지면 추정값 계산에 측정값이 반영되는 비율도 작아집니다.
반면 예측값의 반영비율은 높아집니다. 측정값의 영향을 덜 받고 변화가 완만한 추정값을 얻고 싶다면 행렬 R을 키우면 됩니다.
v의 공분산행렬 => 측정잡음. 센서제작사에서 제공된 값활용, 실험/경험을 통해 결정
[요약]
칼만 필터를 설계하려면 가장 먼저 대상 시스템을 모델링하여 다음과 같은 형태의 시스템 모델을 구성해야 합니다. 칼만 필터의 성능은 시스템 모델이 실제 시스템과 얼마나 비슷한지에 따라 성능이 크게 달라집니다. 칼만 필터에서는 잡음도 중요한 역할을 합니다. 따라서 시스템 모델을 유도할 때 잡음의 특성도 정확히 파악하도록 해야 합니다. 칼만 필터에서 다루는 잡음은 정규분포를 따르는 백색 잡음입니다.
응용 예시
1. 잡음제거 : volt 측정잡음 제거하기
초간단 칼만필터 예제 (not use 저주파통과 필터 )
칼만 필터 알고리즘의 구현은 계속 이야기한 거서럼 그대로 구현하는 것으로 충분했습니다.
오히려 문제에 맞는 시스템 모델을 선정하는 게 더 어려웠습니다.
그리고 추정 오차가 줄어들때 오차 공분산과 칼만 이득이 어떻게 변하는지도 살펴 봤습니다.
2. 측정되지않은 상태변수 추청 : 위치로 속도 추정하기, 속도로 위치 추정하기
칼만 필터가 측정하지 않은 물리량까지 추정해내는 능력은 바로 ‘시스템 모델‘ 덕분입니다.
그런데 추정에 시스템 모델을 이용하는 것은 양날의 검과 같습니다.
시스템 모델이 실제 시스템과 많이 다를 경우, 추정 결과가 엉망이 될 뿐만 아니라, 심하면 칼만 필터 알고리즘이 발산해서 전체 시스템이 망가질 수도 있기 때문입니다.

초음파 거리계로 속도 측정하기
”
3. 영상 속의 물체 추적하기
칼만 필터는 잡음을 제거하거나 측정하지 않은 값을 추정해내는 등의 역할을 했습니다. 표적 추적 문제에서도 칼만 필터의 역할은 동일합니다.
영상처리 알고리즘으로 얻은 위치의 오차를 제거하고 이동 속도 등을 추정하는 데 칼만 필터가 활용됩니다.
4. 센서율합 : 기울기 자세 측정하기
칼만 필터는 개발된 직후에 바로 미국의 아폴로 달 탐사 프로그램에 적용되면서 일약 스타로 떠올랐습니다. 가장 많은 응용 사례가 있는 곳도 항공우주 분야입니다. 특히 항공기나 인공위성의 위치와 자세를 측정하는 항법 분야에서는 그 영향력이 절대적이라고 할 만큼 칼만 필터가 많이 사용됩니다.
여러 센서의 출력을 모아서 더 좋은 성능을 끌어내는 기법을 센서 융합(sensor fusion)이라고 하며, ‘센서 결합’ 이라는 용어도 많이 씁니다.
[자이로(gyroscope)로 측정한 각속도]
각속도를 적분하여 얻은 자세는 동적 움직임은 잘 포착해내지만, 점차 오차가 누적되어 실제 값에서 멀어지는 특성이 있음을 알았습니다. 따라서 자이로는 측정보다는 자세각의 동태를 측정하는 데 유용합니다. 자이로는 단기간의 측정에서는 비교적 정확하지만 장시간의 변화에는 부정확한 센서라 하겠습니다.
[가속도계(accelerometer)를 이용하여 자세 결정하기]
가속도계로 측정한 가속도에는 중력 가속도와 속도의 크기나 방향이 바뀔 때 생기는 가속도 등 다양한 종류의 가속도가 포함되어 있습니다.
이동속도와 이동 가속도 두값은 아주 고가의 항법 센서가 아니면 측정할 수 없습니다. 따라서 평범한 항법 센서로는 자세를 계산할 방법이 없습니다.
시스템이 정지해 있거나 일정한 속도로 직진한다는 조건이라면 가능합니다. 근사식은 제자리 비행이나, 일정 속도로 움직이는 경우에 잘 맞습니다.
보행 로봇도 대부분 비슷한 조건에서 움직이므로 근사식은 유용합니다.
가속도계의 오차는 발산하지 않고 일정한 범위 안에 머무르는 장점을 갖고 있습니다. 자세를 구하는 과정에서 적분을 하지 않기 때문입니다. 하지만 안전성이 높은 대신 정밀도는 떨어진다는 점이 있습니다. 자세 계산식이 가속도나 각속도가 충분히 작은 상황에서만 쓸 수 있는 근사식이기 때문입니다.
[센서 융합을 통해 자세 결정하기]
자이로로 구한 자세는 자세 변화를 잘 감지하지만, 시간이 지남에 따라 오차가 누적되어 발산하는 문제가 있었습니다. 반면 가속도계로 구한
자세는 시간이 지나도 그 오차가 커지지 않고 일정 범위로 제한되는 장점을 가지고 있습니다 . 즉 단기적으로는 자이로 자세가 더 낫지만, 중장기적으로는 가속도 센서 자세가 더 좋습니다. 자이로의 누적 오차 문제를 가속도계로 보정하면 좋습니다.
비선형 시스템
12. 확장 칼만 필터
확장 칼만 필터는 비선형 시스템에서도 동작이 될 수 있게 하기 위해 개발 되었습니다. 세계 최초로 실제 문제에 구현된 칼만 필터도 선형 칼만 필터가 아니라 EKF 였습니다. EKF에 단점은 발산할 위험이 있습니다.
선형화 칼만 필터는 비선형 시스템의 하나의 기준점 주위에서 선형화 시켜 얻은 선형 모델 A와 H를 사용합니다. 즉 비선형 모델을 형화한 다음, 이 선형 모델에 대해 설계한 칼만 필터가 바로 선형화 칼만 필터입니다. 선형화 모델은 기준점 근처에서만 실제 시스템과 비슷한 특성을 보이기 때문에 이 범위를 벗어나면 선형화 모델은 더 이상 믿을 수 없게 됩니다.
EKF는 직전 추정값를 선형화의 기준으로 삼는다는 점에서 선형화 칼만 필터와 차이가 납니다. EKF는 미리 결정된 선형화 기준을 사용하지 않고, 직전 추정값을 기준으로 삼아 매번 새로 선형 모델을 구합니다. 따라서 이 방식은 선형화의 기준점을 사전에 설정하기
어려운 시스템에 적합합니다. 반면 선형화의 기준을 이미 알고 있다면 굳이 이렇게 할 필요는 없습니다. 일정 궤도를 도는 위성이나 궤적이 미리 정해져 있는 위성 발사체 등이 이런 경우에 해당됩니다.
[요약]
EKF는 선형 모델식 자리에 비선형 시스템 모델식를 사용합니다. 두번째로 EKF 는 비선형 모델의 야코비안으로 행렬 A와 H를 구한다는 점입니다.
이때 야코비안 행렬은 직전 추정값을 기준으로 계산합니다.
13. 무향 칼만 필터
UKF는 문제를 풀기 위해 선형화를 통한 근사화 대신 샘플링을 통한 근사화 전략을 사용합니다. 즉 시스템 모델 수식을 직접 다루지 않고 시스템을 대표하는 몇 개의 데이터를 이용해 상태 변수와 오차 공분산의 예측값을 계산합니다.
상태 변수와 오차 공분산의 예측값을 시스템 모델식으로부터 직접 계산하는 대신 몇 개의 대표값(시그마 포인트)을 선정하고 이 값의 변환데이터로부터 간접적으로 구하자는 게 UKF의 핵심 전략입니다.
[요약]
UKF는 비선형 함수 자체를 모사하는 것보다는 이 함수의 확률 분포를 모사하는 게 더 낫다는 전략에 따라 고안된 비선형 칼만 필터입니다.
다시 말해 비선형 함수를 근사화한 선형 함수를 찾는 대신 비선형 함수의 평균과 공분산을 근사적으로 직접 구하는 게 더 유리하다는 뜻입니다.
덕분에 UKF는 야코비안을 이용한 선형 모델이 불안정하거나 구현하기 어려운 경우에 EKF의 좋은 대안이 될 수 있습니다. 알고리즘 구현도 EKF와 비교해 그리 복잡하지 않아 실용적입니다.
대체로 야코비안을 해석적으로 쉽게 구할 수 있으면 EKF가 계산 시간 측면에서 다소 유리합니다. 반대로 야코비안을 구하기 어렵거나, EKF가 발산할 염려가 있을 때는 UKF를 쓰는 게 더 낫습니다. 그리고 두 필터 모두 근사적으로 예측값을 구하지만, UKF가 더 정확한 근사식을 사용한다는 점도 참고하시기 바랍니다. 미심쩍을 때는 둘 다 구현해서 성능을 직접 비교해 보는게 제일 좋겠습니다.
