Backpropagation
해석적 미분
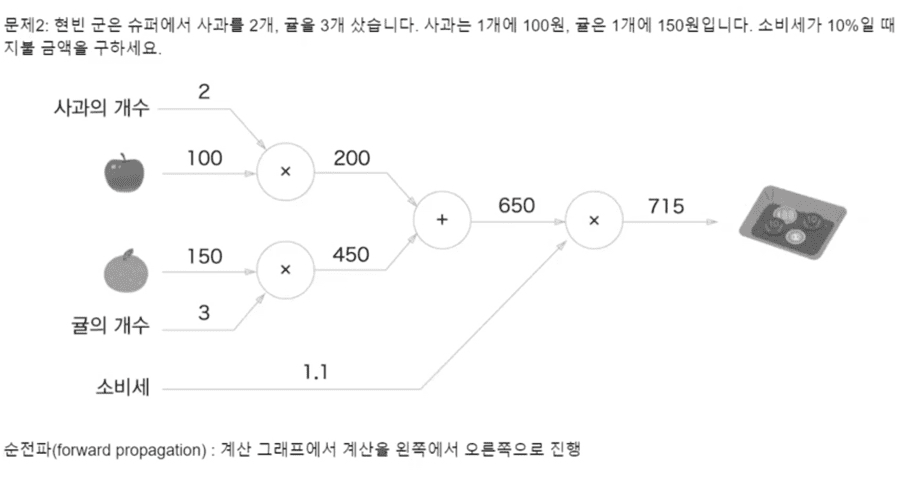
[수치미분외에] 가중치W매개변수에 대한 Loss function의 gradient를 구하는 방법=> 계산그래프 (Node와 edge로 데이터를 표현)
sigmoid
affine
softmax
기울기 소실(Vanishing Gradient)
https://heytech.tistory.com/388
Layer가 많아질수록 기울기 소실(Vanishing Gradient) 현상때문 학습이 잘 되지 않습니다.
Vanishing Gradient란 Backpropagation과정에서, 출력층에서 멀어질수록 Gradient 값이 매우 작아지는 현상을 말합니다
왜 이런 기울기 소실 문제가 발생할까요?
활성화 함수(Activation Function)의 기울기와 관련이 깊습니다.
Sigmoid 함수의 미분 값은 입력값이 0일 때 가장 크지만 0.25에 불과하고 x값이 크거나 작아짐에 따라 기울기는 거의 0에 수렴하는 것을 확인하실 수 있습니다. 따라서, 역전파 과정에서 Sigmoid 함수의 미분값이 거듭 곱해지면 출력층과 멀어질수록 Gradient 값이 매우 작아질 수밖에 없습니다.
기울기 소실 문제를 해결한 활성화 함수로 ReLU가 제안
