imdb nn-data (binary classification)
predict a single discrete label
Loading DATA
source(file.path(getwd(),"../00.global_dl.R")) ### Title: IMDB binary classification --- --- --- -- --- --- --- --- --- --- ---- # Deep Learning with R by François Chollet :: 3.4 Classifying movie reviews ##1. Loading DATA ------------------------------------------------------- # imdb <- dataset_imdb(num_words=10000) imdb <- readRDS(file.path(DATA_PATH,"imdb.RData")) c(c(trnData, trnLabels), c(tstData, tstLabels)) %<-% imdb
Preprocessing
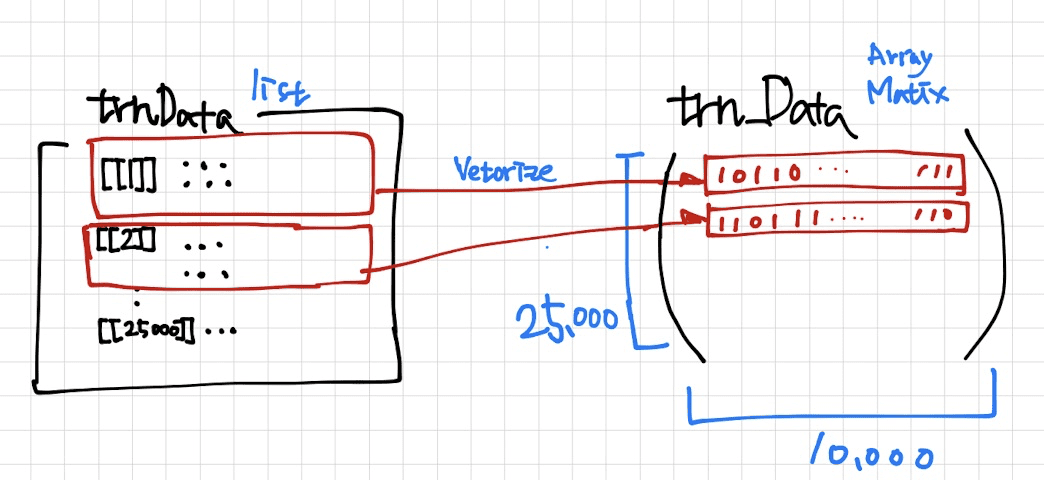
List -> Matrix
way1. pad_sequence
List를 Matrix로 reshape[sample, feature]할때, 각기 다른 행의 length를 맞추기위해
잘라내거나(truncating)나 특정value로 채워넣는(padding) 함수
MAX_LEN <- 20 trnData <- pad_sequences(trnData, maxlen=MAX_LEN) tstData <- pad_sequences(tstData, maxlen=MAX_LEN)
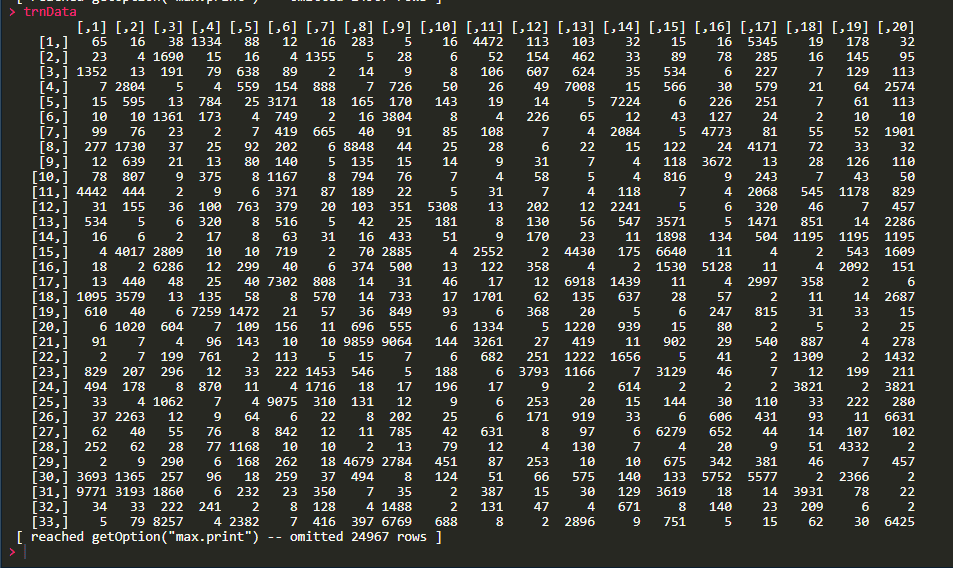
exList <- list( c( 1, 2, 3, 4, 5, 6, 7, 8, 9, 10), \t\t\t\tc( 2, 3, 4 ), \t\t\t\tc( 3, 4, 5, 6, 7, 8), \t\t\t\tc( 4 )) > exList %>% pad_sequences(maxlen=5) # [,1] [,2] [,3] [,4] [,5] # [1,] 6 7 8 9 10 # [2,] 0 0 2 3 4 # [3,] 4 5 6 7 8 # [4,] 0 0 0 0 4\t\t\t\t\t\t\t\t pad_sequences(sequences=exList, maxlen=NULL, dtype="int32", \t\t\t truncating="pre", padding="pre", value=0) # [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] # [1,] 1 2 3 4 5 6 7 8 9 10 # [2,] 0 0 0 0 0 0 0 2 3 4 # [3,] 0 0 0 0 3 4 5 6 7 8 # [4,] 0 0 0 0 0 0 0 0 0 4 pad_sequences(sequences=exList[2:4], maxlen=5, \t\t\ttruncating="pre", padding="pre", value=0) # [,1] [,2] [,3] [,4] [,5] # [1,] 0 0 2 3 4 # [2,] 4 5 6 7 8 # [3,] 0 0 0 0 4 pad_sequences(sequences=exList[2:4], maxlen=5, \t\t\ttruncating="post", padding="pre", value=0) # [,1] [,2] [,3] [,4] [,5] # [1,] 0 0 2 3 4 # [2,] 3 4 5 6 7 # [3,] 0 0 0 0 4 pad_sequences(sequences=exList[2:4], maxlen=5, \t\t\ttruncating="post", padding="post", value=0) # [,1] [,2] [,3] [,4] [,5] # [1,] 2 3 4 0 0 # [2,] 3 4 5 6 7 # [3,] 4 0 0 0 0 pad_sequences(sequences=exList[2:4], maxlen=5, \t\t\ttruncating="post", padding="post", value=99) # [,1] [,2] [,3] [,4] [,5] # [1,] 2 3 4 99 99 # [2,] 3 4 5 6 7 # [3,] 4 99 99 99 99
way2. uF_vectorize_sequences
uF_vectorize_sequences <- function(txxDataList, dimemsion=10000){
results <- matrix(0, nrow=length(txxDataList), ncol=dimemsion) # all 0 matrix [25000, 10000]
for (sample in seq_along(txxDataList)){
results[sample, txxDataList[[sample]] ] <- 1
}
return(results)
}
exList <- list( c( 1, 2, 3, 4, 5, 6, 7, 8, 9, 10),
\t\t\t\tc( 2, 3, 4 ),
\t\t\t\tc( 3, 4, 5, 6, 7, 8),
\t\t\t\tc( 4 ))
uF_vectorize_sequences <- function(txxdataList, dimemsion=10000){
results <- matrix(0, nrow=length(txxdataList), ncol=dimemsion) # all 0 matrix
for (i in seq_along(txxdataList)){
results[i, txxdataList[[i]] ] <- 1
}
return(results)
}
uF_vectorize_sequences(exList, dimemsion=10)
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
# [1,] 1 1 1 1 1 1 1 1 1 1
# [2,] 0 1 1 1 0 0 0 0 0 0
# [3,] 0 0 1 1 1 1 1 1 0 0
# [4,] 0 0 0 1 0 0 0 0 0 0
trn_Data <- uF_vectorize_sequences(trnData) tst_Data <- uF_vectorize_sequences(tstData) # trnData %>% length() # 25000 No. of samples # lapply(trnData, max) %>% unlist %>% max # 9999 No. of max element in all list # trnData[[1]] %>% unique() %>% length() # 120 # trn_Data[1,] %>% sum() # 120
## ` ` Ploting -----------------------------------------------------------------
mxA <- trn_Data[seq_len(20), seq_len(10)]
dtA <- data.table(row=str_c("r", rep(seq_len(nrow(mxA)), times=ncol(mxA))),
\t\t\t\t\t\t\t\t\tcol=str_c("c", rep(seq_len(ncol(mxA)), each=nrow(mxA))),
\t\t\t\t\t\t\t\t\tval=c(mxA))
dtA[, row:=factor(row, levels=str_c("r", rep(seq_len(nrow(mxA)))) %>% rev())]
dtA[, col:=factor(col, levels=str_c("c", rep(seq_len(ncol(mxA)))) )]
dtA %>% ggplot(aes(x=col, y=row)) + geom_tile(aes(fill=val), color="white", size=.6) +
\tscale_fill_gradient(low="white", high="red") +
labs(x="sample", y="variable", title="Matrix ggplot")
code
source(file.path(getwd(),"../00.global_dl.R"))
### Title: IMDB binary classification --- --- --- -- --- --- --- --- --- --- ----
# Deep Learning with R by François Chollet :: 3.4 Classifying movie reviews
##1. Loading DATA -------------------------------------------------------
imdb <- readRDS(file.path(DATA_PATH,"imdb.RData"))
c(c(trnData, trnLabels), c(tstData, tstLabels)) %<-% imdb
##2# Preprocess : rescale & reshape -------------------------------------------------------
### way1
MAX_LEN <- 20
trnData <- pad_sequences(trnData, maxlen=MAX_LEN)
tstData <- pad_sequences(tstData, maxlen=MAX_LEN)
### way2
uF_vectorize_sequences <- function(txxDataList, dimemsion=10000){
results <- matrix(0, nrow=length(txxDataList), ncol=dimemsion) # all 0 matrix [25000, 10000]
for (sample in seq_along(txxDataList)){
results[sample, txxDataList[[sample]] ] <- 1
}
return(results)
}
trnData <- uF_vectorize_sequences(trnData)
tstData <- uF_vectorize_sequences(tstData)
