dplyr :: group_by(),filter(), select(),mutate(),arrange(),summarise()
http://dplyr.tidyverse.org/articles/two-table.html
http://r4ds.had.co.nz/transform.html
https://github.com/hadley
http://cran.r-project.org/web/packages/dplyr/vignettes/introduction.html
http://www.starkingdom.co.uk/r-data-frames-dplyr-vs-sqldf/
lecture
http://wsyang.com/2014/02/introduction-to-dplyr/
dplyr()이란 ?
vignette("introduction", package="dplyr") # dplyr의 주요 verbs에 대해
vignette("databases", package="dplyr") # dplyr이 DB와 어떻게 사용되는지
- Hadley Wickham이 만든 팩키지 중 하나 : dplyr, reshape2, ggplot2
- plyr 팩키지는 모든 함수가 R로 작성되어 처리 속도가 느리다는 단점이 있었으나,
dplyr 팩키지는 C++로 작성되어 불필요한 함수를 불러오지 않기 때문에 처리속도가 빠르다. - dplyr 패키지는 data.frame 처리뿐아니라, 아래 형식의 데이터를 이용가능함
– data.table와 함께 사용하면, 단순히 data.frame을 사용했을 때보다 속도가 빠르다
dplyr also provides data table methods for all verbs through dtplyr.
– 각종 데이터베이스 : 현재 MySQL, PostgreSQL, SQLite, BigQuery를 지원
– 데이터 큐브 : dplyr 패키지 내부에 실험적으로 내장됨 tbl_cube() - 결과는 data.frame (결과가 항상 같은 형식으로 나와 Chaining이 가능)
* plyr 와 dplyr 를 함께 사용할때에는 항상 plyr 라이브러리를 dplyr보다 먼저 로딩해야한다.
- tidyr
- dplyr
- row
filter(), distinct(),arrange()- sample_n(), slice_sample(), sample_frac()
group_by(),summarise(), summarise_each()
- column
- two table
join(), right_join()
- etc.
- rename()
- row
- tibble
rownames_to_column
Verb
dplyr 패키지의 기본이 되는 것은 다음 5개 함수입니다.
Single-table verb
row
| 함수명 | 내용 | 유사함수 |
| arrange() | 정렬 | order(), sort() |
| filter() | 조건에 맞는 “행”데이터 추출, slice()는 위치기준에 맞게 추출 | subset() |
| distinct() | unique() |
Column
| 함수명 | 내용 | 유사함수 |
| select() | 기존의 열 추출 | data[, c(“Year”, Month”)], rename() |
| mutate() | 새로운 열 추가, transmute() | transform() |
| summarise() | 집계 | aggregate() |
그룹 Operation
| 함수명 | 내용 | 유사함수 |
|---|---|---|
| group_by() | 그룹별로 다양한 집계 |
dplyr 때문에 Overwrite된 기본 filter()와 lag()를 사용하려면,
stats::filter() , stats::lag()로 사용하면 됨
multiful-table verb
| 함수명 | 내용 |
|---|---|
| left join | all x + matching y |
| inner join | matching x + y |
| semi join | all x with matching in y |
| anti join | all x without matching in y |
예제
0. 데이터 준비
data – nycflights13 : # NYC를 출발하는 모든 비행기의 2013년 이착륙기록 , # 336,776건의 이착륙기록에 대해 19개 항목을 수집한 데이터
data.frame에서 tbl_df 객체로생성.
flights <- nycflights13::flights %>% tbl_df()
1.<Row행> 정렬 – arrange()
order by와 비슷한 기능.
지정한 열을 기준으로 작은 값으로부터 큰 값의 순으로 데이터를 정렬, 역순으로 정렬시 desc()활용
year, month, day 순으로 정렬
flights %>% arrange(year, month, day) # arrange(flights_df, year, month, day) # flights[order(flights$year, flights$month, flights$day), ] #base R
descending order (역순)
flights %>% arrange(desc(arr_delay)) # arrange(flights_df, desc(arr_delay)) # flights[order(flights$arr_delay, decreasing = TRUE), ] #base R # flights[order(-flights$arr_delay), ]
Missing values
Ascending, descending 이든 항상 가장 마지막에 정렬된다.
2. <Row행>의 일부 데이터 추출 – filter()
조건에 따라 행(row)의 subset 추출
# 1월 1일 데이터 추출 flights %>% filter(month==1 & day==1) #filter(flights, month==1 & day==1) # flights[flights$month==1 & flights$day==1, ] #base R # A tibble: 842 × 19 # year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay carrier ##1 2013 1 1 517 515 2 830 819 11 UA #2 2013 1 1 533 529 4 850 830 20 UA #3 2013 1 1 542 540 2 923 850 33 AA
Logical operators
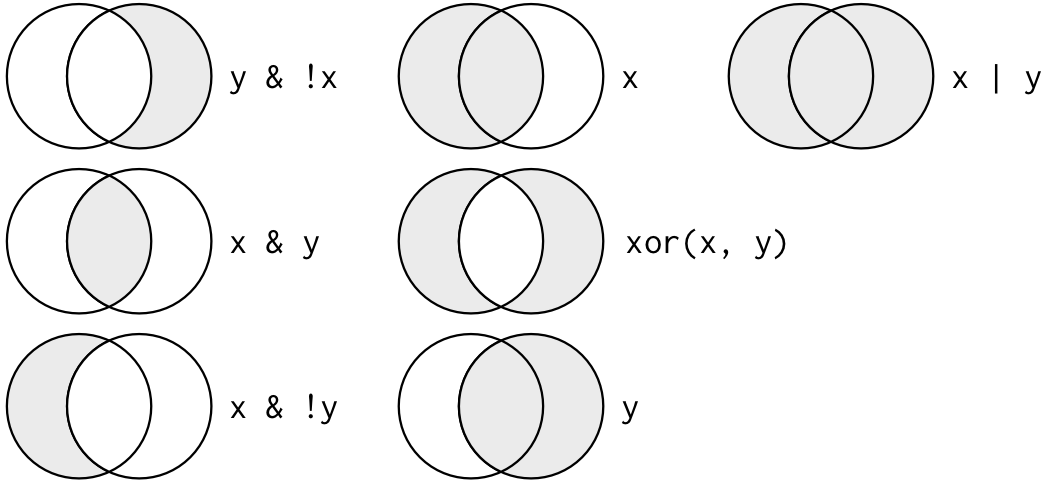
De Morgan’s law: !(x & y) is the same as !x | !y,!(x | y) is the same as !x & !y.
Don’t use && and ||.
기본적으로 , 는 AND & 조건
filter(flights, month==1 , day==1) # operator , filter(flights, month==1 | day==1) # operator | slice(flights, 1:10) #To select rows by position
OR | 조건 예
# 10월~12월 데이터 추출 flights %>% filter(month==10 | month==11 | month==12) flights %>% filter(month %in% c(10, 11, 12)) flights %>% filter(between (month, 10, 12)) ## 잘못쓴 예 flights %>% filter(month == 10 | 11 | 12) #To select rows by position
filter + str_dect(), between()
dd %>% filter(str_detect(이름, “식$”))
dd %>% filter(between(나이, 17, 24))
NA (Not available, Unknown value)
거의 모든 연산에 대한 NA의 결과는 NA 다.
NA == NA ; 6 == NA ; NA > 6 ; NA + 6 ; NA / 6 ; NA * 0 # [1] NA
예외>
NA ^ 0 ; NA | TRUE ; FALSE & NA # [1] 1 [1] TRUE [1] FALSE
is.na(x) NA 를 찾는 가장 좋은 방법
is.na(x) #> [1] TRUE
3.<Row행> distinct (unique) 행 추출 – distinct()
flights %>% distinct(month, day) #distinct(flights, month, day) # unique(flights_df$day) #base R
4.<Column열> 추출 – select()
flights %>% select(year, month, day)
#select(flights, year, month, day)
# 벡터 활용
vars <- c("year", "month", "day", "dep_delay", "arr_delay")
flights %>% select(vars)
지정한 열 제외 -
flights %>% select( -(year:day))
지정한 열 뒤에 모든 열 everything()
flights %>% select(time_hour, air_time, everything())
같이 쓰기 유용한 함수들
| starts_with(“abc”) | “abc” 로 시작하는.. |
| ends_with(“xyz”) | “xyz” 로 끝나는 |
| contains(“ijk”) | “ijk” 를 포함하는 (대소문자구분 안함) |
| matches(“(.)\\1”) | 정규식을 만족하는 (in 과 비슷) |
| num_range(“x”, 1:3) | matches x1, x2 and x3 |
5.<Column열> 신규 열 추가 – mutate()
transform()도 비슷한 기능을 하지만, mutate()는 추가된 열을 같은 함수에서 바로 사용가능
flights %>% mutate(
gain = arr_delay-dep_delay,
speed = distance/air_time*60,
gain_per_hour = gain/(air_time/60) # 신규열gain을 gain_per_hour의 계산에 바로사용, transform()에서는 안됨
)
추가된 열만 사용할때 transmute()
flights %>% mutate(
gain = arr_delay-dep_delay,
speed = distance/air_time*60
) %>% select(gain, speed)
flights %>% transmute(
gain = arr_delay-dep_delay,
speed = distance/air_time*60
)
연산
http://r4ds.had.co.nz/transform.html#mutate-funs
6. 집계 – summarise()
group_by와 함께 사용할때, 훨씬 더 유용하다.
min(), max(), mean(), sum(), sd(), var(), median(), and IQR()등의 함수를 지정하여 기초 통계량 계산
dplyr에서 추가적으로 제공하는 함수들 n(): 현 그룹의 obs.갯수, n_distinct(x): unique값의 갯수,
first(x): x[1] , last(x): x[length(x)], nth(x, n)
# 평균 출발지연시간 계산 flights %>% summarise(delay = mean(dep_delay, na.rm = TRUE)) # A tibble: 1 × 1 # delay ##1 12.64
group_by()와 함께
flights %>% group_by(year, month, day) %>%
summarise(delay = mean(dep_delay, na.rm = TRUE))
NA 값 미리 제거
flights %>% filter(!is.na(dep_delay), !is.na(arr_delay)) %>%
group_by(year, month, day) %>%
summarise(delay = mean(dep_delay))
7.<Row행> 그룹화 – group_by()
지정한 열의 수준(level)별로 그룹화된 결과를 얻을 수 있습니다.
by_tailnum <- group_by(flights, tailnum)
delay <- summarise(by_tailnum,
count = n(),
dist = mean(distance, na.rm=T),
delay = mean(arr_delay, na.rm=T))
delay <- filter(delay, count > 20, dist < 2000)
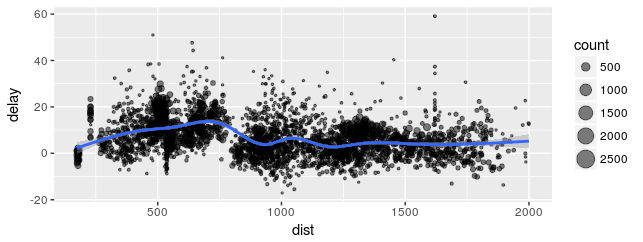
예> 항공사별로 평균 연착시간을 계산하고, 그 중 비행편수 20편 이상, 평균 비행 거리 2,000마일 이상
# delay is only slightly related to the average distance flown by a plane
ggplot(delay, aes(dist, delay)) +
geom_point(aes(size=count), alpha=1/2) +
geom_smooth() +
scale_size_area()
다른예
# 각 목적지별 비행기No 및 항공기 편수
destinations <- group_by(flights_df, dest)
summarise(destinations,
planes = n_distinct(tailnum),
flights = n()
)
# 일별(복합키) 편수
daily <- group_by(flights_df, year, month, day)
(per_day <- summarise(daily, flights = n()))
8. <Row행> 랜덤 샘플링 - sample_n()
bootstrap sample을 위해 replace = TRUE 옵션 사용
sample_n(flights, 10) # 샘플 수 sample_frac(flights, 0.01) # 샘플 비율
summarise_each(), mutate_each()
하나의 변수에 대해 복수의 통계값
library(dplyr)
mtcars <- mtcars %>%
tbl_df() %>%
select(cyl , mpg, disp)
### function N, variable N
# without group
mtcars %>%
summarise(min_mpg = min(mpg),
min_disp = min(disp),
max_mpg = max(mpg),
max_disp = max(disp))
mtcars %>%
summarise_each(funs(min, max) , mpg, disp)
# with group , setNames
mtcars %>%
group_by(cyl) %>%
summarise_each(funs(min, max) , mpg, disp) %>%
setNames(c("gear", "min_mpg", "min_disp", "max_mpg", "max_disp"))
Pipe, Chaining - chain()
ggplot2 패키지에서 ‘+’ 연산자 또는 Uninx의 pipe 연산와 비슷.
작성순서와 데이터변형 순서가 같다는 점이 장점
chain() 혹은 %>%를 이용하여 각 함수를 연결,
임시 dataFrame 생성없이 최종결과를 얻을 수 있음 ( 첫 번째 인수인 DataFrame생략.
http://datum.io/dplyr-easydatahandling/


다른 예>
library(dplyr) library(hflights) hflights_df <- tbl_df(hflights) hflights_df <- hflights %>% group_by(TailNum) %>% mutate(Rank = rank(desc(ArrDelay))) %>% select(TailNum, ArrDelay, Rank) hflights_df hflights_df$query hflights_df$explain
Window Functions
dplyr 패키지에서 유용한 기능 중에 하나가 window functions인데, lead 함수와 lag 함수가 상당히 유용하다.
vignette("introduction", package = "dplyr")
#install.packages("nycflights13")
library(nycflights13)
# NYC를 출발하는 모든 비행기의 2013년 이착륙기록
# 336,776건의 이착륙기록에 대해 19개 항목을 수집한 데이터
str(flights);head(flights)
library(dplyr)
#많은 관측치를 감안하여 tbl_df 형식으로 변환 (화면에 맞게 행/열 출력)
(flights_df <- tbl_df(flights))
filter(flights_df, month==1 & day==1)
# flights[flights$month==1 & flights$day==1, ] # base R
# filter(flights, month==1 , day==1) # operator ,
# filter(flights, month==1 | day==1) # operator |
# slice(flights, 1:10) #To select rows by position
# 데이터를 year, month, day 순으로 정렬
arrange(flights_df, year, month, day)
# flights[order(flights$year, flights$month, flights$day), ] # base R
# arrange(flights_df, desc(arr_delay)) # descending order
# flights[order(flights$arr_delay, decreasing = TRUE), ] # base R
# flights[order(-flights$arr_delay), ]
# Year, Month, DayOfWeek 열을 추출
select(flights_df, year, month, day)
# Year부터 DayOfWeek를 제외한 나머지 열을 추출
select(flights_df, -(year:day))
distinct(flights_df, day)
# unique(flights_df$day)
distinct(flights_df, month, day) # 복합키
mutate(flights_df,
gain = arr_delay-dep_delay,
speed = distance/air_time*60,
# 신규열gain을 gain_per_hour의 계산에 바로사용, transform()에서는 안됨
gain_per_hour = gain/(air_time/60)
)
mutate(flights_df,
gain = arr_delay-dep_delay
) %>% select(year:day, gain)
# 평균 출발지연시간 계산
summarise(flights_df,
delay = mean(dep_delay, na.rm = TRUE))
sample_n(flights, 10) # 샘플 수
sample_frac(flights, 0.01) # 샘플 비율
by_tailnum <- group_by(flights_df, tailnum)
delay <- summarise(by_tailnum,
count = n(),
dist = mean(distance, na.rm=T),
delay = mean(arr_delay, na.rm=T))
delay <- filter(delay, count > 20, dist < 2000)
# delay is only slightly related to the average distance flown by a plane
ggplot(delay, aes(dist, delay)) +
geom_point(aes(size=count), alpha=1/2) +
geom_smooth() +
scale_size_area()
# 각 목적지별 비행기No 및 항공기 편수
destinations <- group_by(flights_df, dest)
summarise(destinations,
planes = n_distinct(tailnum),
flights = n()
)
# 일별(복합키) 편수
daily <- group_by(flights, year, month, day)
(per_day <- summarise(daily, flights = n())) 