RL Intro.
DAVID SILVER
Richard S. Sutton
인공지능 응용-중앙대강의
https://seunghan96.github.io/rl/01.Reinforcement_Learning_intro/
https://hiddenbeginner.github.io/Deep-Reinforcement-Learnings/book/Chapter1/1-sequential-decision-making-problems.html
https://m.blog.naver.com/ydot/222090117694
RL 이란 ?
Reward로부터 학습 (지도: label정답, 비지도: 데이터자체)
주어진 상황이 있을 때, “가장 좋은 행동” 찾기 위한 학습하는 것
“주어진 상황(State)에서, 받을 수 있는 보상(Reward)를 극대화 하는 행동(Action)을 선택하도록!”
the maximisation of expected cumulative reward
어떤 문제를 풀것인가?
고전 강화학습
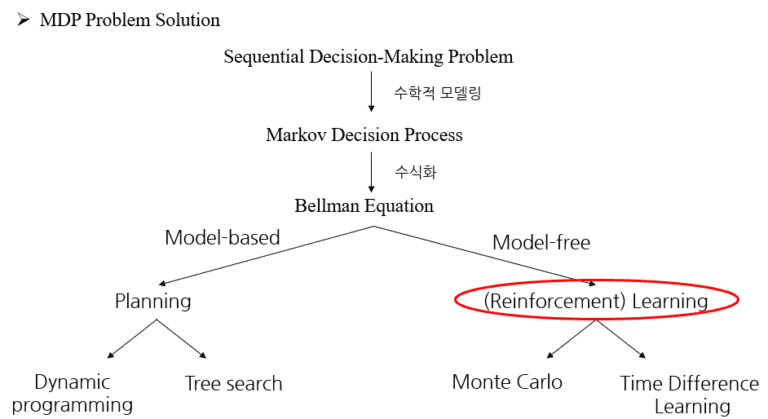
SDP (Sequential Decision Making Problem, 순차적 행동결정 문제)
주식 포트폴리오 관리: 정해진 예산으로 어떤 주식을 얼마큼 들고 있을지 선택의 연속.
운전 : 매순간 가속/제동의 결정은 이후의 결정에 영향을 준다.
게임 : 게임자체가 잘게 쪼게진 선택의 연속이며, 각 선택에 따라 이후 상황이 변하기 때문에 최선의 선택이 필요
MDP (Markov Decision Process, SDP의 수학적 표현)
=> Agent가 최적의 Policy를 얻었다는 것 = Sequential Decision Making 문제를 풀었다
MDP를 계산(planning)으로 푸는 방법 : DP (Dynamic Programming)
환경에 대한 모든정보(model)를 알고, 가장좋은 정책을 “계산”
MDP를 학습(learning)으로 푸는 방법 : RL (Reinforcement Learning) – SALSA, Q-learning
환경과 상호작용을 통해 가장좋은 정책을 “학습”
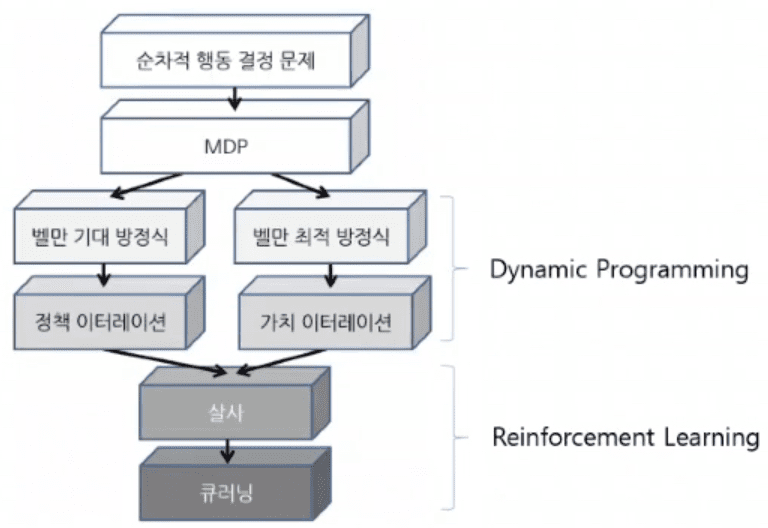
딥러닝 결합
상태공간이 크고, 차원이 높을때 사용하는 방법 : Function Approximation
복잡하고 어려운 문제 (ex. 바둑) : Deep RL
RL 속성
- 1) 정답을 모른다! (Unsupervsied) => 대신, 특정 행동에 대한 reward & 다음 state가 주어짐
- 2) 현재의 의사결정이, 미래의 의사결정에 영향을 미친다!
- 3) 문제의 구조를 모른다 => 처음부터 행동에 대한 모든 보상들을 알고 시작하는 것이 아니다.
- 4) Delayed Reward => 받게되는 reward의 가치는 시간에 따라 다를 수 있다.
Learning
- Enviroment는 맨처음에는 unknown
- Agnet는 Enviroment와 interact하면서, Policy를 improve해 나간다.
cf. Planning = search, reasoning, introspection, pondering, thought….
- Envrioment의 model 는 known
- Agent는 외부상호작용없이 model을 계산해나가면서(state가 너무크면 계산은 안된다), Policy를 improve해 나간다.
RL의 구성요소

- 1 ) Agent (에이전트) : 상태를 관찰, 행동을 선택하는 주체
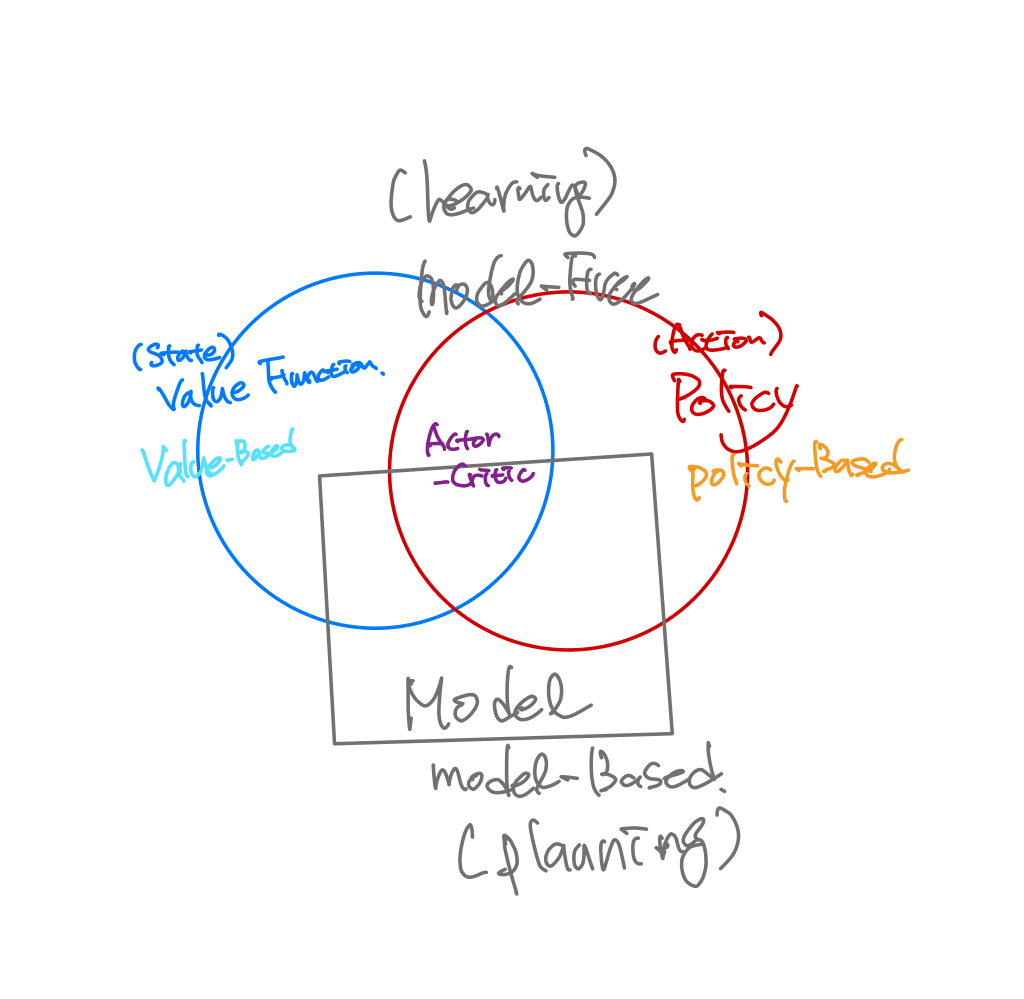
agent의 3요소 : 정책/가치/모델
– Policy (정책, π) : 주어진 환경에서, Agent가 어떠한 action을 해야할지
( 결정론적 a = π(s) 또는
확률론적 π(a | s) = Pr(At =a | St =s))
– Value function : Agent가 action을 했을때, 그 상태/행동이 얼마나 좋은지, 미래Reward의 예측
Vπ(s)=Eπ[R(s0)+γR(s1)+γ2R(s2)+…∣s t=s,π]
– Model : Agent가 환경(상태변환확률)에 대해 알고 있는가 (planning vs learning)
다음상태 P를예측, Pss’a= Pr( St+1 = s’ | St = s , A= a]
다음 Reward를예측, Rsa = E (Rt+1 | St = s, At =a]
Agent 구분
– Value-Based
– Policy Based
-Actor Critic
- 2 ) Environment (환경) : Agent가 속해 있는 상황 => ( 단지 현재 시점의 상황 뿐만 아니라, 전체적인 상황을 의미)
- 3 ) State (상태) : 현재 Agent가 속해 있는 상태의 정보
- 4 ) Action (행동, A) : 현재 state에서 Agent가 하는 행동
- 5 ) Reward (보상, R) : Agent가 action을 했을 때 받게 되는 보상 (장기적인 관점)
과정 Summary
- Agent(에이전트)가 Environment(환경)에서 자신의 state(상태)를 관찰하고,
특정 기준(“가치 함수”)에 따라 행동을 선택한다.
여기서 “가치 함수”는, 현재 상태에서 미래에 받을 것으로 “기대”되는 Reward의 (discounted) 합을 의미한다 - 그리고 선택한 행동을 수행하면, 다음 state으로 넘어감과 함께 Reward를 받는다.
- 여기서 받는 Reward를 통해, Agent는 가지고 있는 정보를 update한다”
(3) AlgorithmPermalink
매 time step t 마다,
- 1 ) agent는 액션 (action)을 한다 (At )
- 2 ) 행동에 따른 결과를 확인 (observation)한다
- 3 ) 이 행동에 따른 보상 (reward)을 받는다 ( Rt )
3. Value function & Q-Value functionPermalink
Value function vs Q-value function?
- Value function : 액션(action) 고려 X
- Q-value function : 액션(action) 고려 O
(1) Value function ( 액션 고려 X )Permalink
‘value’는, 단기적인 Reward뿐만이 아닌라, “장기적인 관점”에서 할인율(γγ)를 통해 discount된 미래에 받게 될 보상까지 고려한 reward를 의미한다.
이를 식으로 나타내면 다음과 같다.
- Vπ(s)=E[R(s0)+γR(s1)+γ2R(s2)+…∣s0=s,π]
- “현재 상태 s에서 정책 π 에 따라 행동 했을 때 기대되는 보상” 으로 해석
Value function이 “(1) 현재의 상태과 (2) 정책”이 주어졌을 때의 Reward 관련 함수
(2) Q-Value function ( 액션 고려 O )Permalink
Q-value function은 “(1) 현재의 상태, (2) 정책 그리고 (3) 현재의 상태에서 취할 행동”이 주어졌을 때의 Reward 관련된 함수이다.
이를 식으로 나타내면 다음과 같다.
- Qπ(s,a)=E[R(s0,a0)+γR(s1,a1)+γ2R(s2,a2)+….∣s0=s,a0=a,π]
4. Kinds of Reinforcement Learning
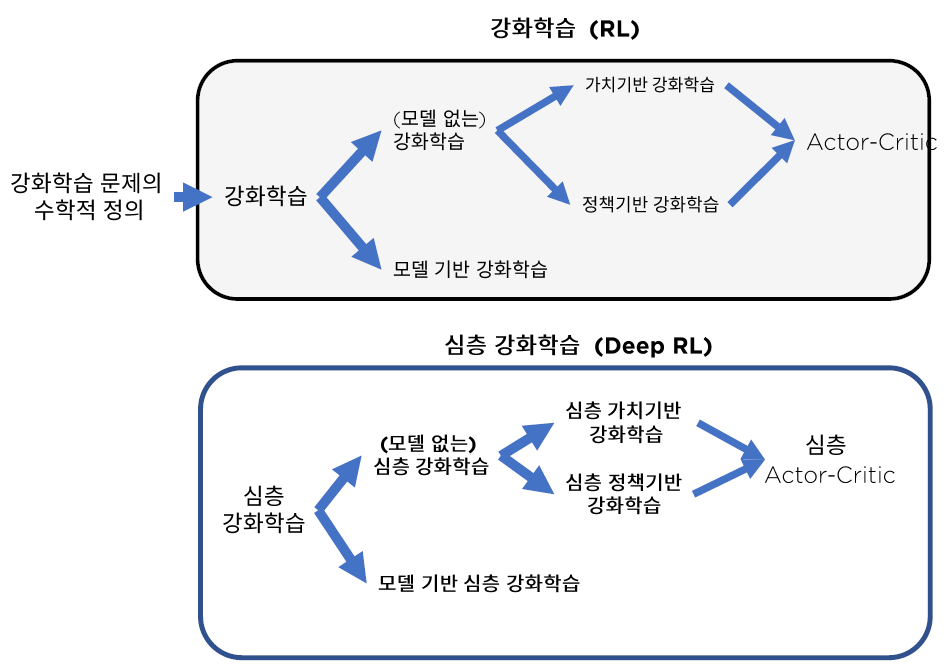
- 1 ) Model based :
- agent가 존재하는 environment를 modeling한 것
- 2 ) Policy based agent :
- value function 없이, 오직 policy와 model만으로 구성
- 3 ) Value based agent :
- policy 없이, 오직 value function과 model만으로 구성
- 4 ) Model based agent & Model Free agent :
- model에 대한 정보가 곧 state transition의 정보
- 5 ) Actor Critic :
- policy + value function + model 모두 사용
5. Summary
- RL = 미래까지 고려한 reward 극대화하는 policy 찾기
- RL의 구성 요소 : agent, environment, state, action, reward, policy
- Agent의 행동 순서 :
- (1) 행동 – (2) 상태 확인 – (3) 보상 받기
- Value function vs Q-value function
- Value ) 액션 고려 X ( state + policy )
Vπ(s)=E[R(s0)+γR(s1)+γ2R(s2)+…∣s0=s,π]Vπ(s)=E[R(s0)+γR(s1)+γ2R(s2)+…∣s0=s,π]. - Q-value ) 액션 고려 O ( state + policy + action )
Qπ(s,a)=E[R(s0,a0)+γR(s1,a1)+….∣s0=s,a0=a,π]Qπ(s,a)=E[R(s0,a0)+γR(s1,a1)+….∣s0=s,a0=a,π].
- Value ) 액션 고려 X ( state + policy )
