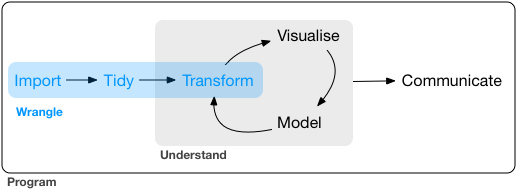
2. wrangle-intro
http://r4ds.had.co.nz/wrangle-intro.html
tibbles
개요
data.frame 대신에 그것의 변종인 tibbles
vignette("tibble")
tibble만들기
data frame 에서 tibble로 변환
as_tibble(iris) %>% str() tbl_df(iris) %>% str()
반대로 tibble이 안 먹는 old function이 있는 경우
as.data.frame(tb)
새로 만들기
tibble( a = lubridate::now() + runif(1e1) * 86400, b = lubridate::today()+ runif(1e1) * 30, c = 1:1e1, d = runif(1e1), e = sample(letters, 1e1, replace = TRUE) )
data.frame과 차이점
1. printing
nycflights13::flights %>% print(n = 16, width = Inf)
2. subsetting
options(digits=2) #options(scipen=666) df <- tibble( x = runif(5) , y = rnorm(5)) df$x; df[["x"]]; df[[1]] df %>% .$x ; df %>% .[["x"]]; df %>% .[[1]]
data import
you’ll learn how to get your data from disk and into R.
We’ll focus on plain-text rectangular formats, but will give you pointers to packages that help with other types of data.
| read.table() | 구분자로 공백문자, 소수점으로 도트 문자 사용한 파일 |
| read.delim() | 구분자로 Any delimiter (tab문자), 소수점으로 도트 문자 사용한 파일 |
| read.delim2() | 구분자로 tab문자, 소수점으로 콤마 문자 사용한 파일 |
| read.csv() | 구분자로 콤마문자, 소수점으로 도트 문자 사용한 파일 |
| read.csv2() | 구분자로 세미콜론 문자, 소수점으로 콤마 문자 사용한 파일 |
| read_tsv() | 구분자로 tab문자 |
tidy data
a consistent way of storing your data that makes transformation, visualisation, and modelling easier.

data transformation
-
Relational data will give you tools for working with multiple interrelated datasets.
-
Strings will introduce regular expressions, a powerful tool for manipulating strings.
-
Factors are how R stores categorical data.
They are used when a variable has a fixed set of possible values, or when you want to use a non-alphabetical ordering of a string. -
Dates and times will give you the key tools for working with dates and date-times.
