reshape2
https://www.rdocumentation.org/packages/data.table/versions/1.10.4/topics/dcast.data.table
\http://seananderson.ca/2013/10/19/reshape.html
http://had.co.nz/reshape/
Wickham, H. (2007). Reshaping data with the reshape package. 21(12):1–20
https://cran.r-project.org/web/packages/reshape2/reshape2.pdf
http://www.cookbook-r.com/Manipulating_data/Converting_data_between_wide_and_long_format/
reshape2: a reboot of the reshape package
주요 함수
금속을 melt 녹여서 long하게 만들고, cast 주조하여 wide한 주형을 만드는 것 처럼,
DATA
# air quality 데이터셋 탐색 - Wide 형 TEMP_airquality <- airquality names(TEMP_airquality) <- tolower(names(TEMP_airquality)) # 편의를 위해 Header를 소문자로 통일
> head(airquality)
ozone solar.r wind temp month day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
> tail(airquality)
ozone solar.r wind temp month day
148 14 20 16.6 63 9 25
149 30 193 6.9 70 9 26
150 NA 145 13.2 77 9 27
151 14 191 14.3 75 9 28
152 18 131 8.0 76 9 29
153 20 223 11.5 68 9 30
melt()
Wide- to Long (wide-format data을 long-format data로 melt)
=> id.vars에 지정하면 해당 variable로 그룹화
=> default로 numeric값을 가진 모든 열을 variables과 value로 녹인다)
data를 melt하려면 id역할(variable, 카테고리) 과 measure역할(value, 측정값)로 변수를 나누어 지정
variable 값 선택
myData <-TEMP_airquality
m01 <- melt(myData, id.vars=c("month", "day"))
m02 <- melt(myData, id.vars=c("month", "day"), measure.vars=c("ozone", "wind" ))
m01 %>% nrow()는 612 개 ( myData 153개 * 변수수 4개 ( ozone, solar.r, wind, temp))
m02 %>% nrow()는 306 개 ( myData 153개 * 변수수 2개 ( ozone, wind를 제외한 solar.r, temp))
> m01
month day variable value
1 5 1 ozone 41.0
...
154 5 1 solar.r 190.0
...
307 5 1 wind 7.4
...
612 9 30 temp 68.0
> m02
month day variable value
1 5 1 ozone 41.0
...
306 9 30 wind 11.5
variable과 value에 컬럼명 지정
m03 <- melt(myData, id.vars=c("month", "day"),
variable.name="climate_variable", value.name="climate_value")
> m03
month day climate_variable climate_value
1 5 1 ozone 41.0
2 5 2 ozone 36.0
....
612 9 30 temp 68.0
cast()
Long- to wide (long-format data를 wide-format data로 cast)
* reshape2::dcast 보다 데용량 데이터에 효율적인 dcast.data.table
To melt or cast data.tables, it is not necessary to load reshape2 anymore.
melt에 비해 덜 직관적이지만 형식은 cast( dataframe, 열방향+열방향 ~ 행방향+행방향, 함수)
dcast (return: data.frame) , acast (return: vector, matrix, array)
| dcast( data, formula, fun.aggregate = NULL, sep = “_”, …, margins = NULL, subset = NULL, fill = NULL, drop = TRUE, value.var = guess(data), verbose = getOption(“datatable.verbose”) |
formula로 data의 모양을 나타낸다. Id.vars ~ measure.vars
(Excel pivot과 비교하면, Id.vars : 행레이블, measure.vars : 값, 모든 variable name : 열레이블)
value.var : column명
Name of the column whose values will be filled to cast.
Function ‘guess()’ tries to, well, guess this column automatically, if none is provided.
NEW: it is now possible to cast multiple value.var columns simultaneously.
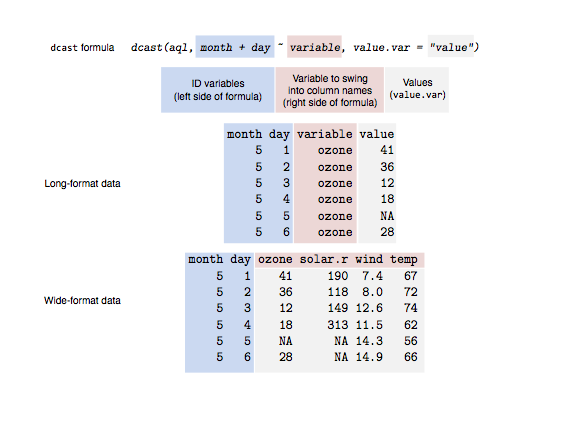
예제 데이터 : Long format
aql00 <- melt.data.table(dt_mydata, id.vars = c("month", "day"), measure.vars = c("ozone", "solar.r", "wind", "temp"))
1) 하나의 Cell에 한 개의 Value를 가질때 : 월, 일별 cast
aqw1 <- dcast(aql00, month + day ~ variable)
cf. long format 데이터를 피벗을 통해 cast함.
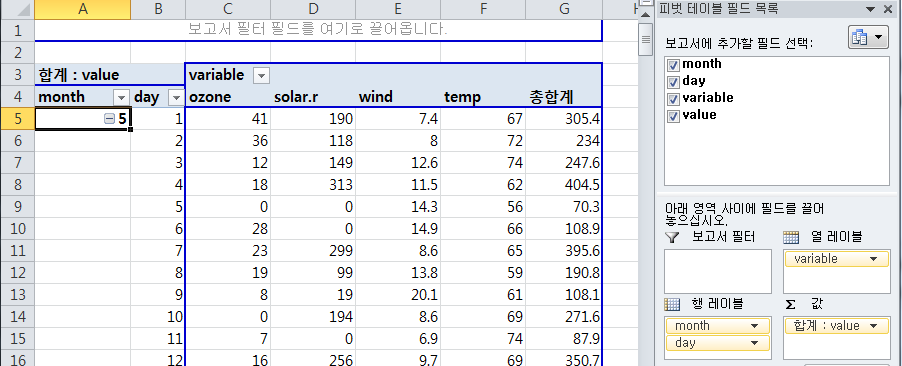
2) 하나의 Cell에 여러 Value를 가질때 : 월별 cast
2-1> 잘못된 예 : aggregate방법 미정의
하나의 Cell 에 하나의 value 이상을 가지도록 cast하는 것.
기대와 달리, day의 합계 값(length)이 출력된다. => dcast가 aggregate할 방법(mean, median, sum)을 정의하지 않음
aqw2 <- dcast(aql00, month ~ variable)
Aggregate function missing, defaulting to 'length'
> aqw2 month ozone solar.r wind temp 1: 5 31 31 31 31 2: 6 30 30 30 30 3: 7 31 31 31 31 4: 8 31 31 31 31 5: 9 30 30 30 30
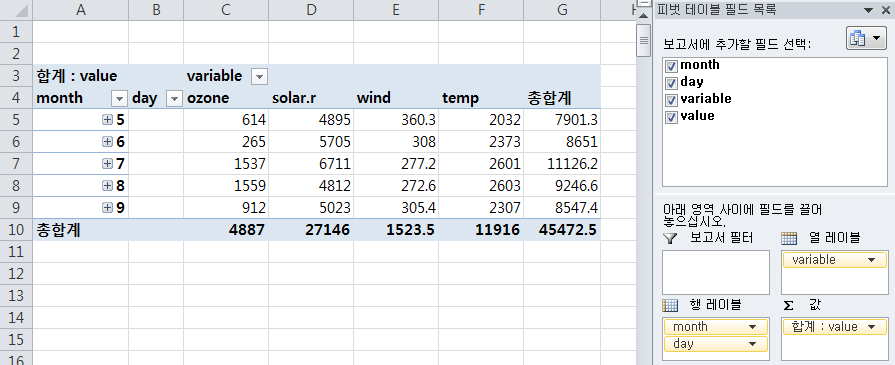
2-1> 올바른 예
합계
aqw2 <- dcast(aql00, month ~ variable, fun.aggregate=sum)
> aqw2 month ozone solar.r wind temp 1: 5 614 4895 360.3 2032 2: 6 265 5705 308.0 2373 3: 7 1537 6711 277.2 2601 4: 8 1559 4812 272.6 2603 5: 9 912 5023 305.4 2307
cf. long format 데이터를 피벗을 통해 cast할때, 값을 합계함.
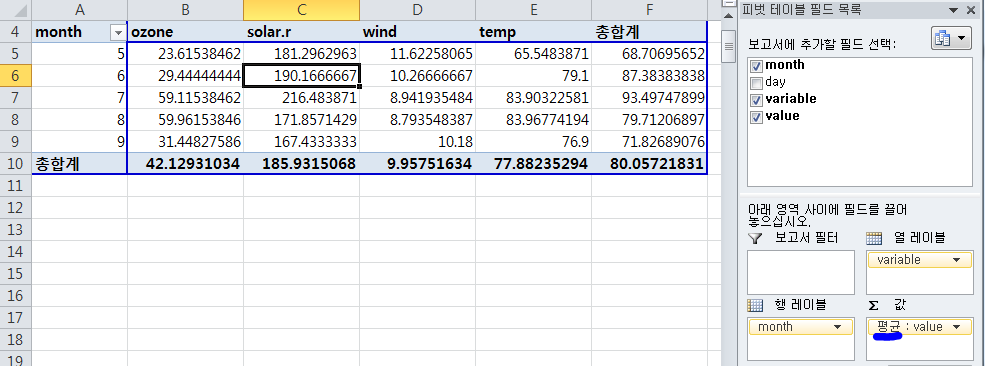
평균
aqw2 <- dcast(aql00, month ~ variable, fun.aggregate = mean, na.rm = TRUE)
> aqw2 month ozone solar.r wind temp 1 5 23.61538 181.2963 11.622581 65.54839 2 6 29.44444 190.1667 10.266667 79.10000 3 7 59.11538 216.4839 8.941935 83.90323 4 8 59.96154 171.8571 8.793548 83.96774 5 9 31.44828 167.4333 10.180000 76.90000
cf.. long format 데이터를 피벗을 통해 cast할때, 값을 평균함.
overview
tidy data 개념을 기반으로 한 reshape, dplyr
help(package = "reshape2")
reshape2에서 달라진 점
- cast()가 Output type에 따라, dataframe을 만드는 dcast()와 matrix/array들 만드는 acast()로 분리됨
- multidimensional margins이 가능함. (grand_row 와 grand_co가 없어지고)
- plyr를 쓰면 더 좋은 cast연산자 aggregation함수로부터 리턴받는 여러값은 삭제됨
- a new cast syntax which allows you to reshape based on functions of variables
(based on the same underlying syntax as plyr) - better development practices like namespaces and tests.
reshape2: multiple results of aggregation function?
http://stackoverflow.com/questions/21477040/reshape2-multiple-results-of-aggregation-function
데이터 형식 wide & long
Wide data 각 variable이 하나의 열로 존재하는 데이터
# ozone wind temp # 1 23.62 11.623 65.55 # 2 29.44 10.267 79.10 # 3 59.12 8.942 83.90 # 4 59.96 8.794 83.97
Long-format data은 실질적으로 wide-format 보다는 흔히 볼수 있는 데이터 형태로,
variable 과 해당 variable 의 value 로 구성된 데이터
ggplot2 팩키지는 분석을 위해 long-format data 사용 (엄밀히, tidy data),
plyr팩키지는 분석을 위해 long-format data사용
대부분의 모데링함수(예, lm(), glm(),gam()…)는 분석을 위해 long-format data사용
# variable value # 1 ozone 23.615 # 2 ozone 29.444 # 3 ozone 59.115 # 4 ozone 59.962 # 5 wind 11.623 # 6 wind 10.267 # 7 wind 8.942 # 8 wind 8.794 # 9 temp 65.548 # 10 temp 79.100 # 11 temp 83.903 # 12 temp 83.968
