OpenMMLab :: MMDetection
https://github.com/open-mmlab/mmdetection
[MMDetection] 논문 정리 및 모델 구현
MMDetection이란
Object detection과 Instance segmentation을 다루는 다양한 모델을 하나의 toolbox로 구현한 일종의 플랫폼이다.
pytorch로 작성되어 있음.
주요 특징
1) Modular design
: 모델이 모듈화 되어있어 사용자 제작이 간편하다.
2) Supported Frameworks
: 여러 프레임워크를 지원
3) High efficiency
: 모든 box와 mask 연산은 GPU에서 동작하여, 다른 플랫폼 보다 학습속도가 빠르다.
cf. Detectron(facebook), maskrcnn-benchmark, SimpleDet 등
4) State of the art 2018년
: COCO Detection Challenge 에서 우승한 MMDet team의 코드를 토대로 만들었다.
다양한 유형의 Dataset(CustomDataset, COCO, Pascal VOC,Kitti, WIDERFace…) 변환클래스를 통해 지원
Supported Framworks
MMDetection 안에 구성된 모델들이다.
- 2.1 Single-state Method
- SSD
- RetinaNet
- GHM
- FCOS
- FSAF
- 2.2 Two-state Methods
- Fast R-CNN
- Faster R-CNN
- R-FCN
- Mask R-CNN
- Grid R-CNN
- Mask Scoring R-CNN
- Double-Head R-CNN
- 2.3 Multi-state Methods
- Cascade R-CNN
- Hybrid Task Cascade : 가장 높은 성능을 보인 모델
- 2.4 General Modules and Methods
- Mixed Precision Training
- Soft NMS
- OHEM
- DCN
- DCNv2
- Train from Scratch
- ScratchDet
- M2Det : 2018년, 더 효율적인 피처 피라미드를 구성하기 위한 새로운 피처 피라미드 네크워크
- GCNet
- Generalized Attention
- SyncBN
- Group Normalization
- Weight Standardization
- HRNet : 2019년, 고해상도 이미지를 학습하는 데 집중한 새로운 뼈대(backbone)이다.
- Guided Anchoring
- Libra R-CNN
Architecture
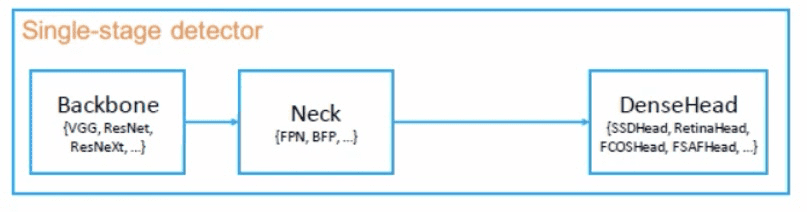
1. Model Representation
| 1Stage (O.S.D) | Backbone | Backbone이란, Feature Extractor (Image –> FeatureMap) 입력 img를 FeatureMap(특징맵)으로 변형시켜주는 부분 ex> 마지막 FC layer을 제외한 ResNet50 |
| Neck | backbone과 head를 연결짓는 부분으로, 날것의 FeatureMap에 Refinement(정제)/ Reconfiguration(재구성)을 한다. (Head가 featureMap을 보다 잘 해석할수 있도록 정제작업) ex> FPN(Feature Pyramid Network) | |
| DenseHead | FeatureMap의 dense locations 수행하는 부분 Object위치와 Classification을 처리하는 부분 (= AnchorHead / AnchorFreeHead) |
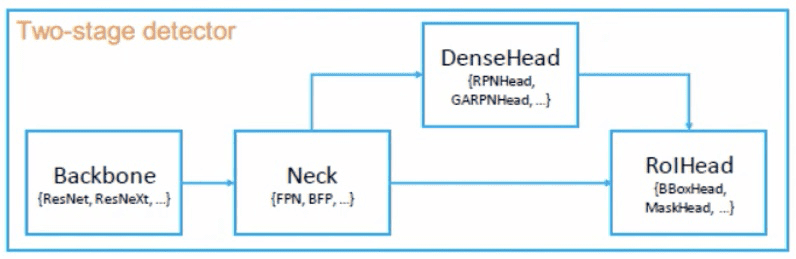
| 2Stage (RPN) | RoIExtractor | 단일, 다중 FeatureMap으로부터 RoI-wise 특징을 추출하는 부분 |
| RoIHead | RoI 특징을 입력으로 받고, RoI-wise task-specific 예측을 하는 부분 (= BBoxHead / MaskHead) bounding box 분류/회기나 mask예측이 이에 해당한다. |
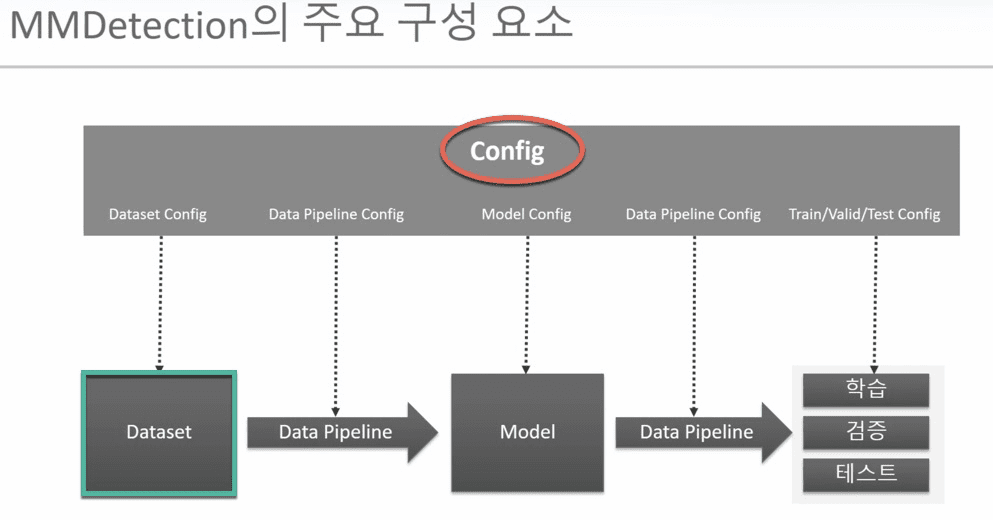
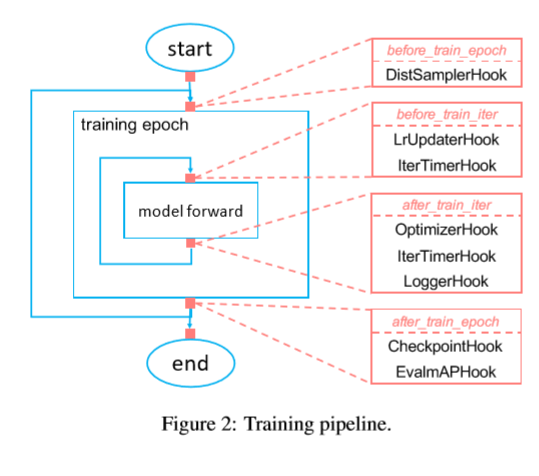
2. Training Pipeline
아래 Training PipLine을 train epoch과 train iter로 쪼개어, 사용자가 원하는 대로 hook설정을 변경가능하도록 함.
Benchmarks
1 실험 세팅
| Dataset | MS COCO 2017 (도전적이고 널리 쓰이기 데이터셋이기 때문) |
| 구현상세 | (1) 이미지는 최대 1333 x 800 로 resize 됨 (2) GPU 당 2개 이미지를 할당하여 배치사이즈 16에서 학습시켰다. (V100 8GPU사용) (3) training schedule은 Detectron과 같다. 1x, 2x는 각각 12, 24 epoch을 의미하고 20e는 cacade에서 20 epoch을 의미한다. |
| Evaluation metrics | COCO 데이터셋의 표준 evaluation metric을 이용 , 0.5:0.95 의 IoU threshold를 적용 RPN(Region proposal network)는 AR(Average Recall)로 평가 Detection결과는 mAP로 평가 |
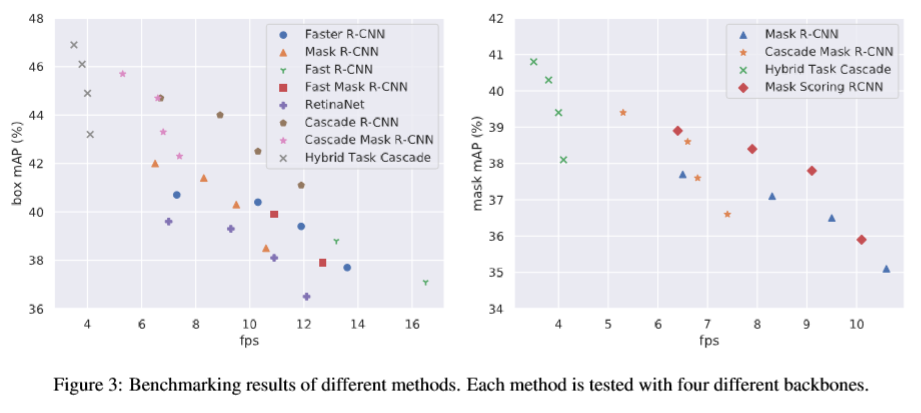
2. Results
아래 결과처럼 Hybrid Task Cascade 모델이 가장 성능이 좋았다.
그 외에 Mixed precision training이 가능하여서 GPU 메모리를 아끼면서 효율적으로 작업할 수 있다고 하였고,
Multi-node scalability 실험을 해본 결과 이론상 linear하게 증가하는 것과 비슷?하게 실제도 증가하였다고 한다.
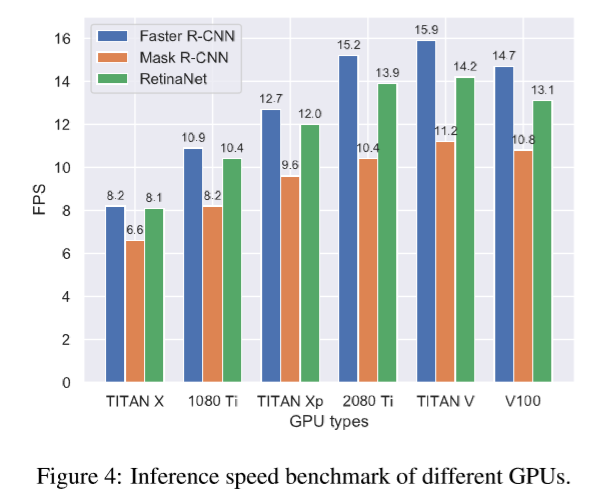
광범위한 연구들
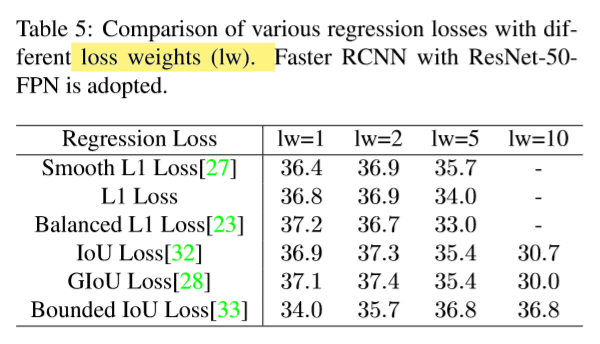
1 Regression Loss
여러 가지 loss가 있고,
loss weight(lw)을 증가시켜가며
performance를 비교했다.
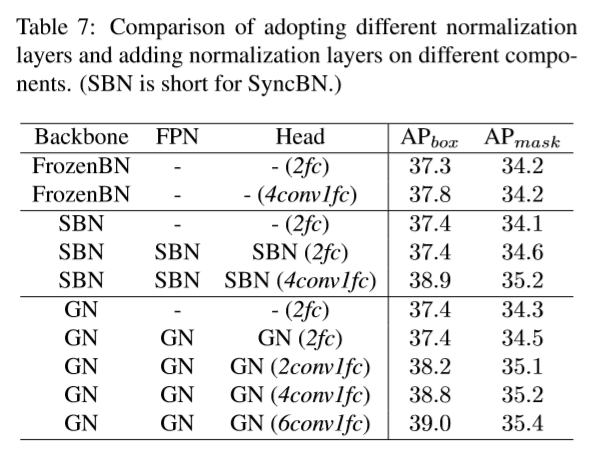
2 Normalization Layer
Normalization (FrozenBN/ SyncBN/ GN)를 적용했는데,
(1) backbone의 BN을 바꿨을 때는 성능향상이 없었고,
(2) FPN과 bbox/mask head에 더해도 별다른 이점이 없었으며,
(3) bbox head를 2fc에서 4conv-1fc로 바꾸고,
normalization을 추가하면 1.5%의 성능향상을 보였고,
(4) 더 많은 conv 층이 bbox head에 있으면 더 좋은 성능을 보였다.
3 Training Scales
Training scale에 관해, 입력 이미지의 사이즈를 어떻게 받을 것인가에 대한 논의가 없었다.
이 논문은 이미지를 선택된 스케일로 resize 하여 실험해 보았다.
그 방법은 2가지가 있는데
(1) ‘value’ mode : 스케일 셋을 미리 정해놓고, 임의로 스케일을 선택하는 것이다.
(2) ‘range’ mode : 스케일 범위를 미리 정해놓고, 최솟값 최대값 사이의 스케일을 임의로 만드는 것이다.
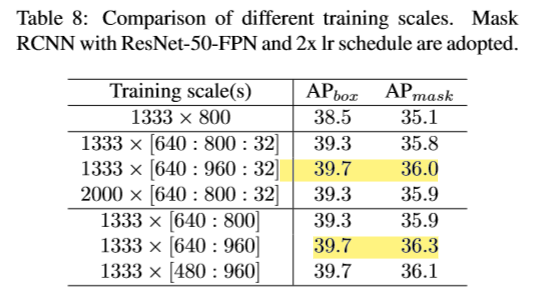
결과를 보면, range 모드가 value 모드보다 비슷하거나 아주 조금 더 좋은 성능을 보였다.
4 Other Hyper-parameters
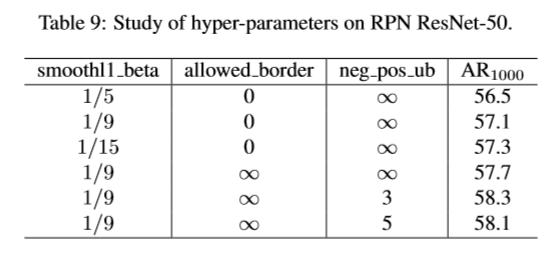
간단히 smmothl1_beta와, allowed_border를 소개했다.
그리고 아직 결론 없이 부록을 보여주며 끝난다.