MMDetection-kitty
Published by onesixx on
1. sixx_make_cfg.py

ROOT_DIR = '/home/oschung_skcc/git'
import os
import os.path as osp
WORK_DIR = osp.dirname( osp.dirname(osp.realpath(__file__)) )
from mmcv import Config
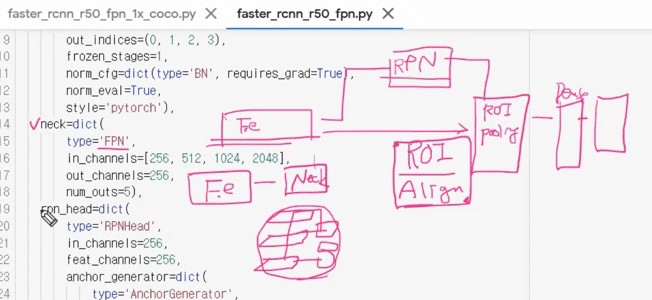
cfg = Config.fromfile(osp.join(ROOT_DIR, "mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py"))
# print(cfg.pretty_text)
config_file = osp.join(WORK_DIR, 'configs/faster_rcnn_r50_fpn_1x_tidy.py')
checkpoint_file = osp.join(WORK_DIR, 'checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth')
from mmdet.apis import set_random_seed
# dataset에 대한 환경 파라미터 수정.
cfg.dataset_type = 'KittyTinyDataset' # 'CocoDataset'
cfg.data_root = WORK_DIR # 'data/coco/'
###---sixx---:: DATA
# train, val, test dataset에 대한
# type, WORK_DIR, ann_file, img_prefix 환경 파라미터 수정.
cfg.data.train.type = 'KittyTinyDataset' # 'CocoDataset'
cfg.data.train.data_root = WORK_DIR
cfg.data.train.ann_file = 'data/train.txt' # 'data/coco/annotations/instances_train2017.json'
cfg.data.train.img_prefix = 'data/image_2' # 'data/coco/train2017/'
cfg.data.val.type = 'KittyTinyDataset'
cfg.data.val.data_root = WORK_DIR
cfg.data.val.ann_file = 'data/valid.txt'
cfg.data.val.img_prefix = 'data/image_2'
cfg.data.test.type = 'KittyTinyDataset'
cfg.data.test.data_root = WORK_DIR
cfg.data.test.ann_file = 'data/valid.txt'
cfg.data.test.img_prefix = 'data/image_2'
###---sixx--::: train_pipeline
###---sixx--::: test_pipeline
###---sixx---:: MODEL
cfg.model.roi_head.bbox_head.num_classes = 4 # class의 80 갯수 수정.
cfg.load_from = checkpoint_file # pretrained 모델 (경로확인)
cfg.work_dir = osp.join(WORK_DIR, 'tutorial_exps') # 학습 weight 파일로 로그를 저장하기 위한 디렉토리 설정.
# schedule 이나 default_runtime의 설정값 수정
# 학습율 변경 환경 파라미터 설정.
cfg.optimizer.lr = 0.02 / 8 # 0.02
cfg.lr_config.warmup = None # linear
cfg.log_config.interval = 10
# config 수행 시마다 policy값이 없어지는 bug로 인하여 설정.
cfg.lr_config.policy = 'step'
# Change the evaluation metric since we use customized dataset.
cfg.evaluation.metric = 'mAP' # bbox
# We can set the evaluation interval to reduce the evaluation times
cfg.evaluation.interval = 12 # 1
# We can set the checkpoint saving interval to reduce the storage cost
cfg.checkpoint_config.interval = 12 #1
# Set seed thus the results are more reproducible
cfg.seed = 0
set_random_seed(0, deterministic=False)
cfg.gpu_ids = range(1)
# print(f'Config:\
{cfg.pretty_text}')
###############################################################################
with open (config_file, 'w') as f:
print(cfg.pretty_text, file=f)
import datetime
print(f"---created custom config file by sixx on {datetime.datetime.now()}")
print(f"{cfg.dataset_type} :: {osp.relpath(config_file)}")
2. sixx_middle_dataset
RROOT_DIR = '/home/oschung_skcc/git'
import os
import os.path as osp
WORK_DIR = os.path.dirname( os.path.dirname(os.path.realpath(__file__)) ) # 'mymm/kitty_tiny'
DATA_DIR = osp.join(WORK_DIR, 'data')
IMG_PREFIX = 'image_2'
ANN_PREFIX = 'label_2'
import sys
sys.path.append('/home/oschung_skcc/git/mmdetection') # ( os.path.dirname(os.path.abspath(__file__)) )
from mmdet.datasets.builder import DATASETS
from mmdet.datasets.custom import CustomDataset
import mmcv
import cv2
import numpy as np
import pandas as pd
# annotation xml 파일 파싱해서 bbox정보 추출
def get_bboxes_from_xml(annPath):
annLines = mmcv.list_from_file(annPath)
content = [line.strip().split(' ') for line in annLines]
bbox_names = [x[0] for x in content]
bboxes = [ [float(info) for info in x[4:8]] for x in content]
return bbox_names, bboxes
# imgFileNm = '000006'
# ann_file = '/home/oschung_skcc/git/mymm/kitty_tiny/data/label_2/000006.txt'
@DATASETS.register_module(force=True)
class KittyTinyDataset(CustomDataset):
CLASSES = ('Car', 'Truck', 'Pedestrian', 'Cyclist')
def load_annotations(self, ann_file):
# mmdetection 프레임웍이 Config에서 ann_file(path)인자를 찾아 파라미터로 사용.
cat2label = {k:i for i, k in enumerate(self.CLASSES)}
annFileNm_list = mmcv.list_from_file(self.ann_file)
data_info = []
for imgFileNm in annFileNm_list:
if imgFileNm is None:
continue
### IMAGE metadata
imgBaseNm = str(imgFileNm)+'.jpeg'
imgPath = osp.join(DATA_DIR, IMG_PREFIX, imgBaseNm)
image = cv2.imread(imgPath)
height, width = image.shape[:2]
img_metaData = {
'filename': imgBaseNm,
'width': width,
'height': height
}
### Annotation metadata
annBaseNm = str(imgFileNm)+'.txt'
annPath = osp.join(DATA_DIR, ANN_PREFIX, annBaseNm)
if not osp.exists(annPath):
continue
elif os.stat(annPath).st_size==0:
continue
gt_bboxes = []
gt_labels = []
gt_bboxes_ignore = []
gt_labels_ignore = []
bbox_names, bboxes = get_bboxes_from_xml(annPath)
for bboxNm, bbox in zip(bbox_names, bboxes):
if bboxNm in cat2label:
gt_bboxes.append(bbox)
gt_labels.append(cat2label[bboxNm])
else:
gt_bboxes_ignore.append(bbox)
gt_labels_ignore.append(-1)
ann_metaData = {
'bboxes': np.array(gt_bboxes, dtype=np.float32).reshape(-1, 4),
'labels': np.array(gt_labels, dtype=np.c