mmdet train in sixxtools
~/my/git/mmdetection/tools ==> sixxtools
$ python sixxtools/train.py \\ "sixxconfigs/cascade_rcnn_r50_fpn_1x_coco.py" \\ --work-dir "work_dirs/ttt"
epoch_69.pth (PyTorch Model)이 생성된다.
/home/oschung_skcc/my/git/mmdetection/mmdet/utils/setup_env.py:38:
UserWarning: Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
warnings.warn(
/home/oschung_skcc/my/git/mmdetection/mmdet/utils/setup_env.py:48: UserWarning: Setting MKL_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
warnings.warn(
2022-12-05 15:47:21,645 - mmdet - INFO - Distributed training: False
2022-12-05 15:47:21,646 - mmdet - INFO - Set random seed to 255440651, deterministic: False
2022-12-05 15:47:21,646 - mmdet - INFO - sixx >>> detector model::------------------------------------------------------------
2022-12-05 15:47:22,278 - mmdet - INFO - initialize ResNet with init_cfg {'type': 'Pretrained', 'checkpoint': 'torchvision://resnet50'}
2022-12-05 15:47:22,279 - mmcv - INFO - load model from: torchvision://resnet50
2022-12-05 15:47:22,279 - mmcv - INFO - load checkpoint from torchvision path: torchvision://resnet50
2022-12-05 15:47:22,360 - mmcv - WARNING - The model and loaded state dict do not match exactly
unexpected key in source state_dict: fc.weight, fc.bias
2022-12-05 15:47:22,383 - mmdet - INFO - initialize FPN with init_cfg {'type': 'Xavier', 'layer': 'Conv2d', 'distribution': 'uniform'}
2022-12-05 15:47:22,409 - mmdet - INFO - initialize RPNHead with init_cfg {'type': 'Normal', 'layer': 'Conv2d', 'std': 0.01}
2022-12-05 15:47:22,414 - mmdet - INFO - initialize Shared2FCBBoxHead with init_cfg [{'type': 'Normal', 'std': 0.01, 'override': {'name': 'fc_cls'}}, {'type': 'Normal', 'std': 0.001, 'override': {'name': 'fc_reg'}}, {'type': 'Xavier', 'distribution': 'uniform', 'override': [{'name': 'shared_fcs'}, {'name': 'cls_fcs'}, {'name': 'reg_fcs'}]}]
2022-12-05 15:47:22,633 - mmdet - INFO - initialize Shared2FCBBoxHead with init_cfg [{'type': 'Normal', 'std': 0.01, 'override': {'name': 'fc_cls'}}, {'type': 'Normal', 'std': 0.001, 'override': {'name': 'fc_reg'}}, {'type': 'Xavier', 'distribution': 'uniform', 'override': [{'name': 'shared_fcs'}, {'name': 'cls_fcs'}, {'name': 'reg_fcs'}]}]
2022-12-05 15:47:22,856 - mmdet - INFO - initialize Shared2FCBBoxHead with init_cfg [{'type': 'Normal', 'std': 0.01, 'override': {'name': 'fc_cls'}}, {'type': 'Normal', 'std': 0.001, 'override': {'name': 'fc_reg'}}, {'type': 'Xavier', 'distribution': 'uniform', 'override': [{'name': 'shared_fcs'}, {'name': 'cls_fcs'}, {'name': 'reg_fcs'}]}]
2022-12-05 15:47:23,098 - mmdet - INFO - sixx >>> dateset::------------------------------------------------------------
loading annotations into memory...
Done (t=0.00s)
creating index...
index created!
loading annotations into memory...
Done (t=0.00s)
creating index...
index created!
2022-12-05 15:47:23,153 - mmdet - INFO - sixx >>> train detector::------------------------------------------------------------
2022-12-05 15:47:24,568 - mmdet - INFO - Automatic scaling of learning rate (LR) has been disabled.
loading annotations into memory...
Done (t=0.00s)
creating index...
index created!
2022-12-05 15:47:25,086 - mmdet - INFO - load checkpoint from local path: checkpoints/cascade_rcnn_r50_fpn_1x_coco_20200316-3dc56deb.pth
2022-12-05 15:47:25,271 - mmdet - WARNING - The model and loaded state dict do not match exactly
size mismatch for roi_head.bbox_head.0.fc_cls.weight: copying a param with shape torch.Size([81, 1024]) from checkpoint, the shape in current model is torch.Size([6, 1024]).
size mismatch for roi_head.bbox_head.0.fc_cls.bias: copying a param with shape torch.Size([81]) from checkpoint, the shape in current model is torch.Size([6]).
size mismatch for roi_head.bbox_head.1.fc_cls.weight: copying a param with shape torch.Size([81, 1024]) from checkpoint, the shape in current model is torch.Size([6, 1024]).
size mismatch for roi_head.bbox_head.1.fc_cls.bias: copying a param with shape torch.Size([81]) from checkpoint, the shape in current model is torch.Size([6]).
size mismatch for roi_head.bbox_head.2.fc_cls.weight: copying a param with shape torch.Size([81, 1024]) from checkpoint, the shape in current model is torch.Size([6, 1024]).
size mismatch for roi_head.bbox_head.2.fc_cls.bias: copying a param with shape torch.Size([81]) from checkpoint, the shape in current model is torch.Size([6]).
2022-12-05 15:47:25,283 - mmdet - INFO - Start running, host: oschung_skcc@SKCCBMS20GS01, work_dir: /home/oschung_skcc/my/git/mmdetection/work_dirs/ttt
2022-12-05 15:47:25,284 - mmdet - INFO - Hooks will be executed in the following order:
before_run:
(VERY_HIGH ) CosineAnnealingLrUpdaterHook
(NORMAL ) CheckpointHook
(LOW ) EvalHook
(VERY_LOW ) TextLoggerHook
(VERY_LOW ) MMDetWandbHook
--------------------
before_train_epoch:
(VERY_HIGH ) CosineAnnealingLrUpdaterHook
(NORMAL ) NumClassCheckHook
(LOW ) IterTimerHook
(LOW ) EvalHook
(VERY_LOW ) TextLoggerHook
(VERY_LOW ) MMDetWandbHook
--------------------
before_train_iter:
(VERY_HIGH ) CosineAnnealingLrUpdaterHook
(LOW ) IterTimerHook
(LOW ) EvalHook
--------------------
after_train_iter:
(ABOVE_NORMAL) OptimizerHook
(NORMAL ) CheckpointHook
(LOW ) IterTimerHook
(LOW ) EvalHook
(VERY_LOW ) TextLoggerHook
(VERY_LOW ) MMDetWandbHook
--------------------
after_train_epoch:
(NORMAL ) CheckpointHook
(LOW ) EvalHook
(VERY_LOW ) TextLoggerHook
(VERY_LOW ) MMDetWandbHook
--------------------
before_val_epoch:
(NORMAL ) NumClassCheckHook
(LOW ) IterTimerHook
(VERY_LOW ) TextLoggerHook
(VERY_LOW ) MMDetWandbHook
--------------------
before_val_iter:
(LOW ) IterTimerHook
--------------------
after_val_iter:
(LOW ) IterTimerHook
--------------------
after_val_epoch:
(VERY_LOW ) TextLoggerHook
(VERY_LOW ) MMDetWandbHook
--------------------
after_run:
(VERY_LOW ) TextLoggerHook
(VERY_LOW ) MMDetWandbHook
--------------------
runner = dict(type=’EpochBasedRunner’, max_epochs=36)
evaluation = dict(interval=4, metric=’bbox’, save_best=’bbox_mAP’)
auto_scale_lr = dict(enable=False, base_batch_size=16)
10 * 36 = 2.5 * (4*36)
step 144
epoch
전체 데이터 셋에 대해 1번 forward pass/backward pass 과정(Back propagation algorithm, 역전파)을 거친 것
전체 데이터셋에 대해 한 번 학습을 완료한 상태
step
하나의 Batch로부터 loss를 계산한 후, Weight와 Bias를 1회 업데이트하는 것을 1 Step이라고 한다.
Batch Size
1 Step에서 사용한 데이터 개수. 가령 SGD의 batch size는 1이다.
1 epoch과정에서 효율적인 학습을 위해 (메모리부족, 속도저항방지) 전체 데이터(Batch)를 일부데이터(Mini-Batch)로 만들고, 그때 크기를 batch size라고 한다.
Iteration
하나의 epoch에 데이터를 나눌 때 몇 번 나누어서 주는지를 iteration이라고 한다.

sample(전체학습데이터) N * Epochs n = Batch size * Step n
ex) 턱걸이48개목표 * 1회 반복 = 1세트당 12개 * 4 세트
$ python sixxtools/train.py \\
"sixxconfigs/cascade_rcnn_r50_fpn_1x_coco.py" \\
--work-dir "work_dirs/ttt"
2022-12-05 15:47:25,284 - mmdet - INFO - workflow: [('train', 1), ('val', 1)], max: 36 epochs
2022-12-05 15:47:25,284 - mmdet - INFO - Checkpoints will be saved to /home/oschung_skcc/my/git/mmdetection/work_dirs/ttt by HardDiskBackend.
wandb: Currently logged in as: onesixx. Use `wandb login --relogin` to force relogin
wandb: wandb version 0.13.5 is available! To upgrade, please run:
wandb: $ pip install wandb --upgrade
wandb: Tracking run with wandb version 0.13.4
wandb: Run data is saved locally in /home/oschung_skcc/my/git/mmdetection/wandb/run-20221205_154726-25x8bwd3
wandb: Run `wandb offline` to turn off syncing.
wandb: Syncing run exp-cascade_rcnn_r50_fpn_1x-job16
wandb: ⭐️ View project at https://wandb.ai/onesixx/kaggle_cowboy_outfits
wandb: ? View run at https://wandb.ai/onesixx/kaggle_cowboy_outfits/runs/25x8bwd3
2022-12-05 15:47:32,533 - mmdet - WARNING - The num_eval_images (13) is greater than the total number of validation samples (13). The complete validation dataset will be logged.
wandb: 15 of 15 files downloaded.
2022-12-05 15:47:48,594 - mmdet - INFO - Epoch [1][1/4] lr: 2.500e-06, eta: 0:13:13, time: 5.551, data_time: 2.331, memory: 5837, loss_rpn_cls: 0.0031, loss_rpn_bbox: 0.0066, s0.loss_cls: 1.7488, s0.acc: 20.5078, s0.loss_bbox: 0.0853, s1.loss_cls: 0.9127, s1.acc: 12.6465, s1.loss_bbox: 0.0246, s2.loss_cls: 0.4599, s2.acc: 7.6660, s2.loss_bbox: 0.0073, loss: 3.2482
2022-12-05 15:47:48,897 - mmdet - INFO - Epoch [1][2/4] lr: 7.494e-06, eta: 0:06:55, time: 0.303, data_time: 0.037, memory: 6815, loss_rpn_cls: 0.1012, loss_rpn_bbox: 0.0128, s0.loss_cls: 1.7895, s0.acc: 10.7910, s0.loss_bbox: 0.1166, s1.loss_cls: 0.9254, s1.acc: 7.1289, s1.loss_bbox: 0.0801, s2.loss_cls: 0.4467, s2.acc: 10.5469, s2.loss_bbox: 0.0285, loss: 3.5007
2022-12-05 15:47:49,231 - mmdet - INFO - Epoch [1][3/4] lr: 1.248e-05, eta: 0:04:50, time: 0.332, data_time: 0.036, memory: 6815, loss_rpn_cls: 0.0937, loss_rpn_bbox: 0.0147, s0.loss_cls: 1.8427, s0.acc: 8.2031, s0.loss_bbox: 0.0674, s1.loss_cls: 0.9395, s1.acc: 9.7656, s1.loss_bbox: 0.0559, s2.loss_cls: 0.4559, s2.acc: 6.0547, s2.loss_bbox: 0.0200, loss: 3.4897
2022-12-05 15:47:49,518 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:47:49,519 - mmdet - INFO - Epoch [1][4/4] lr: 1.747e-05, eta: 0:03:46, time: 0.285, data_time: 0.038, memory: 6815, loss_rpn_cls: 0.2174, loss_rpn_bbox: 0.0139, s0.loss_cls: 1.8114, s0.acc: 11.2305, s0.loss_bbox: 0.0351, s1.loss_cls: 0.9192, s1.acc: 10.6934, s1.loss_bbox: 0.0265, s2.loss_cls: 0.4488, s2.acc: 8.4473, s2.loss_bbox: 0.0149, loss: 3.4874
2022-12-05 15:47:52,798 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:47:52,799 - mmdet - INFO - Epoch(val) [1][4] loss_rpn_cls: 0.0456, loss_rpn_bbox: 0.0090, s0.loss_cls: 1.8224, s0.acc: 12.1704, s0.loss_bbox: 0.0668, s1.loss_cls: 0.9317, s1.acc: 7.9834, s1.loss_bbox: 0.0805, s2.loss_cls: 0.4505, s2.acc: 7.6172, s2.loss_bbox: 0.0396, loss: 3.4463
2022-12-05 15:47:55,462 - mmdet - INFO - Epoch [2][1/4] lr: 2.244e-05, eta: 0:04:12, time: 2.624, data_time: 2.334, memory: 6815, loss_rpn_cls: 0.0249, loss_rpn_bbox: 0.0083, s0.loss_cls: 1.8190, s0.acc: 11.1816, s0.loss_bbox: 0.1488, s1.loss_cls: 0.9295, s1.acc: 9.9609, s1.loss_bbox: 0.1127, s2.loss_cls: 0.4521, s2.acc: 7.4219, s2.loss_bbox: 0.0453, loss: 3.5407
2022-12-05 15:47:55,751 - mmdet - INFO - Epoch [2][2/4] lr: 2.739e-05, eta: 0:03:35, time: 0.287, data_time: 0.046, memory: 6815, loss_rpn_cls: 0.2532, loss_rpn_bbox: 0.0212, s0.loss_cls: 1.7522, s0.acc: 16.4551, s0.loss_bbox: 0.0064, s1.loss_cls: 0.8942, s1.acc: 10.8398, s1.loss_bbox: 0.0023, s2.loss_cls: 0.4332, s2.acc: 17.6758, s2.loss_bbox: 0.0008, loss: 3.3635
2022-12-05 15:47:56,040 - mmdet - INFO - Epoch [2][3/4] lr: 3.233e-05, eta: 0:03:09, time: 0.291, data_time: 0.042, memory: 6815, loss_rpn_cls: 0.0009, loss_rpn_bbox: 0.0070, s0.loss_cls: 1.7066, s0.acc: 29.6387, s0.loss_bbox: 0.0882, s1.loss_cls: 0.8997, s1.acc: 17.7734, s1.loss_bbox: 0.0183, s2.loss_cls: 0.4533, s2.acc: 10.2051, s2.loss_bbox: 0.0034, loss: 3.1774
2022-12-05 15:47:56,311 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:47:56,311 - mmdet - INFO - Epoch [2][4/4] lr: 3.725e-05, eta: 0:02:49, time: 0.271, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.2295, loss_rpn_bbox: 0.0216, s0.loss_cls: 1.7507, s0.acc: 19.7266, s0.loss_bbox: 0.0358, s1.loss_cls: 0.9137, s1.acc: 13.3789, s1.loss_bbox: 0.0340, s2.loss_cls: 0.4403, s2.acc: 15.9668, s2.loss_bbox: 0.0075, loss: 3.4330
2022-12-05 15:47:59,695 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:47:59,696 - mmdet - INFO - Epoch(val) [2][4] loss_rpn_cls: 0.0573, loss_rpn_bbox: 0.0103, s0.loss_cls: 1.7448, s0.acc: 23.4863, s0.loss_bbox: 0.0672, s1.loss_cls: 0.9018, s1.acc: 17.5293, s1.loss_bbox: 0.0677, s2.loss_cls: 0.4363, s2.acc: 13.7085, s2.loss_bbox: 0.0342, loss: 3.3197
2022-12-05 15:48:02,492 - mmdet - INFO - Epoch [3][1/4] lr: 4.214e-05, eta: 0:03:10, time: 2.750, data_time: 2.361, memory: 6815, loss_rpn_cls: 0.2049, loss_rpn_bbox: 0.0143, s0.loss_cls: 1.6994, s0.acc: 29.4434, s0.loss_bbox: 0.0358, s1.loss_cls: 0.8882, s1.acc: 21.3867, s1.loss_bbox: 0.0259, s2.loss_cls: 0.4300, s2.acc: 23.4375, s2.loss_bbox: 0.0048, loss: 3.3034
2022-12-05 15:48:02,773 - mmdet - INFO - Epoch [3][2/4] lr: 4.700e-05, eta: 0:02:53, time: 0.281, data_time: 0.051, memory: 6815, loss_rpn_cls: 0.0302, loss_rpn_bbox: 0.0082, s0.loss_cls: 1.7365, s0.acc: 23.2422, s0.loss_bbox: 0.1428, s1.loss_cls: 0.8990, s1.acc: 21.0938, s1.loss_bbox: 0.1101, s2.loss_cls: 0.4383, s2.acc: 15.8691, s2.loss_bbox: 0.0411, loss: 3.4062
2022-12-05 15:48:03,047 - mmdet - INFO - Epoch [3][3/4] lr: 5.183e-05, eta: 0:02:40, time: 0.281, data_time: 0.045, memory: 6815, loss_rpn_cls: 0.0111, loss_rpn_bbox: 0.0070, s0.loss_cls: 1.5662, s0.acc: 62.2070, s0.loss_bbox: 0.0874, s1.loss_cls: 0.8483, s1.acc: 36.7676, s1.loss_bbox: 0.0180, s2.loss_cls: 0.4284, s2.acc: 25.0977, s2.loss_bbox: 0.0038, loss: 2.9701
2022-12-05 15:48:03,326 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:03,327 - mmdet - INFO - Epoch [3][4/4] lr: 5.662e-05, eta: 0:02:28, time: 0.277, data_time: 0.043, memory: 6815, loss_rpn_cls: 0.1471, loss_rpn_bbox: 0.0221, s0.loss_cls: 1.6198, s0.acc: 46.9238, s0.loss_bbox: 0.0831, s1.loss_cls: 0.8598, s1.acc: 31.2988, s1.loss_bbox: 0.0597, s2.loss_cls: 0.4192, s2.acc: 31.0547, s2.loss_bbox: 0.0196, loss: 3.2305
2022-12-05 15:48:06,627 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:06,627 - mmdet - INFO - Epoch(val) [3][4] loss_rpn_cls: 0.0471, loss_rpn_bbox: 0.0093, s0.loss_cls: 1.6069, s0.acc: 55.5298, s0.loss_bbox: 0.0692, s1.loss_cls: 0.8455, s1.acc: 38.5742, s1.loss_bbox: 0.0713, s2.loss_cls: 0.4126, s2.acc: 38.5864, s2.loss_bbox: 0.0359, loss: 3.0978
2022-12-05 15:48:09,260 - mmdet - INFO - Epoch [4][1/4] lr: 6.138e-05, eta: 0:02:42, time: 2.591, data_time: 2.303, memory: 6815, loss_rpn_cls: 0.0469, loss_rpn_bbox: 0.0142, s0.loss_cls: 1.6481, s0.acc: 44.1406, s0.loss_bbox: 0.1738, s1.loss_cls: 0.8817, s1.acc: 20.7520, s1.loss_bbox: 0.1367, s2.loss_cls: 0.4236, s2.acc: 28.8086, s2.loss_bbox: 0.0479, loss: 3.3728
2022-12-05 15:48:09,547 - mmdet - INFO - Epoch [4][2/4] lr: 6.609e-05, eta: 0:02:32, time: 0.286, data_time: 0.048, memory: 6815, loss_rpn_cls: 0.0668, loss_rpn_bbox: 0.0123, s0.loss_cls: 1.5206, s0.acc: 69.2871, s0.loss_bbox: 0.1097, s1.loss_cls: 0.8262, s1.acc: 47.9980, s1.loss_bbox: 0.0820, s2.loss_cls: 0.3992, s2.acc: 58.4961, s2.loss_bbox: 0.0206, loss: 3.0374
2022-12-05 15:48:09,818 - mmdet - INFO - Epoch [4][3/4] lr: 7.075e-05, eta: 0:02:23, time: 0.273, data_time: 0.042, memory: 6815, loss_rpn_cls: 0.0086, loss_rpn_bbox: 0.0070, s0.loss_cls: 1.3406, s0.acc: 93.6035, s0.loss_bbox: 0.0854, s1.loss_cls: 0.7601, s1.acc: 77.3438, s1.loss_bbox: 0.0229, s2.loss_cls: 0.3863, s2.acc: 61.1816, s2.loss_bbox: 0.0068, loss: 2.6176
2022-12-05 15:48:10,084 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:10,085 - mmdet - INFO - Epoch [4][4/4] lr: 7.537e-05, eta: 0:02:15, time: 0.267, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.2018, loss_rpn_bbox: 0.0171, s0.loss_cls: 1.4287, s0.acc: 87.7441, s0.loss_bbox: 0.0437, s1.loss_cls: 0.7658, s1.acc: 76.0254, s1.loss_bbox: 0.0209, s2.loss_cls: 0.3789, s2.acc: 70.2148, s2.loss_bbox: 0.0067, loss: 2.8637
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 13/13, 17.0 task/s, elapsed: 1s, ETA: 0s2022-12-05 15:48:11,084 - mmdet - INFO - Evaluating bbox...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.01s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:48:11,106 - mmdet - INFO -
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.002
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.004
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.004
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.007
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.100
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.100
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.100
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.150
2022-12-05 15:48:12,715 - mmdet - INFO - Now best checkpoint is saved as best_bbox_mAP_epoch_4.pth.
2022-12-05 15:48:12,716 - mmdet - INFO - Best bbox_mAP is 0.0020 at 4 epoch.
2022-12-05 15:48:12,716 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:12,716 - mmdet - INFO - Epoch(val) [4][13] bbox_mAP: 0.0020, bbox_mAP_50: 0.0040, bbox_mAP_75: 0.0040, bbox_mAP_s: -1.0000, bbox_mAP_m: 0.0000, bbox_mAP_l: 0.0070, bbox_mAP_copypaste: 0.002 0.004 0.004 -1.000 0.000 0.007
2022-12-05 15:48:16,737 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:16,737 - mmdet - INFO - Epoch(val) [4][4] loss_rpn_cls: 0.0593, loss_rpn_bbox: 0.0098, s0.loss_cls: 1.3725, s0.acc: 90.1611, s0.loss_bbox: 0.0601, s1.loss_cls: 0.7525, s1.acc: 75.0854, s1.loss_bbox: 0.0682, s2.loss_cls: 0.3672, s2.acc: 80.8105, s2.loss_bbox: 0.0313, loss: 2.7208
2022-12-05 15:48:19,419 - mmdet - INFO - Epoch [5][1/4] lr: 7.993e-05, eta: 0:02:26, time: 2.640, data_time: 2.338, memory: 6815, loss_rpn_cls: 0.2093, loss_rpn_bbox: 0.0202, s0.loss_cls: 1.3752, s0.acc: 88.7695, s0.loss_bbox: 0.1067, s1.loss_cls: 0.7636, s1.acc: 71.3867, s1.loss_bbox: 0.0834, s2.loss_cls: 0.3672, s2.acc: 81.2988, s2.loss_bbox: 0.0250, loss: 2.9506
2022-12-05 15:48:19,737 - mmdet - INFO - Epoch [5][2/4] lr: 8.444e-05, eta: 0:02:19, time: 0.322, data_time: 0.044, memory: 6815, loss_rpn_cls: 0.0010, loss_rpn_bbox: 0.0065, s0.loss_cls: 1.1160, s0.acc: 97.5098, s0.loss_bbox: 0.0809, s1.loss_cls: 0.6652, s1.acc: 94.6777, s1.loss_bbox: 0.0225, s2.loss_cls: 0.3447, s2.acc: 87.2559, s2.loss_bbox: 0.0083, loss: 2.2450
2022-12-05 15:48:20,028 - mmdet - INFO - Epoch [5][3/4] lr: 8.889e-05, eta: 0:02:12, time: 0.287, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.1231, loss_rpn_bbox: 0.0104, s0.loss_cls: 1.1126, s0.acc: 97.8516, s0.loss_bbox: 0.0371, s1.loss_cls: 0.6611, s1.acc: 92.2363, s1.loss_bbox: 0.0237, s2.loss_cls: 0.3261, s2.acc: 94.2383, s2.loss_bbox: 0.0045, loss: 2.2986
2022-12-05 15:48:20,327 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:20,328 - mmdet - INFO - Epoch [5][4/4] lr: 9.328e-05, eta: 0:02:07, time: 0.301, data_time: 0.043, memory: 6815, loss_rpn_cls: 0.0267, loss_rpn_bbox: 0.0069, s0.loss_cls: 1.2198, s0.acc: 95.7520, s0.loss_bbox: 0.0655, s1.loss_cls: 0.6918, s1.acc: 88.2324, s1.loss_bbox: 0.0425, s2.loss_cls: 0.3442, s2.acc: 89.0625, s2.loss_bbox: 0.0196, loss: 2.4170
2022-12-05 15:48:23,574 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:23,575 - mmdet - INFO - Epoch(val) [5][4] loss_rpn_cls: 0.0611, loss_rpn_bbox: 0.0105, s0.loss_cls: 1.0831, s0.acc: 96.2158, s0.loss_bbox: 0.0521, s1.loss_cls: 0.6351, s1.acc: 93.3960, s1.loss_bbox: 0.0593, s2.loss_cls: 0.3137, s2.acc: 95.9595, s2.loss_bbox: 0.0277, loss: 2.2426
2022-12-05 15:48:26,253 - mmdet - INFO - Epoch [6][1/4] lr: 9.760e-05, eta: 0:02:15, time: 2.634, data_time: 2.319, memory: 6815, loss_rpn_cls: 0.2079, loss_rpn_bbox: 0.0220, s0.loss_cls: 0.9653, s0.acc: 98.7305, s0.loss_bbox: 0.0204, s1.loss_cls: 0.5960, s1.acc: 98.4375, s1.loss_bbox: 0.0080, s2.loss_cls: 0.2932, s2.acc: 98.0469, s2.loss_bbox: 0.0035, loss: 2.1164
2022-12-05 15:48:26,526 - mmdet - INFO - Epoch [6][2/4] lr: 1.019e-04, eta: 0:02:09, time: 0.279, data_time: 0.053, memory: 6815, loss_rpn_cls: 0.1902, loss_rpn_bbox: 0.0178, s0.loss_cls: 1.0163, s0.acc: 97.3633, s0.loss_bbox: 0.0376, s1.loss_cls: 0.6253, s1.acc: 95.8008, s1.loss_bbox: 0.0257, s2.loss_cls: 0.3012, s2.acc: 95.8984, s2.loss_bbox: 0.0144, loss: 2.2286
2022-12-05 15:48:26,798 - mmdet - INFO - Epoch [6][3/4] lr: 1.060e-04, eta: 0:02:04, time: 0.272, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0023, loss_rpn_bbox: 0.0069, s0.loss_cls: 0.7148, s0.acc: 97.8027, s0.loss_bbox: 0.0794, s1.loss_cls: 0.4852, s1.acc: 98.8770, s1.loss_bbox: 0.0216, s2.loss_cls: 0.2589, s2.acc: 99.4141, s2.loss_bbox: 0.0045, loss: 1.5736
2022-12-05 15:48:27,064 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:27,065 - mmdet - INFO - Epoch [6][4/4] lr: 1.102e-04, eta: 0:01:59, time: 0.266, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.0112, loss_rpn_bbox: 0.0072, s0.loss_cls: 0.9363, s0.acc: 93.7988, s0.loss_bbox: 0.1394, s1.loss_cls: 0.5614, s1.acc: 94.3848, s1.loss_bbox: 0.1045, s2.loss_cls: 0.2814, s2.acc: 96.7285, s2.loss_bbox: 0.0245, loss: 2.0657
2022-12-05 15:48:30,330 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:30,331 - mmdet - INFO - Epoch(val) [6][4] loss_rpn_cls: 0.0527, loss_rpn_bbox: 0.0100, s0.loss_cls: 0.8206, s0.acc: 95.9351, s0.loss_bbox: 0.0612, s1.loss_cls: 0.5178, s1.acc: 95.4224, s1.loss_bbox: 0.0723, s2.loss_cls: 0.2571, s2.acc: 96.5210, s2.loss_bbox: 0.0361, loss: 1.8279
2022-12-05 15:48:33,017 - mmdet - INFO - Epoch [7][1/4] lr: 1.142e-04, eta: 0:02:06, time: 2.648, data_time: 2.361, memory: 6815, loss_rpn_cls: 0.1633, loss_rpn_bbox: 0.0166, s0.loss_cls: 0.8366, s0.acc: 94.5801, s0.loss_bbox: 0.1210, s1.loss_cls: 0.5287, s1.acc: 94.8242, s1.loss_bbox: 0.0866, s2.loss_cls: 0.2582, s2.acc: 96.2402, s2.loss_bbox: 0.0299, loss: 2.0408
2022-12-05 15:48:33,295 - mmdet - INFO - Epoch [7][2/4] lr: 1.181e-04, eta: 0:02:01, time: 0.278, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0045, loss_rpn_bbox: 0.0065, s0.loss_cls: 0.4910, s0.acc: 97.7539, s0.loss_bbox: 0.0770, s1.loss_cls: 0.3753, s1.acc: 98.7305, s1.loss_bbox: 0.0274, s2.loss_cls: 0.2054, s2.acc: 99.1211, s2.loss_bbox: 0.0118, loss: 1.1990
2022-12-05 15:48:33,563 - mmdet - INFO - Epoch [7][3/4] lr: 1.220e-04, eta: 0:01:57, time: 0.269, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0319, loss_rpn_bbox: 0.0067, s0.loss_cls: 0.7531, s0.acc: 95.8984, s0.loss_bbox: 0.0676, s1.loss_cls: 0.4770, s1.acc: 96.5332, s1.loss_bbox: 0.0423, s2.loss_cls: 0.2418, s2.acc: 96.9238, s2.loss_bbox: 0.0204, loss: 1.6408
2022-12-05 15:48:33,854 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:33,855 - mmdet - INFO - Epoch [7][4/4] lr: 1.258e-04, eta: 0:01:53, time: 0.288, data_time: 0.042, memory: 6815, loss_rpn_cls: 0.0837, loss_rpn_bbox: 0.0158, s0.loss_cls: 0.6040, s0.acc: 95.0195, s0.loss_bbox: 0.1144, s1.loss_cls: 0.4177, s1.acc: 95.5566, s1.loss_bbox: 0.0986, s2.loss_cls: 0.2091, s2.acc: 97.4609, s2.loss_bbox: 0.0258, loss: 1.5691
2022-12-05 15:48:37,136 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:37,137 - mmdet - INFO - Epoch(val) [7][4] loss_rpn_cls: 0.0351, loss_rpn_bbox: 0.0100, s0.loss_cls: 0.5978, s0.acc: 95.3369, s0.loss_bbox: 0.0685, s1.loss_cls: 0.4041, s1.acc: 95.2026, s1.loss_bbox: 0.0737, s2.loss_cls: 0.2012, s2.acc: 96.3867, s2.loss_bbox: 0.0354, loss: 1.4257
2022-12-05 15:48:39,794 - mmdet - INFO - Epoch [8][1/4] lr: 1.295e-04, eta: 0:01:59, time: 2.617, data_time: 2.327, memory: 6815, loss_rpn_cls: 0.0077, loss_rpn_bbox: 0.0066, s0.loss_cls: 0.3269, s0.acc: 97.7539, s0.loss_bbox: 0.0744, s1.loss_cls: 0.2765, s1.acc: 98.8281, s1.loss_bbox: 0.0260, s2.loss_cls: 0.1560, s2.acc: 99.0234, s2.loss_bbox: 0.0130, loss: 0.8870
2022-12-05 15:48:40,082 - mmdet - INFO - Epoch [8][2/4] lr: 1.331e-04, eta: 0:01:55, time: 0.288, data_time: 0.049, memory: 6815, loss_rpn_cls: 0.1386, loss_rpn_bbox: 0.0144, s0.loss_cls: 0.5305, s0.acc: 95.9961, s0.loss_bbox: 0.0675, s1.loss_cls: 0.3681, s1.acc: 96.5820, s1.loss_bbox: 0.0434, s2.loss_cls: 0.1824, s2.acc: 96.9727, s2.loss_bbox: 0.0207, loss: 1.3657
2022-12-05 15:48:40,365 - mmdet - INFO - Epoch [8][3/4] lr: 1.366e-04, eta: 0:01:51, time: 0.281, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.0505, loss_rpn_bbox: 0.0077, s0.loss_cls: 0.4934, s0.acc: 95.2637, s0.loss_bbox: 0.1090, s1.loss_cls: 0.3365, s1.acc: 95.9473, s1.loss_bbox: 0.0823, s2.loss_cls: 0.1738, s2.acc: 97.5586, s2.loss_bbox: 0.0238, loss: 1.2771
2022-12-05 15:48:40,634 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:40,643 - mmdet - INFO - Epoch [8][4/4] lr: 1.400e-04, eta: 0:01:48, time: 0.272, data_time: 0.044, memory: 6815, loss_rpn_cls: 0.1328, loss_rpn_bbox: 0.0150, s0.loss_cls: 0.3824, s0.acc: 97.3145, s0.loss_bbox: 0.0459, s1.loss_cls: 0.2794, s1.acc: 97.6562, s1.loss_bbox: 0.0175, s2.loss_cls: 0.1469, s2.acc: 97.5098, s2.loss_bbox: 0.0095, loss: 1.0294
2022-12-05 15:48:40,744 - mmdet - INFO - Saving checkpoint at 8 epochs
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 13/13, 17.1 task/s, elapsed: 1s, ETA: 0s2022-12-05 15:48:43,669 - mmdet - INFO - Evaluating bbox...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.01s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:48:43,691 - mmdet - INFO -
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.012
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.030
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.005
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.035
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.283
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.283
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.283
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.425
2022-12-05 15:48:43,917 - mmdet - INFO - The previous best checkpoint /home/oschung_skcc/my/git/mmdetection/work_dirs/ttt/best_bbox_mAP_epoch_4.pth was removed
2022-12-05 15:48:45,927 - mmdet - INFO - Now best checkpoint is saved as best_bbox_mAP_epoch_8.pth.
2022-12-05 15:48:45,928 - mmdet - INFO - Best bbox_mAP is 0.0120 at 8 epoch.
2022-12-05 15:48:45,928 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:45,928 - mmdet - INFO - Epoch(val) [8][13] bbox_mAP: 0.0120, bbox_mAP_50: 0.0300, bbox_mAP_75: 0.0050, bbox_mAP_s: -1.0000, bbox_mAP_m: 0.0000, bbox_mAP_l: 0.0350, bbox_mAP_copypaste: 0.012 0.030 0.005 -1.000 0.000 0.035
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.01s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:48:55,004 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:55,005 - mmdet - INFO - Epoch(val) [8][4] loss_rpn_cls: 0.0349, loss_rpn_bbox: 0.0096, s0.loss_cls: 0.4246, s0.acc: 95.4712, s0.loss_bbox: 0.0698, s1.loss_cls: 0.2975, s1.acc: 95.2637, s1.loss_bbox: 0.0782, s2.loss_cls: 0.1499, s2.acc: 96.3379, s2.loss_bbox: 0.0378, loss: 1.1024
2022-12-05 15:48:57,664 - mmdet - INFO - Epoch [9][1/4] lr: 1.434e-04, eta: 0:01:52, time: 2.620, data_time: 2.328, memory: 6815, loss_rpn_cls: 0.0962, loss_rpn_bbox: 0.0109, s0.loss_cls: 0.5071, s0.acc: 94.5801, s0.loss_bbox: 0.1009, s1.loss_cls: 0.3324, s1.acc: 94.8730, s1.loss_bbox: 0.0936, s2.loss_cls: 0.1676, s2.acc: 96.5332, s2.loss_bbox: 0.0323, loss: 1.3411
2022-12-05 15:48:57,950 - mmdet - INFO - Epoch [9][2/4] lr: 1.466e-04, eta: 0:01:49, time: 0.287, data_time: 0.046, memory: 6815, loss_rpn_cls: 0.1576, loss_rpn_bbox: 0.0193, s0.loss_cls: 0.2974, s0.acc: 98.2910, s0.loss_bbox: 0.0253, s1.loss_cls: 0.2258, s1.acc: 98.4863, s1.loss_bbox: 0.0157, s2.loss_cls: 0.1186, s2.acc: 98.7793, s2.loss_bbox: 0.0077, loss: 0.8674
2022-12-05 15:48:58,230 - mmdet - INFO - Epoch [9][3/4] lr: 1.497e-04, eta: 0:01:46, time: 0.277, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.0303, loss_rpn_bbox: 0.0064, s0.loss_cls: 0.2539, s0.acc: 96.7773, s0.loss_bbox: 0.0700, s1.loss_cls: 0.1985, s1.acc: 97.1191, s1.loss_bbox: 0.0412, s2.loss_cls: 0.1066, s2.acc: 97.7051, s2.loss_bbox: 0.0110, loss: 0.7180
2022-12-05 15:48:58,501 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:48:58,505 - mmdet - INFO - Epoch [9][4/4] lr: 1.527e-04, eta: 0:01:43, time: 0.274, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0048, loss_rpn_bbox: 0.0075, s0.loss_cls: 0.1208, s0.acc: 98.4375, s0.loss_bbox: 0.0457, s1.loss_cls: 0.1178, s1.acc: 98.7793, s1.loss_bbox: 0.0229, s2.loss_cls: 0.0691, s2.acc: 99.1699, s2.loss_bbox: 0.0065, loss: 0.3951
2022-12-05 15:49:01,734 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:01,735 - mmdet - INFO - Epoch(val) [9][4] loss_rpn_cls: 0.0423, loss_rpn_bbox: 0.0096, s0.loss_cls: 0.3182, s0.acc: 95.4102, s0.loss_bbox: 0.0716, s1.loss_cls: 0.2191, s1.acc: 95.3247, s1.loss_bbox: 0.0755, s2.loss_cls: 0.1107, s2.acc: 96.3379, s2.loss_bbox: 0.0370, loss: 0.8841
2022-12-05 15:49:04,410 - mmdet - INFO - Epoch [10][1/4] lr: 1.556e-04, eta: 0:01:46, time: 2.630, data_time: 2.324, memory: 6815, loss_rpn_cls: 0.0587, loss_rpn_bbox: 0.0130, s0.loss_cls: 0.3101, s0.acc: 94.7754, s0.loss_bbox: 0.1114, s1.loss_cls: 0.2117, s1.acc: 95.4590, s1.loss_bbox: 0.0921, s2.loss_cls: 0.1052, s2.acc: 97.5586, s2.loss_bbox: 0.0208, loss: 0.9229
2022-12-05 15:49:04,691 - mmdet - INFO - Epoch [10][2/4] lr: 1.584e-04, eta: 0:01:43, time: 0.284, data_time: 0.052, memory: 6815, loss_rpn_cls: 0.0264, loss_rpn_bbox: 0.0042, s0.loss_cls: 0.3358, s0.acc: 95.3125, s0.loss_bbox: 0.0751, s1.loss_cls: 0.2101, s1.acc: 95.5078, s1.loss_bbox: 0.0549, s2.loss_cls: 0.1127, s2.acc: 96.0938, s2.loss_bbox: 0.0278, loss: 0.8470
2022-12-05 15:49:04,961 - mmdet - INFO - Epoch [10][3/4] lr: 1.611e-04, eta: 0:01:41, time: 0.270, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0696, loss_rpn_bbox: 0.0073, s0.loss_cls: 0.2300, s0.acc: 97.0215, s0.loss_bbox: 0.0544, s1.loss_cls: 0.1467, s1.acc: 97.4609, s1.loss_bbox: 0.0276, s2.loss_cls: 0.0797, s2.acc: 97.8516, s2.loss_bbox: 0.0100, loss: 0.6253
2022-12-05 15:49:05,234 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:05,235 - mmdet - INFO - Epoch [10][4/4] lr: 1.637e-04, eta: 0:01:38, time: 0.273, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.0019, loss_rpn_bbox: 0.0076, s0.loss_cls: 0.0874, s0.acc: 98.4375, s0.loss_bbox: 0.0426, s1.loss_cls: 0.0733, s1.acc: 98.9258, s1.loss_bbox: 0.0194, s2.loss_cls: 0.0425, s2.acc: 99.3164, s2.loss_bbox: 0.0051, loss: 0.2798
2022-12-05 15:49:08,605 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:08,606 - mmdet - INFO - Epoch(val) [10][4] loss_rpn_cls: 0.0324, loss_rpn_bbox: 0.0099, s0.loss_cls: 0.2758, s0.acc: 95.0684, s0.loss_bbox: 0.0778, s1.loss_cls: 0.1757, s1.acc: 95.2759, s1.loss_bbox: 0.0737, s2.loss_cls: 0.0883, s2.acc: 96.1182, s2.loss_bbox: 0.0394, loss: 0.7728
2022-12-05 15:49:11,307 - mmdet - INFO - Epoch [11][1/4] lr: 1.662e-04, eta: 0:01:41, time: 2.656, data_time: 2.351, memory: 6815, loss_rpn_cls: 0.0016, loss_rpn_bbox: 0.0068, s0.loss_cls: 0.0950, s0.acc: 98.0469, s0.loss_bbox: 0.0534, s1.loss_cls: 0.0699, s1.acc: 98.5840, s1.loss_bbox: 0.0263, s2.loss_cls: 0.0410, s2.acc: 98.9258, s2.loss_bbox: 0.0108, loss: 0.3049
2022-12-05 15:49:11,575 - mmdet - INFO - Epoch [11][2/4] lr: 1.685e-04, eta: 0:01:38, time: 0.272, data_time: 0.042, memory: 6815, loss_rpn_cls: 0.0298, loss_rpn_bbox: 0.0078, s0.loss_cls: 0.2283, s0.acc: 95.3613, s0.loss_bbox: 0.1032, s1.loss_cls: 0.1312, s1.acc: 95.9473, s1.loss_bbox: 0.0775, s2.loss_cls: 0.0647, s2.acc: 97.1191, s2.loss_bbox: 0.0169, loss: 0.6593
2022-12-05 15:49:11,857 - mmdet - INFO - Epoch [11][3/4] lr: 1.708e-04, eta: 0:01:36, time: 0.279, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.0706, loss_rpn_bbox: 0.0104, s0.loss_cls: 0.2638, s0.acc: 95.1660, s0.loss_bbox: 0.0887, s1.loss_cls: 0.1477, s1.acc: 95.6543, s1.loss_bbox: 0.0700, s2.loss_cls: 0.0751, s2.acc: 97.0703, s2.loss_bbox: 0.0239, loss: 0.7503
2022-12-05 15:49:12,123 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:12,123 - mmdet - INFO - Epoch [11][4/4] lr: 1.729e-04, eta: 0:01:33, time: 0.269, data_time: 0.042, memory: 6815, loss_rpn_cls: 0.0144, loss_rpn_bbox: 0.0067, s0.loss_cls: 0.2314, s0.acc: 95.4102, s0.loss_bbox: 0.0801, s1.loss_cls: 0.1464, s1.acc: 95.5078, s1.loss_bbox: 0.0644, s2.loss_cls: 0.0716, s2.acc: 96.5332, s2.loss_bbox: 0.0235, loss: 0.6384
2022-12-05 15:49:15,364 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:15,364 - mmdet - INFO - Epoch(val) [11][4] loss_rpn_cls: 0.0365, loss_rpn_bbox: 0.0102, s0.loss_cls: 0.2164, s0.acc: 96.0327, s0.loss_bbox: 0.0564, s1.loss_cls: 0.1366, s1.acc: 95.6787, s1.loss_bbox: 0.0659, s2.loss_cls: 0.0667, s2.acc: 96.6064, s2.loss_bbox: 0.0327, loss: 0.6214
2022-12-05 15:49:18,047 - mmdet - INFO - Epoch [12][1/4] lr: 1.749e-04, eta: 0:01:36, time: 2.642, data_time: 2.349, memory: 6815, loss_rpn_cls: 0.0598, loss_rpn_bbox: 0.0077, s0.loss_cls: 0.1913, s0.acc: 96.6309, s0.loss_bbox: 0.0574, s1.loss_cls: 0.1152, s1.acc: 96.8262, s1.loss_bbox: 0.0590, s2.loss_cls: 0.0563, s2.acc: 97.6074, s2.loss_bbox: 0.0232, loss: 0.5698
2022-12-05 15:49:18,322 - mmdet - INFO - Epoch [12][2/4] lr: 1.768e-04, eta: 0:01:34, time: 0.278, data_time: 0.050, memory: 6815, loss_rpn_cls: 0.0408, loss_rpn_bbox: 0.0136, s0.loss_cls: 0.2844, s0.acc: 94.6289, s0.loss_bbox: 0.0891, s1.loss_cls: 0.1503, s1.acc: 95.2148, s1.loss_bbox: 0.0763, s2.loss_cls: 0.0746, s2.acc: 96.8750, s2.loss_bbox: 0.0214, loss: 0.7506
2022-12-05 15:49:18,597 - mmdet - INFO - Epoch [12][3/4] lr: 1.785e-04, eta: 0:01:31, time: 0.274, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0010, loss_rpn_bbox: 0.0072, s0.loss_cls: 0.0800, s0.acc: 98.2422, s0.loss_bbox: 0.0453, s1.loss_cls: 0.0538, s1.acc: 98.5352, s1.loss_bbox: 0.0210, s2.loss_cls: 0.0283, s2.acc: 98.8281, s2.loss_bbox: 0.0084, loss: 0.2451
2022-12-05 15:49:18,864 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:18,865 - mmdet - INFO - Epoch [12][4/4] lr: 1.802e-04, eta: 0:01:29, time: 0.268, data_time: 0.039, memory: 6815, loss_rpn_cls: 0.0180, loss_rpn_bbox: 0.0053, s0.loss_cls: 0.1942, s0.acc: 96.2402, s0.loss_bbox: 0.0708, s1.loss_cls: 0.1034, s1.acc: 96.3379, s1.loss_bbox: 0.0498, s2.loss_cls: 0.0542, s2.acc: 96.9238, s2.loss_bbox: 0.0182, loss: 0.5138
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 13/13, 18.6 task/s, elapsed: 1s, ETA: 0s2022-12-05 15:49:19,733 - mmdet - INFO - Evaluating bbox...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:49:19,747 - mmdet - INFO -
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.009
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.019
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.005
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.028
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.275
2022-12-05 15:49:19,748 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:19,748 - mmdet - INFO - Epoch(val) [12][13] bbox_mAP: 0.0090, bbox_mAP_50: 0.0190, bbox_mAP_75: 0.0050, bbox_mAP_s: -1.0000, bbox_mAP_m: 0.0000, bbox_mAP_l: 0.0280, bbox_mAP_copypaste: 0.009 0.019 0.005 -1.000 0.000 0.028
2022-12-05 15:49:23,488 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:23,489 - mmdet - INFO - Epoch(val) [12][4] loss_rpn_cls: 0.0298, loss_rpn_bbox: 0.0088, s0.loss_cls: 0.2269, s0.acc: 95.5566, s0.loss_bbox: 0.0639, s1.loss_cls: 0.1371, s1.acc: 95.2271, s1.loss_bbox: 0.0719, s2.loss_cls: 0.0637, s2.acc: 96.1670, s2.loss_bbox: 0.0383, loss: 0.6403
2022-12-05 15:49:26,129 - mmdet - INFO - Epoch [13][1/4] lr: 1.817e-04, eta: 0:01:31, time: 2.597, data_time: 2.310, memory: 6815, loss_rpn_cls: 0.0246, loss_rpn_bbox: 0.0137, s0.loss_cls: 0.2719, s0.acc: 94.1895, s0.loss_bbox: 0.1062, s1.loss_cls: 0.1379, s1.acc: 94.8730, s1.loss_bbox: 0.0943, s2.loss_cls: 0.0636, s2.acc: 96.7773, s2.loss_bbox: 0.0280, loss: 0.7403
2022-12-05 15:49:26,414 - mmdet - INFO - Epoch [13][2/4] lr: 1.831e-04, eta: 0:01:29, time: 0.287, data_time: 0.048, memory: 6815, loss_rpn_cls: 0.0072, loss_rpn_bbox: 0.0068, s0.loss_cls: 0.0911, s0.acc: 97.9492, s0.loss_bbox: 0.0531, s1.loss_cls: 0.0482, s1.acc: 98.5840, s1.loss_bbox: 0.0197, s2.loss_cls: 0.0251, s2.acc: 98.8281, s2.loss_bbox: 0.0074, loss: 0.2587
2022-12-05 15:49:26,681 - mmdet - INFO - Epoch [13][3/4] lr: 1.844e-04, eta: 0:01:27, time: 0.268, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0165, loss_rpn_bbox: 0.0091, s0.loss_cls: 0.2895, s0.acc: 93.6035, s0.loss_bbox: 0.0978, s1.loss_cls: 0.1682, s1.acc: 93.3594, s1.loss_bbox: 0.1030, s2.loss_cls: 0.0795, s2.acc: 95.2637, s2.loss_bbox: 0.0388, loss: 0.8023
2022-12-05 15:49:26,999 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:26,999 - mmdet - INFO - Epoch [13][4/4] lr: 1.855e-04, eta: 0:01:25, time: 0.315, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0531, loss_rpn_bbox: 0.0118, s0.loss_cls: 0.1856, s0.acc: 96.6797, s0.loss_bbox: 0.0581, s1.loss_cls: 0.0889, s1.acc: 96.8750, s1.loss_bbox: 0.0299, s2.loss_cls: 0.0438, s2.acc: 97.0703, s2.loss_bbox: 0.0106, loss: 0.4818
2022-12-05 15:49:30,219 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:30,220 - mmdet - INFO - Epoch(val) [13][4] loss_rpn_cls: 0.0375, loss_rpn_bbox: 0.0107, s0.loss_cls: 0.2193, s0.acc: 95.6055, s0.loss_bbox: 0.0624, s1.loss_cls: 0.1351, s1.acc: 95.1050, s1.loss_bbox: 0.0743, s2.loss_cls: 0.0600, s2.acc: 96.1426, s2.loss_bbox: 0.0394, loss: 0.6387
2022-12-05 15:49:32,872 - mmdet - INFO - Epoch [14][1/4] lr: 1.865e-04, eta: 0:01:27, time: 2.613, data_time: 2.320, memory: 6815, loss_rpn_cls: 0.0243, loss_rpn_bbox: 0.0086, s0.loss_cls: 0.2788, s0.acc: 94.1895, s0.loss_bbox: 0.0980, s1.loss_cls: 0.1281, s1.acc: 95.0195, s1.loss_bbox: 0.0600, s2.loss_cls: 0.0572, s2.acc: 95.8496, s2.loss_bbox: 0.0298, loss: 0.6848
2022-12-05 15:49:33,163 - mmdet - INFO - Epoch [14][2/4] lr: 1.874e-04, eta: 0:01:25, time: 0.292, data_time: 0.047, memory: 6815, loss_rpn_cls: 0.0037, loss_rpn_bbox: 0.0068, s0.loss_cls: 0.0916, s0.acc: 97.9492, s0.loss_bbox: 0.0468, s1.loss_cls: 0.0565, s1.acc: 98.0469, s1.loss_bbox: 0.0293, s2.loss_cls: 0.0266, s2.acc: 98.4375, s2.loss_bbox: 0.0080, loss: 0.2694
2022-12-05 15:49:33,444 - mmdet - INFO - Epoch [14][3/4] lr: 1.882e-04, eta: 0:01:23, time: 0.279, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0231, loss_rpn_bbox: 0.0124, s0.loss_cls: 0.2777, s0.acc: 94.2383, s0.loss_bbox: 0.0871, s1.loss_cls: 0.1376, s1.acc: 94.5801, s1.loss_bbox: 0.0759, s2.loss_cls: 0.0623, s2.acc: 96.2891, s2.loss_bbox: 0.0212, loss: 0.6973
2022-12-05 15:49:33,718 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:33,719 - mmdet - INFO - Epoch [14][4/4] lr: 1.889e-04, eta: 0:01:21, time: 0.276, data_time: 0.042, memory: 6815, loss_rpn_cls: 0.0359, loss_rpn_bbox: 0.0073, s0.loss_cls: 0.1686, s0.acc: 96.6309, s0.loss_bbox: 0.0599, s1.loss_cls: 0.0879, s1.acc: 96.6309, s1.loss_bbox: 0.0501, s2.loss_cls: 0.0424, s2.acc: 96.9238, s2.loss_bbox: 0.0184, loss: 0.4705
2022-12-05 15:49:36,893 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:36,894 - mmdet - INFO - Epoch(val) [14][4] loss_rpn_cls: 0.0384, loss_rpn_bbox: 0.0100, s0.loss_cls: 0.2092, s0.acc: 95.8496, s0.loss_bbox: 0.0602, s1.loss_cls: 0.1190, s1.acc: 95.6909, s1.loss_bbox: 0.0676, s2.loss_cls: 0.0506, s2.acc: 96.7773, s2.loss_bbox: 0.0324, loss: 0.5874
2022-12-05 15:49:39,556 - mmdet - INFO - Epoch [15][1/4] lr: 1.894e-04, eta: 0:01:22, time: 2.621, data_time: 2.338, memory: 6815, loss_rpn_cls: 0.0342, loss_rpn_bbox: 0.0066, s0.loss_cls: 0.2071, s0.acc: 95.7520, s0.loss_bbox: 0.0581, s1.loss_cls: 0.1118, s1.acc: 95.7520, s1.loss_bbox: 0.0518, s2.loss_cls: 0.0494, s2.acc: 96.5332, s2.loss_bbox: 0.0230, loss: 0.5420
2022-12-05 15:49:39,838 - mmdet - INFO - Epoch [15][2/4] lr: 1.898e-04, eta: 0:01:20, time: 0.283, data_time: 0.047, memory: 6815, loss_rpn_cls: 0.0231, loss_rpn_bbox: 0.0066, s0.loss_cls: 0.2968, s0.acc: 92.9199, s0.loss_bbox: 0.1189, s1.loss_cls: 0.1433, s1.acc: 93.6523, s1.loss_bbox: 0.0924, s2.loss_cls: 0.0650, s2.acc: 95.2637, s2.loss_bbox: 0.0273, loss: 0.7734
2022-12-05 15:49:40,113 - mmdet - INFO - Epoch [15][3/4] lr: 1.900e-04, eta: 0:01:19, time: 0.275, data_time: 0.039, memory: 6815, loss_rpn_cls: 0.0098, loss_rpn_bbox: 0.0070, s0.loss_cls: 0.0883, s0.acc: 97.9980, s0.loss_bbox: 0.0435, s1.loss_cls: 0.0572, s1.acc: 97.9492, s1.loss_bbox: 0.0329, s2.loss_cls: 0.0252, s2.acc: 98.4375, s2.loss_bbox: 0.0050, loss: 0.2689
2022-12-05 15:49:40,392 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:40,392 - mmdet - INFO - Epoch [15][4/4] lr: 1.902e-04, eta: 0:01:17, time: 0.277, data_time: 0.039, memory: 6815, loss_rpn_cls: 0.0266, loss_rpn_bbox: 0.0113, s0.loss_cls: 0.1919, s0.acc: 96.5332, s0.loss_bbox: 0.0387, s1.loss_cls: 0.1102, s1.acc: 96.0449, s1.loss_bbox: 0.0441, s2.loss_cls: 0.0516, s2.acc: 96.7285, s2.loss_bbox: 0.0247, loss: 0.4991
2022-12-05 15:49:43,578 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:43,578 - mmdet - INFO - Epoch(val) [15][4] loss_rpn_cls: 0.0284, loss_rpn_bbox: 0.0087, s0.loss_cls: 0.2281, s0.acc: 95.3491, s0.loss_bbox: 0.0706, s1.loss_cls: 0.1264, s1.acc: 95.3613, s1.loss_bbox: 0.0722, s2.loss_cls: 0.0539, s2.acc: 96.3623, s2.loss_bbox: 0.0370, loss: 0.6253
2022-12-05 15:49:46,235 - mmdet - INFO - Epoch [16][1/4] lr: 1.902e-04, eta: 0:01:18, time: 2.617, data_time: 2.320, memory: 6815, loss_rpn_cls: 0.0186, loss_rpn_bbox: 0.0119, s0.loss_cls: 0.3143, s0.acc: 92.8711, s0.loss_bbox: 0.1091, s1.loss_cls: 0.1505, s1.acc: 93.5547, s1.loss_bbox: 0.0803, s2.loss_cls: 0.0711, s2.acc: 94.7266, s2.loss_bbox: 0.0314, loss: 0.7872
2022-12-05 15:49:46,518 - mmdet - INFO - Epoch [16][2/4] lr: 1.901e-04, eta: 0:01:16, time: 0.286, data_time: 0.048, memory: 6815, loss_rpn_cls: 0.0227, loss_rpn_bbox: 0.0064, s0.loss_cls: 0.1950, s0.acc: 96.0938, s0.loss_bbox: 0.0536, s1.loss_cls: 0.1037, s1.acc: 96.0938, s1.loss_bbox: 0.0619, s2.loss_cls: 0.0465, s2.acc: 97.0703, s2.loss_bbox: 0.0213, loss: 0.5112
2022-12-05 15:49:46,806 - mmdet - INFO - Epoch [16][3/4] lr: 1.899e-04, eta: 0:01:14, time: 0.284, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0070, loss_rpn_bbox: 0.0063, s0.loss_cls: 0.1729, s0.acc: 96.7773, s0.loss_bbox: 0.0290, s1.loss_cls: 0.0981, s1.acc: 96.4355, s1.loss_bbox: 0.0340, s2.loss_cls: 0.0462, s2.acc: 96.9727, s2.loss_bbox: 0.0193, loss: 0.4127
2022-12-05 15:49:47,080 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:47,081 - mmdet - INFO - Epoch [16][4/4] lr: 1.895e-04, eta: 0:01:13, time: 0.277, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0070, loss_rpn_bbox: 0.0071, s0.loss_cls: 0.0837, s0.acc: 98.0469, s0.loss_bbox: 0.0391, s1.loss_cls: 0.0533, s1.acc: 98.0957, s1.loss_bbox: 0.0271, s2.loss_cls: 0.0240, s2.acc: 98.4863, s2.loss_bbox: 0.0040, loss: 0.2453
2022-12-05 15:49:47,197 - mmdet - INFO - Saving checkpoint at 16 epochs
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 13/13, 15.9 task/s, elapsed: 1s, ETA: 0s2022-12-05 15:49:49,578 - mmdet - INFO - Evaluating bbox...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:49:49,591 - mmdet - INFO -
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.001
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.005
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.004
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.050
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.050
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.050
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.075
2022-12-05 15:49:49,591 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:49,591 - mmdet - INFO - Epoch(val) [16][13] bbox_mAP: 0.0010, bbox_mAP_50: 0.0050, bbox_mAP_75: 0.0000, bbox_mAP_s: -1.0000, bbox_mAP_m: 0.0000, bbox_mAP_l: 0.0040, bbox_mAP_copypaste: 0.001 0.005 0.000 -1.000 0.000 0.004
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:49:57,221 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:49:57,222 - mmdet - INFO - Epoch(val) [16][4] loss_rpn_cls: 0.0332, loss_rpn_bbox: 0.0102, s0.loss_cls: 0.2187, s0.acc: 95.5200, s0.loss_bbox: 0.0665, s1.loss_cls: 0.1249, s1.acc: 95.3491, s1.loss_bbox: 0.0736, s2.loss_cls: 0.0512, s2.acc: 96.5698, s2.loss_bbox: 0.0342, loss: 0.6124
2022-12-05 15:50:00,019 - mmdet - INFO - Epoch [17][1/4] lr: 1.891e-04, eta: 0:01:14, time: 2.759, data_time: 2.356, memory: 6815, loss_rpn_cls: 0.0008, loss_rpn_bbox: 0.0064, s0.loss_cls: 0.0878, s0.acc: 97.9492, s0.loss_bbox: 0.0435, s1.loss_cls: 0.0623, s1.acc: 97.7051, s1.loss_bbox: 0.0403, s2.loss_cls: 0.0275, s2.acc: 98.1445, s2.loss_bbox: 0.0110, loss: 0.2796
2022-12-05 15:50:00,342 - mmdet - INFO - Epoch [17][2/4] lr: 1.885e-04, eta: 0:01:12, time: 0.286, data_time: 0.046, memory: 6815, loss_rpn_cls: 0.0329, loss_rpn_bbox: 0.0116, s0.loss_cls: 0.2265, s0.acc: 95.9473, s0.loss_bbox: 0.0509, s1.loss_cls: 0.1149, s1.acc: 95.9961, s1.loss_bbox: 0.0470, s2.loss_cls: 0.0537, s2.acc: 96.5332, s2.loss_bbox: 0.0284, loss: 0.5659
2022-12-05 15:50:00,657 - mmdet - INFO - Epoch [17][3/4] lr: 1.878e-04, eta: 0:01:11, time: 0.354, data_time: 0.076, memory: 6815, loss_rpn_cls: 0.0264, loss_rpn_bbox: 0.0066, s0.loss_cls: 0.2140, s0.acc: 95.3613, s0.loss_bbox: 0.0540, s1.loss_cls: 0.1152, s1.acc: 95.1172, s1.loss_bbox: 0.0468, s2.loss_cls: 0.0548, s2.acc: 95.6055, s2.loss_bbox: 0.0219, loss: 0.5397
2022-12-05 15:50:01,030 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:01,031 - mmdet - INFO - Epoch [17][4/4] lr: 1.869e-04, eta: 0:01:09, time: 0.370, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0259, loss_rpn_bbox: 0.0082, s0.loss_cls: 0.2148, s0.acc: 94.7266, s0.loss_bbox: 0.0823, s1.loss_cls: 0.1164, s1.acc: 95.0195, s1.loss_bbox: 0.0789, s2.loss_cls: 0.0527, s2.acc: 96.4355, s2.loss_bbox: 0.0249, loss: 0.6040
2022-12-05 15:50:04,478 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:04,479 - mmdet - INFO - Epoch(val) [17][4] loss_rpn_cls: 0.0227, loss_rpn_bbox: 0.0088, s0.loss_cls: 0.2356, s0.acc: 95.0439, s0.loss_bbox: 0.0698, s1.loss_cls: 0.1437, s1.acc: 94.5679, s1.loss_bbox: 0.0816, s2.loss_cls: 0.0589, s2.acc: 95.8130, s2.loss_bbox: 0.0426, loss: 0.6637
2022-12-05 15:50:07,195 - mmdet - INFO - Epoch [18][1/4] lr: 1.860e-04, eta: 0:01:10, time: 2.639, data_time: 2.359, memory: 6815, loss_rpn_cls: 0.0122, loss_rpn_bbox: 0.0092, s0.loss_cls: 0.2953, s0.acc: 92.7734, s0.loss_bbox: 0.1207, s1.loss_cls: 0.1490, s1.acc: 93.2617, s1.loss_bbox: 0.1015, s2.loss_cls: 0.0616, s2.acc: 95.1172, s2.loss_bbox: 0.0237, loss: 0.7732
2022-12-05 15:50:07,540 - mmdet - INFO - Epoch [18][2/4] lr: 1.849e-04, eta: 0:01:09, time: 0.370, data_time: 0.084, memory: 6815, loss_rpn_cls: 0.0099, loss_rpn_bbox: 0.0060, s0.loss_cls: 0.1950, s0.acc: 95.9961, s0.loss_bbox: 0.0355, s1.loss_cls: 0.1116, s1.acc: 95.7031, s1.loss_bbox: 0.0449, s2.loss_cls: 0.0557, s2.acc: 96.1426, s2.loss_bbox: 0.0273, loss: 0.4858
2022-12-05 15:50:07,925 - mmdet - INFO - Epoch [18][3/4] lr: 1.838e-04, eta: 0:01:07, time: 0.375, data_time: 0.052, memory: 6815, loss_rpn_cls: 0.0181, loss_rpn_bbox: 0.0104, s0.loss_cls: 0.2079, s0.acc: 95.2148, s0.loss_bbox: 0.0666, s1.loss_cls: 0.1077, s1.acc: 95.4590, s1.loss_bbox: 0.0671, s2.loss_cls: 0.0472, s2.acc: 96.8262, s2.loss_bbox: 0.0215, loss: 0.5465
2022-12-05 15:50:08,211 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:08,212 - mmdet - INFO - Epoch [18][4/4] lr: 1.825e-04, eta: 0:01:06, time: 0.310, data_time: 0.064, memory: 6815, loss_rpn_cls: 0.0029, loss_rpn_bbox: 0.0067, s0.loss_cls: 0.0798, s0.acc: 98.0469, s0.loss_bbox: 0.0358, s1.loss_cls: 0.0589, s1.acc: 97.7539, s1.loss_bbox: 0.0370, s2.loss_cls: 0.0256, s2.acc: 98.2422, s2.loss_bbox: 0.0061, loss: 0.2529
2022-12-05 15:50:11,563 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:11,564 - mmdet - INFO - Epoch(val) [18][4] loss_rpn_cls: 0.0300, loss_rpn_bbox: 0.0087, s0.loss_cls: 0.2110, s0.acc: 95.5566, s0.loss_bbox: 0.0583, s1.loss_cls: 0.1253, s1.acc: 95.1904, s1.loss_bbox: 0.0712, s2.loss_cls: 0.0534, s2.acc: 96.2646, s2.loss_bbox: 0.0362, loss: 0.5942
2022-12-05 15:50:14,366 - mmdet - INFO - Epoch [19][1/4] lr: 1.811e-04, eta: 0:01:06, time: 2.754, data_time: 2.359, memory: 6815, loss_rpn_cls: 0.0262, loss_rpn_bbox: 0.0084, s0.loss_cls: 0.1698, s0.acc: 96.5820, s0.loss_bbox: 0.0342, s1.loss_cls: 0.0967, s1.acc: 96.3867, s1.loss_bbox: 0.0441, s2.loss_cls: 0.0466, s2.acc: 96.8750, s2.loss_bbox: 0.0280, loss: 0.4539
2022-12-05 15:50:14,662 - mmdet - INFO - Epoch [19][2/4] lr: 1.796e-04, eta: 0:01:05, time: 0.279, data_time: 0.046, memory: 6815, loss_rpn_cls: 0.0190, loss_rpn_bbox: 0.0098, s0.loss_cls: 0.2983, s0.acc: 92.9688, s0.loss_bbox: 0.1024, s1.loss_cls: 0.1646, s1.acc: 92.7734, s1.loss_bbox: 0.0945, s2.loss_cls: 0.0677, s2.acc: 94.6777, s2.loss_bbox: 0.0256, loss: 0.7820
2022-12-05 15:50:14,997 - mmdet - INFO - Epoch [19][3/4] lr: 1.780e-04, eta: 0:01:03, time: 0.349, data_time: 0.065, memory: 6815, loss_rpn_cls: 0.0145, loss_rpn_bbox: 0.0037, s0.loss_cls: 0.2016, s0.acc: 94.6777, s0.loss_bbox: 0.0825, s1.loss_cls: 0.1152, s1.acc: 94.5801, s1.loss_bbox: 0.0930, s2.loss_cls: 0.0422, s2.acc: 96.3867, s2.loss_bbox: 0.0220, loss: 0.5747
2022-12-05 15:50:15,363 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:15,364 - mmdet - INFO - Epoch [19][4/4] lr: 1.762e-04, eta: 0:01:02, time: 0.376, data_time: 0.049, memory: 6815, loss_rpn_cls: 0.0081, loss_rpn_bbox: 0.0066, s0.loss_cls: 0.0873, s0.acc: 97.8516, s0.loss_bbox: 0.0449, s1.loss_cls: 0.0557, s1.acc: 97.8516, s1.loss_bbox: 0.0432, s2.loss_cls: 0.0224, s2.acc: 98.5352, s2.loss_bbox: 0.0042, loss: 0.2724
2022-12-05 15:50:18,769 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:18,770 - mmdet - INFO - Epoch(val) [19][4] loss_rpn_cls: 0.0245, loss_rpn_bbox: 0.0090, s0.loss_cls: 0.2190, s0.acc: 95.4834, s0.loss_bbox: 0.0644, s1.loss_cls: 0.1251, s1.acc: 95.2637, s1.loss_bbox: 0.0783, s2.loss_cls: 0.0487, s2.acc: 96.6431, s2.loss_bbox: 0.0362, loss: 0.6052
2022-12-05 15:50:21,510 - mmdet - INFO - Epoch [20][1/4] lr: 1.744e-04, eta: 0:01:03, time: 2.701, data_time: 2.335, memory: 6815, loss_rpn_cls: 0.0158, loss_rpn_bbox: 0.0059, s0.loss_cls: 0.1672, s0.acc: 97.2168, s0.loss_bbox: 0.0251, s1.loss_cls: 0.0908, s1.acc: 96.9238, s1.loss_bbox: 0.0338, s2.loss_cls: 0.0427, s2.acc: 97.5098, s2.loss_bbox: 0.0150, loss: 0.3963
2022-12-05 15:50:21,888 - mmdet - INFO - Epoch [20][2/4] lr: 1.725e-04, eta: 0:01:01, time: 0.378, data_time: 0.048, memory: 6815, loss_rpn_cls: 0.0166, loss_rpn_bbox: 0.0074, s0.loss_cls: 0.2853, s0.acc: 92.1875, s0.loss_bbox: 0.1046, s1.loss_cls: 0.1570, s1.acc: 92.3828, s1.loss_bbox: 0.0909, s2.loss_cls: 0.0687, s2.acc: 94.0918, s2.loss_bbox: 0.0371, loss: 0.7675
2022-12-05 15:50:22,179 - mmdet - INFO - Epoch [20][3/4] lr: 1.705e-04, eta: 0:01:00, time: 0.291, data_time: 0.042, memory: 6815, loss_rpn_cls: 0.0019, loss_rpn_bbox: 0.0061, s0.loss_cls: 0.0852, s0.acc: 97.8516, s0.loss_bbox: 0.0420, s1.loss_cls: 0.0578, s1.acc: 97.7539, s1.loss_bbox: 0.0392, s2.loss_cls: 0.0244, s2.acc: 98.3398, s2.loss_bbox: 0.0063, loss: 0.2630
2022-12-05 15:50:22,550 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:22,551 - mmdet - INFO - Epoch [20][4/4] lr: 1.684e-04, eta: 0:00:58, time: 0.373, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.0161, loss_rpn_bbox: 0.0106, s0.loss_cls: 0.1822, s0.acc: 96.6309, s0.loss_bbox: 0.0477, s1.loss_cls: 0.0966, s1.acc: 96.5820, s1.loss_bbox: 0.0496, s2.loss_cls: 0.0420, s2.acc: 97.4609, s2.loss_bbox: 0.0184, loss: 0.4632
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 13/13, 15.3 task/s, elapsed: 1s, ETA: 0s2022-12-05 15:50:23,578 - mmdet - INFO - Evaluating bbox...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:50:23,591 - mmdet - INFO -
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.002
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.008
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.006
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.050
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.050
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.050
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.075
2022-12-05 15:50:23,592 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:23,592 - mmdet - INFO - Epoch(val) [20][13] bbox_mAP: 0.0020, bbox_mAP_50: 0.0080, bbox_mAP_75: 0.0000, bbox_mAP_s: -1.0000, bbox_mAP_m: 0.0000, bbox_mAP_l: 0.0060, bbox_mAP_copypaste: 0.002 0.008 0.000 -1.000 0.000 0.006
2022-12-05 15:50:27,477 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:27,478 - mmdet - INFO - Epoch(val) [20][4] loss_rpn_cls: 0.0274, loss_rpn_bbox: 0.0088, s0.loss_cls: 0.2012, s0.acc: 95.8008, s0.loss_bbox: 0.0554, s1.loss_cls: 0.1190, s1.acc: 95.4956, s1.loss_bbox: 0.0681, s2.loss_cls: 0.0501, s2.acc: 96.5454, s2.loss_bbox: 0.0358, loss: 0.5657
2022-12-05 15:50:30,170 - mmdet - INFO - Epoch [21][1/4] lr: 1.661e-04, eta: 0:00:59, time: 2.644, data_time: 2.341, memory: 6815, loss_rpn_cls: 0.0269, loss_rpn_bbox: 0.0114, s0.loss_cls: 0.2698, s0.acc: 93.7012, s0.loss_bbox: 0.0910, s1.loss_cls: 0.1385, s1.acc: 94.0430, s1.loss_bbox: 0.0787, s2.loss_cls: 0.0609, s2.acc: 95.6055, s2.loss_bbox: 0.0291, loss: 0.7063
2022-12-05 15:50:30,542 - mmdet - INFO - Epoch [21][2/4] lr: 1.638e-04, eta: 0:00:57, time: 0.361, data_time: 0.048, memory: 6815, loss_rpn_cls: 0.0055, loss_rpn_bbox: 0.0057, s0.loss_cls: 0.0827, s0.acc: 97.8516, s0.loss_bbox: 0.0391, s1.loss_cls: 0.0558, s1.acc: 97.8516, s1.loss_bbox: 0.0323, s2.loss_cls: 0.0245, s2.acc: 98.3398, s2.loss_bbox: 0.0048, loss: 0.2504
2022-12-05 15:50:30,821 - mmdet - INFO - Epoch [21][3/4] lr: 1.615e-04, eta: 0:00:56, time: 0.299, data_time: 0.057, memory: 6815, loss_rpn_cls: 0.0186, loss_rpn_bbox: 0.0050, s0.loss_cls: 0.2826, s0.acc: 92.0410, s0.loss_bbox: 0.1093, s1.loss_cls: 0.1670, s1.acc: 91.6992, s1.loss_bbox: 0.0801, s2.loss_cls: 0.0776, s2.acc: 92.8711, s2.loss_bbox: 0.0267, loss: 0.7668
2022-12-05 15:50:31,191 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:31,192 - mmdet - INFO - Epoch [21][4/4] lr: 1.590e-04, eta: 0:00:55, time: 0.367, data_time: 0.039, memory: 6815, loss_rpn_cls: 0.0195, loss_rpn_bbox: 0.0054, s0.loss_cls: 0.1640, s0.acc: 96.1914, s0.loss_bbox: 0.0414, s1.loss_cls: 0.1004, s1.acc: 95.7520, s1.loss_bbox: 0.0632, s2.loss_cls: 0.0436, s2.acc: 96.9238, s2.loss_bbox: 0.0269, loss: 0.4644
2022-12-05 15:50:34,668 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:34,669 - mmdet - INFO - Epoch(val) [21][4] loss_rpn_cls: 0.0299, loss_rpn_bbox: 0.0090, s0.loss_cls: 0.2251, s0.acc: 95.1050, s0.loss_bbox: 0.0655, s1.loss_cls: 0.1356, s1.acc: 94.8608, s1.loss_bbox: 0.0770, s2.loss_cls: 0.0538, s2.acc: 96.2158, s2.loss_bbox: 0.0385, loss: 0.6345
2022-12-05 15:50:37,344 - mmdet - INFO - Epoch [22][1/4] lr: 1.564e-04, eta: 0:00:55, time: 2.634, data_time: 2.321, memory: 6815, loss_rpn_cls: 0.0008, loss_rpn_bbox: 0.0056, s0.loss_cls: 0.0802, s0.acc: 97.8516, s0.loss_bbox: 0.0367, s1.loss_cls: 0.0533, s1.acc: 97.9492, s1.loss_bbox: 0.0278, s2.loss_cls: 0.0242, s2.acc: 98.3887, s2.loss_bbox: 0.0048, loss: 0.2334
2022-12-05 15:50:37,693 - mmdet - INFO - Epoch [22][2/4] lr: 1.538e-04, eta: 0:00:54, time: 0.350, data_time: 0.042, memory: 6815, loss_rpn_cls: 0.0135, loss_rpn_bbox: 0.0072, s0.loss_cls: 0.2302, s0.acc: 94.9707, s0.loss_bbox: 0.0450, s1.loss_cls: 0.1331, s1.acc: 94.3359, s1.loss_bbox: 0.0530, s2.loss_cls: 0.0664, s2.acc: 94.8730, s2.loss_bbox: 0.0321, loss: 0.5804
2022-12-05 15:50:38,089 - mmdet - INFO - Epoch [22][3/4] lr: 1.511e-04, eta: 0:00:52, time: 0.394, data_time: 0.050, memory: 6815, loss_rpn_cls: 0.0062, loss_rpn_bbox: 0.0041, s0.loss_cls: 0.1464, s0.acc: 97.1680, s0.loss_bbox: 0.0377, s1.loss_cls: 0.0820, s1.acc: 97.1191, s1.loss_bbox: 0.0465, s2.loss_cls: 0.0378, s2.acc: 97.8027, s2.loss_bbox: 0.0191, loss: 0.3796
2022-12-05 15:50:38,508 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:38,509 - mmdet - INFO - Epoch [22][4/4] lr: 1.483e-04, eta: 0:00:51, time: 0.421, data_time: 0.044, memory: 6815, loss_rpn_cls: 0.0133, loss_rpn_bbox: 0.0118, s0.loss_cls: 0.2725, s0.acc: 92.9199, s0.loss_bbox: 0.0962, s1.loss_cls: 0.1510, s1.acc: 92.9688, s1.loss_bbox: 0.0763, s2.loss_cls: 0.0721, s2.acc: 93.8965, s2.loss_bbox: 0.0301, loss: 0.7233
2022-12-05 15:50:41,911 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:41,912 - mmdet - INFO - Epoch(val) [22][4] loss_rpn_cls: 0.0363, loss_rpn_bbox: 0.0101, s0.loss_cls: 0.1927, s0.acc: 95.9473, s0.loss_bbox: 0.0572, s1.loss_cls: 0.1064, s1.acc: 95.8984, s1.loss_bbox: 0.0618, s2.loss_cls: 0.0440, s2.acc: 96.9604, s2.loss_bbox: 0.0306, loss: 0.5390
2022-12-05 15:50:44,659 - mmdet - INFO - Epoch [23][1/4] lr: 1.454e-04, eta: 0:00:51, time: 2.709, data_time: 2.350, memory: 6815, loss_rpn_cls: 0.0101, loss_rpn_bbox: 0.0088, s0.loss_cls: 0.1867, s0.acc: 96.4355, s0.loss_bbox: 0.0531, s1.loss_cls: 0.0969, s1.acc: 96.4844, s1.loss_bbox: 0.0496, s2.loss_cls: 0.0434, s2.acc: 97.2168, s2.loss_bbox: 0.0208, loss: 0.4695
2022-12-05 15:50:45,020 - mmdet - INFO - Epoch [23][2/4] lr: 1.425e-04, eta: 0:00:50, time: 0.362, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.0113, loss_rpn_bbox: 0.0030, s0.loss_cls: 0.2192, s0.acc: 93.9941, s0.loss_bbox: 0.0618, s1.loss_cls: 0.1429, s1.acc: 93.0176, s1.loss_bbox: 0.0654, s2.loss_cls: 0.0694, s2.acc: 93.4570, s2.loss_bbox: 0.0329, loss: 0.6061
2022-12-05 15:50:45,403 - mmdet - INFO - Epoch [23][3/4] lr: 1.395e-04, eta: 0:00:49, time: 0.383, data_time: 0.038, memory: 6815, loss_rpn_cls: 0.0032, loss_rpn_bbox: 0.0056, s0.loss_cls: 0.0791, s0.acc: 97.8027, s0.loss_bbox: 0.0376, s1.loss_cls: 0.0557, s1.acc: 97.7539, s1.loss_bbox: 0.0313, s2.loss_cls: 0.0259, s2.acc: 98.1934, s2.loss_bbox: 0.0063, loss: 0.2447
2022-12-05 15:50:45,691 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:45,691 - mmdet - INFO - Epoch [23][4/4] lr: 1.365e-04, eta: 0:00:47, time: 0.286, data_time: 0.038, memory: 6815, loss_rpn_cls: 0.0168, loss_rpn_bbox: 0.0076, s0.loss_cls: 0.2383, s0.acc: 93.4082, s0.loss_bbox: 0.0688, s1.loss_cls: 0.1427, s1.acc: 93.1152, s1.loss_bbox: 0.0759, s2.loss_cls: 0.0699, s2.acc: 94.1406, s2.loss_bbox: 0.0430, loss: 0.6630
2022-12-05 15:50:49,016 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:49,017 - mmdet - INFO - Epoch(val) [23][4] loss_rpn_cls: 0.0311, loss_rpn_bbox: 0.0085, s0.loss_cls: 0.2233, s0.acc: 95.0928, s0.loss_bbox: 0.0671, s1.loss_cls: 0.1320, s1.acc: 94.9219, s1.loss_bbox: 0.0767, s2.loss_cls: 0.0513, s2.acc: 96.5210, s2.loss_bbox: 0.0337, loss: 0.6237
2022-12-05 15:50:51,748 - mmdet - INFO - Epoch [24][1/4] lr: 1.334e-04, eta: 0:00:47, time: 2.689, data_time: 2.336, memory: 6815, loss_rpn_cls: 0.0207, loss_rpn_bbox: 0.0086, s0.loss_cls: 0.2490, s0.acc: 93.4570, s0.loss_bbox: 0.0812, s1.loss_cls: 0.1479, s1.acc: 92.9688, s1.loss_bbox: 0.0814, s2.loss_cls: 0.0718, s2.acc: 93.8965, s2.loss_bbox: 0.0340, loss: 0.6946
2022-12-05 15:50:52,113 - mmdet - INFO - Epoch [24][2/4] lr: 1.302e-04, eta: 0:00:46, time: 0.367, data_time: 0.044, memory: 6815, loss_rpn_cls: 0.0081, loss_rpn_bbox: 0.0069, s0.loss_cls: 0.1981, s0.acc: 96.3379, s0.loss_bbox: 0.0337, s1.loss_cls: 0.1082, s1.acc: 95.8984, s1.loss_bbox: 0.0331, s2.loss_cls: 0.0559, s2.acc: 96.1426, s2.loss_bbox: 0.0188, loss: 0.4629
2022-12-05 15:50:52,467 - mmdet - INFO - Epoch [24][3/4] lr: 1.270e-04, eta: 0:00:45, time: 0.357, data_time: 0.043, memory: 6815, loss_rpn_cls: 0.0097, loss_rpn_bbox: 0.0071, s0.loss_cls: 0.2136, s0.acc: 94.8242, s0.loss_bbox: 0.0466, s1.loss_cls: 0.1303, s1.acc: 94.0918, s1.loss_bbox: 0.0638, s2.loss_cls: 0.0659, s2.acc: 94.6289, s2.loss_bbox: 0.0372, loss: 0.5741
2022-12-05 15:50:52,850 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:52,851 - mmdet - INFO - Epoch [24][4/4] lr: 1.238e-04, eta: 0:00:44, time: 0.383, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0065, loss_rpn_bbox: 0.0058, s0.loss_cls: 0.0636, s0.acc: 98.2422, s0.loss_bbox: 0.0245, s1.loss_cls: 0.0520, s1.acc: 97.9004, s1.loss_bbox: 0.0237, s2.loss_cls: 0.0256, s2.acc: 98.1934, s2.loss_bbox: 0.0048, loss: 0.2064
2022-12-05 15:50:52,952 - mmdet - INFO - Saving checkpoint at 24 epochs
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 13/13, 16.5 task/s, elapsed: 1s, ETA: 0s2022-12-05 15:50:55,284 - mmdet - INFO - Evaluating bbox...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:50:55,297 - mmdet - INFO -
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.006
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.015
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.010
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.067
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.067
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.067
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.100
2022-12-05 15:50:55,298 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:50:55,298 - mmdet - INFO - Epoch(val) [24][13] bbox_mAP: 0.0060, bbox_mAP_50: 0.0150, bbox_mAP_75: 0.0000, bbox_mAP_s: -1.0000, bbox_mAP_m: 0.0000, bbox_mAP_l: 0.0100, bbox_mAP_copypaste: 0.006 0.015 0.000 -1.000 0.000 0.010
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:51:02,977 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:02,978 - mmdet - INFO - Epoch(val) [24][4] loss_rpn_cls: 0.0309, loss_rpn_bbox: 0.0081, s0.loss_cls: 0.2139, s0.acc: 95.3857, s0.loss_bbox: 0.0605, s1.loss_cls: 0.1268, s1.acc: 95.1294, s1.loss_bbox: 0.0692, s2.loss_cls: 0.0538, s2.acc: 96.1548, s2.loss_bbox: 0.0382, loss: 0.6015
2022-12-05 15:51:05,661 - mmdet - INFO - Epoch [25][1/4] lr: 1.205e-04, eta: 0:00:44, time: 2.644, data_time: 2.372, memory: 6815, loss_rpn_cls: 0.0045, loss_rpn_bbox: 0.0052, s0.loss_cls: 0.0688, s0.acc: 98.0469, s0.loss_bbox: 0.0280, s1.loss_cls: 0.0536, s1.acc: 97.8516, s1.loss_bbox: 0.0234, s2.loss_cls: 0.0259, s2.acc: 98.1934, s2.loss_bbox: 0.0052, loss: 0.2146
2022-12-05 15:51:06,025 - mmdet - INFO - Epoch [25][2/4] lr: 1.172e-04, eta: 0:00:42, time: 0.362, data_time: 0.047, memory: 6815, loss_rpn_cls: 0.0246, loss_rpn_bbox: 0.0039, s0.loss_cls: 0.1940, s0.acc: 95.1172, s0.loss_bbox: 0.0455, s1.loss_cls: 0.1252, s1.acc: 94.1406, s1.loss_bbox: 0.0552, s2.loss_cls: 0.0631, s2.acc: 94.4336, s2.loss_bbox: 0.0371, loss: 0.5486
2022-12-05 15:51:06,396 - mmdet - INFO - Epoch [25][3/4] lr: 1.138e-04, eta: 0:00:41, time: 0.372, data_time: 0.043, memory: 6815, loss_rpn_cls: 0.0105, loss_rpn_bbox: 0.0096, s0.loss_cls: 0.2460, s0.acc: 93.5547, s0.loss_bbox: 0.0813, s1.loss_cls: 0.1370, s1.acc: 93.5547, s1.loss_bbox: 0.0871, s2.loss_cls: 0.0650, s2.acc: 94.9219, s2.loss_bbox: 0.0339, loss: 0.6704
2022-12-05 15:51:06,764 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:06,764 - mmdet - INFO - Epoch [25][4/4] lr: 1.105e-04, eta: 0:00:40, time: 0.370, data_time: 0.044, memory: 6815, loss_rpn_cls: 0.0087, loss_rpn_bbox: 0.0101, s0.loss_cls: 0.2271, s0.acc: 93.7988, s0.loss_bbox: 0.0754, s1.loss_cls: 0.1324, s1.acc: 93.4082, s1.loss_bbox: 0.0670, s2.loss_cls: 0.0629, s2.acc: 94.4824, s2.loss_bbox: 0.0281, loss: 0.6117
2022-12-05 15:51:10,088 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:10,089 - mmdet - INFO - Epoch(val) [25][4] loss_rpn_cls: 0.0273, loss_rpn_bbox: 0.0089, s0.loss_cls: 0.2135, s0.acc: 95.4346, s0.loss_bbox: 0.0681, s1.loss_cls: 0.1170, s1.acc: 95.4468, s1.loss_bbox: 0.0681, s2.loss_cls: 0.0476, s2.acc: 96.7285, s2.loss_bbox: 0.0316, loss: 0.5820
2022-12-05 15:51:12,809 - mmdet - INFO - Epoch [26][1/4] lr: 1.070e-04, eta: 0:00:40, time: 2.681, data_time: 2.318, memory: 6815, loss_rpn_cls: 0.0179, loss_rpn_bbox: 0.0070, s0.loss_cls: 0.1750, s0.acc: 95.8496, s0.loss_bbox: 0.0440, s1.loss_cls: 0.0988, s1.acc: 95.7520, s1.loss_bbox: 0.0537, s2.loss_cls: 0.0455, s2.acc: 96.4844, s2.loss_bbox: 0.0342, loss: 0.4761
2022-12-05 15:51:13,194 - mmdet - INFO - Epoch [26][2/4] lr: 1.036e-04, eta: 0:00:39, time: 0.385, data_time: 0.048, memory: 6815, loss_rpn_cls: 0.0136, loss_rpn_bbox: 0.0081, s0.loss_cls: 0.2066, s0.acc: 94.4336, s0.loss_bbox: 0.0761, s1.loss_cls: 0.1175, s1.acc: 94.2871, s1.loss_bbox: 0.0827, s2.loss_cls: 0.0563, s2.acc: 95.6055, s2.loss_bbox: 0.0361, loss: 0.5970
2022-12-05 15:51:13,561 - mmdet - INFO - Epoch [26][3/4] lr: 1.002e-04, eta: 0:00:38, time: 0.368, data_time: 0.039, memory: 6815, loss_rpn_cls: 0.0028, loss_rpn_bbox: 0.0053, s0.loss_cls: 0.0693, s0.acc: 97.9980, s0.loss_bbox: 0.0262, s1.loss_cls: 0.0524, s1.acc: 97.8516, s1.loss_bbox: 0.0253, s2.loss_cls: 0.0273, s2.acc: 98.0469, s2.loss_bbox: 0.0065, loss: 0.2152
2022-12-05 15:51:13,943 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:13,944 - mmdet - INFO - Epoch [26][4/4] lr: 9.671e-05, eta: 0:00:36, time: 0.380, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.0091, loss_rpn_bbox: 0.0066, s0.loss_cls: 0.1868, s0.acc: 95.8496, s0.loss_bbox: 0.0428, s1.loss_cls: 0.1113, s1.acc: 95.1660, s1.loss_bbox: 0.0335, s2.loss_cls: 0.0598, s2.acc: 95.1172, s2.loss_bbox: 0.0172, loss: 0.4671
2022-12-05 15:51:17,271 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:17,272 - mmdet - INFO - Epoch(val) [26][4] loss_rpn_cls: 0.0347, loss_rpn_bbox: 0.0098, s0.loss_cls: 0.2001, s0.acc: 95.6909, s0.loss_bbox: 0.0648, s1.loss_cls: 0.1052, s1.acc: 95.9229, s1.loss_bbox: 0.0571, s2.loss_cls: 0.0462, s2.acc: 96.8628, s2.loss_bbox: 0.0284, loss: 0.5463
2022-12-05 15:51:19,934 - mmdet - INFO - Epoch [27][1/4] lr: 9.325e-05, eta: 0:00:36, time: 2.622, data_time: 2.330, memory: 6815, loss_rpn_cls: 0.0199, loss_rpn_bbox: 0.0075, s0.loss_cls: 0.2316, s0.acc: 93.2129, s0.loss_bbox: 0.0854, s1.loss_cls: 0.1489, s1.acc: 92.4805, s1.loss_bbox: 0.0905, s2.loss_cls: 0.0654, s2.acc: 94.1895, s2.loss_bbox: 0.0340, loss: 0.6833
2022-12-05 15:51:20,306 - mmdet - INFO - Epoch [27][2/4] lr: 8.978e-05, eta: 0:00:35, time: 0.370, data_time: 0.039, memory: 6815, loss_rpn_cls: 0.0092, loss_rpn_bbox: 0.0072, s0.loss_cls: 0.1872, s0.acc: 96.5820, s0.loss_bbox: 0.0358, s1.loss_cls: 0.1004, s1.acc: 96.3379, s1.loss_bbox: 0.0318, s2.loss_cls: 0.0509, s2.acc: 96.6797, s2.loss_bbox: 0.0153, loss: 0.4379
2022-12-05 15:51:20,590 - mmdet - INFO - Epoch [27][3/4] lr: 8.631e-05, eta: 0:00:34, time: 0.284, data_time: 0.043, memory: 6815, loss_rpn_cls: 0.0149, loss_rpn_bbox: 0.0103, s0.loss_cls: 0.1801, s0.acc: 95.8984, s0.loss_bbox: 0.0331, s1.loss_cls: 0.1028, s1.acc: 95.6055, s1.loss_bbox: 0.0389, s2.loss_cls: 0.0531, s2.acc: 95.7031, s2.loss_bbox: 0.0329, loss: 0.4660
2022-12-05 15:51:20,952 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:20,953 - mmdet - INFO - Epoch [27][4/4] lr: 8.284e-05, eta: 0:00:33, time: 0.364, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0048, loss_rpn_bbox: 0.0055, s0.loss_cls: 0.0813, s0.acc: 97.6562, s0.loss_bbox: 0.0291, s1.loss_cls: 0.0575, s1.acc: 97.5586, s1.loss_bbox: 0.0240, s2.loss_cls: 0.0286, s2.acc: 97.9004, s2.loss_bbox: 0.0027, loss: 0.2336
2022-12-05 15:51:24,257 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:24,257 - mmdet - INFO - Epoch(val) [27][4] loss_rpn_cls: 0.0285, loss_rpn_bbox: 0.0093, s0.loss_cls: 0.1856, s0.acc: 95.9229, s0.loss_bbox: 0.0513, s1.loss_cls: 0.1068, s1.acc: 95.8374, s1.loss_bbox: 0.0566, s2.loss_cls: 0.0447, s2.acc: 96.8994, s2.loss_bbox: 0.0280, loss: 0.5107
2022-12-05 15:51:26,878 - mmdet - INFO - Epoch [28][1/4] lr: 7.939e-05, eta: 0:00:32, time: 2.582, data_time: 2.308, memory: 6815, loss_rpn_cls: 0.0303, loss_rpn_bbox: 0.0061, s0.loss_cls: 0.2405, s0.acc: 92.8223, s0.loss_bbox: 0.0767, s1.loss_cls: 0.1458, s1.acc: 92.4316, s1.loss_bbox: 0.0840, s2.loss_cls: 0.0760, s2.acc: 93.3594, s2.loss_bbox: 0.0525, loss: 0.7118
2022-12-05 15:51:27,263 - mmdet - INFO - Epoch [28][2/4] lr: 7.595e-05, eta: 0:00:31, time: 0.343, data_time: 0.045, memory: 6815, loss_rpn_cls: 0.0096, loss_rpn_bbox: 0.0061, s0.loss_cls: 0.1920, s0.acc: 95.7031, s0.loss_bbox: 0.0512, s1.loss_cls: 0.1035, s1.acc: 95.6055, s1.loss_bbox: 0.0387, s2.loss_cls: 0.0500, s2.acc: 95.9961, s2.loss_bbox: 0.0179, loss: 0.4690
2022-12-05 15:51:27,568 - mmdet - INFO - Epoch [28][3/4] lr: 7.252e-05, eta: 0:00:30, time: 0.348, data_time: 0.082, memory: 6815, loss_rpn_cls: 0.0007, loss_rpn_bbox: 0.0052, s0.loss_cls: 0.0719, s0.acc: 97.8027, s0.loss_bbox: 0.0313, s1.loss_cls: 0.0536, s1.acc: 97.7539, s1.loss_bbox: 0.0223, s2.loss_cls: 0.0274, s2.acc: 97.9980, s2.loss_bbox: 0.0064, loss: 0.2189
2022-12-05 15:51:27,930 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:27,931 - mmdet - INFO - Epoch [28][4/4] lr: 6.913e-05, eta: 0:00:29, time: 0.363, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.0112, loss_rpn_bbox: 0.0070, s0.loss_cls: 0.2250, s0.acc: 93.5059, s0.loss_bbox: 0.0694, s1.loss_cls: 0.1460, s1.acc: 92.5293, s1.loss_bbox: 0.0695, s2.loss_cls: 0.0753, s2.acc: 93.2617, s2.loss_bbox: 0.0296, loss: 0.6330
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 13/13, 16.5 task/s, elapsed: 1s, ETA: 0s2022-12-05 15:51:28,884 - mmdet - INFO - Evaluating bbox...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:51:28,899 - mmdet - INFO -
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.010
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.022
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.003
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.019
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.275
2022-12-05 15:51:28,900 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:28,900 - mmdet - INFO - Epoch(val) [28][13] bbox_mAP: 0.0100, bbox_mAP_50: 0.0220, bbox_mAP_75: 0.0030, bbox_mAP_s: -1.0000, bbox_mAP_m: 0.0000, bbox_mAP_l: 0.0190, bbox_mAP_copypaste: 0.010 0.022 0.003 -1.000 0.000 0.019
2022-12-05 15:51:32,701 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:32,701 - mmdet - INFO - Epoch(val) [28][4] loss_rpn_cls: 0.0183, loss_rpn_bbox: 0.0078, s0.loss_cls: 0.2257, s0.acc: 95.0317, s0.loss_bbox: 0.0690, s1.loss_cls: 0.1306, s1.acc: 94.9585, s1.loss_bbox: 0.0720, s2.loss_cls: 0.0561, s2.acc: 96.0693, s2.loss_bbox: 0.0376, loss: 0.6171
2022-12-05 15:51:35,360 - mmdet - INFO - Epoch [29][1/4] lr: 6.575e-05, eta: 0:00:29, time: 2.620, data_time: 2.346, memory: 6815, loss_rpn_cls: 0.0138, loss_rpn_bbox: 0.0065, s0.loss_cls: 0.1967, s0.acc: 95.0195, s0.loss_bbox: 0.0474, s1.loss_cls: 0.1201, s1.acc: 94.3848, s1.loss_bbox: 0.0534, s2.loss_cls: 0.0653, s2.acc: 94.4824, s2.loss_bbox: 0.0374, loss: 0.5406
2022-12-05 15:51:35,751 - mmdet - INFO - Epoch [29][2/4] lr: 6.242e-05, eta: 0:00:28, time: 0.389, data_time: 0.039, memory: 6815, loss_rpn_cls: 0.0135, loss_rpn_bbox: 0.0091, s0.loss_cls: 0.2023, s0.acc: 94.8730, s0.loss_bbox: 0.0563, s1.loss_cls: 0.1148, s1.acc: 94.6777, s1.loss_bbox: 0.0617, s2.loss_cls: 0.0583, s2.acc: 95.5566, s2.loss_bbox: 0.0320, loss: 0.5481
2022-12-05 15:51:36,046 - mmdet - INFO - Epoch [29][3/4] lr: 5.911e-05, eta: 0:00:26, time: 0.293, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0052, loss_rpn_bbox: 0.0051, s0.loss_cls: 0.2168, s0.acc: 93.4570, s0.loss_bbox: 0.0789, s1.loss_cls: 0.1441, s1.acc: 92.6270, s1.loss_bbox: 0.0876, s2.loss_cls: 0.0679, s2.acc: 93.8965, s2.loss_bbox: 0.0379, loss: 0.6436
2022-12-05 15:51:36,376 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:36,377 - mmdet - INFO - Epoch [29][4/4] lr: 5.585e-05, eta: 0:00:25, time: 0.296, data_time: 0.042, memory: 6815, loss_rpn_cls: 0.0076, loss_rpn_bbox: 0.0054, s0.loss_cls: 0.0696, s0.acc: 97.8516, s0.loss_bbox: 0.0279, s1.loss_cls: 0.0488, s1.acc: 97.9492, s1.loss_bbox: 0.0166, s2.loss_cls: 0.0283, s2.acc: 97.8516, s2.loss_bbox: 0.0096, loss: 0.2137
2022-12-05 15:51:39,722 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:39,723 - mmdet - INFO - Epoch(val) [29][4] loss_rpn_cls: 0.0364, loss_rpn_bbox: 0.0092, s0.loss_cls: 0.2019, s0.acc: 95.6177, s0.loss_bbox: 0.0588, s1.loss_cls: 0.1168, s1.acc: 95.4712, s1.loss_bbox: 0.0633, s2.loss_cls: 0.0500, s2.acc: 96.5454, s2.loss_bbox: 0.0327, loss: 0.5692
2022-12-05 15:51:42,487 - mmdet - INFO - Epoch [30][1/4] lr: 5.264e-05, eta: 0:00:25, time: 2.711, data_time: 2.350, memory: 6815, loss_rpn_cls: 0.0108, loss_rpn_bbox: 0.0069, s0.loss_cls: 0.1342, s0.acc: 97.4121, s0.loss_bbox: 0.0284, s1.loss_cls: 0.0751, s1.acc: 97.3633, s1.loss_bbox: 0.0371, s2.loss_cls: 0.0339, s2.acc: 97.9980, s2.loss_bbox: 0.0168, loss: 0.3431
2022-12-05 15:51:42,854 - mmdet - INFO - Epoch [30][2/4] lr: 4.948e-05, eta: 0:00:24, time: 0.376, data_time: 0.051, memory: 6815, loss_rpn_cls: 0.0279, loss_rpn_bbox: 0.0083, s0.loss_cls: 0.1494, s0.acc: 96.7773, s0.loss_bbox: 0.0326, s1.loss_cls: 0.0969, s1.acc: 95.9961, s1.loss_bbox: 0.0397, s2.loss_cls: 0.0514, s2.acc: 95.9473, s2.loss_bbox: 0.0280, loss: 0.4340
2022-12-05 15:51:43,224 - mmdet - INFO - Epoch [30][3/4] lr: 4.637e-05, eta: 0:00:23, time: 0.354, data_time: 0.042, memory: 6815, loss_rpn_cls: 0.0038, loss_rpn_bbox: 0.0051, s0.loss_cls: 0.0708, s0.acc: 97.8027, s0.loss_bbox: 0.0305, s1.loss_cls: 0.0515, s1.acc: 97.8516, s1.loss_bbox: 0.0208, s2.loss_cls: 0.0272, s2.acc: 97.9980, s2.loss_bbox: 0.0096, loss: 0.2194
2022-12-05 15:51:43,506 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:43,506 - mmdet - INFO - Epoch [30][4/4] lr: 4.332e-05, eta: 0:00:22, time: 0.300, data_time: 0.057, memory: 6815, loss_rpn_cls: 0.0140, loss_rpn_bbox: 0.0090, s0.loss_cls: 0.2600, s0.acc: 92.6270, s0.loss_bbox: 0.0613, s1.loss_cls: 0.1658, s1.acc: 91.2598, s1.loss_bbox: 0.0774, s2.loss_cls: 0.0882, s2.acc: 91.8457, s2.loss_bbox: 0.0485, loss: 0.7243
2022-12-05 15:51:46,856 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:46,856 - mmdet - INFO - Epoch(val) [30][4] loss_rpn_cls: 0.0256, loss_rpn_bbox: 0.0079, s0.loss_cls: 0.2169, s0.acc: 95.1294, s0.loss_bbox: 0.0647, s1.loss_cls: 0.1261, s1.acc: 95.0317, s1.loss_bbox: 0.0701, s2.loss_cls: 0.0512, s2.acc: 96.3623, s2.loss_bbox: 0.0318, loss: 0.5945
2022-12-05 15:51:49,675 - mmdet - INFO - Epoch [31][1/4] lr: 4.034e-05, eta: 0:00:21, time: 2.772, data_time: 2.406, memory: 6815, loss_rpn_cls: 0.0061, loss_rpn_bbox: 0.0097, s0.loss_cls: 0.1573, s0.acc: 96.8262, s0.loss_bbox: 0.0350, s1.loss_cls: 0.0932, s1.acc: 96.4355, s1.loss_bbox: 0.0434, s2.loss_cls: 0.0449, s2.acc: 96.9238, s2.loss_bbox: 0.0215, loss: 0.4111
2022-12-05 15:51:50,055 - mmdet - INFO - Epoch [31][2/4] lr: 3.743e-05, eta: 0:00:20, time: 0.386, data_time: 0.049, memory: 6815, loss_rpn_cls: 0.0105, loss_rpn_bbox: 0.0061, s0.loss_cls: 0.2331, s0.acc: 92.8223, s0.loss_bbox: 0.0817, s1.loss_cls: 0.1436, s1.acc: 92.1875, s1.loss_bbox: 0.0931, s2.loss_cls: 0.0718, s2.acc: 93.3105, s2.loss_bbox: 0.0580, loss: 0.6981
2022-12-05 15:51:50,333 - mmdet - INFO - Epoch [31][3/4] lr: 3.459e-05, eta: 0:00:19, time: 0.280, data_time: 0.043, memory: 6815, loss_rpn_cls: 0.0161, loss_rpn_bbox: 0.0038, s0.loss_cls: 0.1903, s0.acc: 94.9707, s0.loss_bbox: 0.0393, s1.loss_cls: 0.1321, s1.acc: 93.5059, s1.loss_bbox: 0.0555, s2.loss_cls: 0.0686, s2.acc: 93.5547, s2.loss_bbox: 0.0419, loss: 0.5476
2022-12-05 15:51:50,708 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:50,708 - mmdet - INFO - Epoch [31][4/4] lr: 3.183e-05, eta: 0:00:18, time: 0.374, data_time: 0.039, memory: 6815, loss_rpn_cls: 0.0036, loss_rpn_bbox: 0.0053, s0.loss_cls: 0.0746, s0.acc: 97.6562, s0.loss_bbox: 0.0346, s1.loss_cls: 0.0563, s1.acc: 97.5586, s1.loss_bbox: 0.0211, s2.loss_cls: 0.0319, s2.acc: 97.5098, s2.loss_bbox: 0.0101, loss: 0.2376
2022-12-05 15:51:54,115 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:54,115 - mmdet - INFO - Epoch(val) [31][4] loss_rpn_cls: 0.0244, loss_rpn_bbox: 0.0085, s0.loss_cls: 0.2200, s0.acc: 95.1538, s0.loss_bbox: 0.0642, s1.loss_cls: 0.1282, s1.acc: 95.0073, s1.loss_bbox: 0.0725, s2.loss_cls: 0.0515, s2.acc: 96.3623, s2.loss_bbox: 0.0367, loss: 0.6060
2022-12-05 15:51:56,918 - mmdet - INFO - Epoch [32][1/4] lr: 2.916e-05, eta: 0:00:17, time: 2.729, data_time: 2.379, memory: 6815, loss_rpn_cls: 0.0147, loss_rpn_bbox: 0.0038, s0.loss_cls: 0.1754, s0.acc: 95.2148, s0.loss_bbox: 0.0510, s1.loss_cls: 0.1072, s1.acc: 94.8242, s1.loss_bbox: 0.0667, s2.loss_cls: 0.0534, s2.acc: 95.3613, s2.loss_bbox: 0.0462, loss: 0.5184
2022-12-05 15:51:57,241 - mmdet - INFO - Epoch [32][2/4] lr: 2.657e-05, eta: 0:00:16, time: 0.355, data_time: 0.081, memory: 6815, loss_rpn_cls: 0.0164, loss_rpn_bbox: 0.0093, s0.loss_cls: 0.1573, s0.acc: 97.2168, s0.loss_bbox: 0.0251, s1.loss_cls: 0.0945, s1.acc: 96.5820, s1.loss_bbox: 0.0308, s2.loss_cls: 0.0503, s2.acc: 96.5820, s2.loss_bbox: 0.0219, loss: 0.4058
2022-12-05 15:51:57,597 - mmdet - INFO - Epoch [32][3/4] lr: 2.407e-05, eta: 0:00:15, time: 0.359, data_time: 0.041, memory: 6815, loss_rpn_cls: 0.0127, loss_rpn_bbox: 0.0060, s0.loss_cls: 0.2491, s0.acc: 92.3340, s0.loss_bbox: 0.0753, s1.loss_cls: 0.1594, s1.acc: 91.5039, s1.loss_bbox: 0.0861, s2.loss_cls: 0.0825, s2.acc: 92.2852, s2.loss_bbox: 0.0472, loss: 0.7183
2022-12-05 15:51:57,976 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:51:57,976 - mmdet - INFO - Epoch [32][4/4] lr: 2.168e-05, eta: 0:00:14, time: 0.343, data_time: 0.038, memory: 6815, loss_rpn_cls: 0.0050, loss_rpn_bbox: 0.0053, s0.loss_cls: 0.0746, s0.acc: 97.6562, s0.loss_bbox: 0.0344, s1.loss_cls: 0.0545, s1.acc: 97.6562, s1.loss_bbox: 0.0190, s2.loss_cls: 0.0318, s2.acc: 97.5098, s2.loss_bbox: 0.0092, loss: 0.2338
2022-12-05 15:51:58,062 - mmdet - INFO - Saving checkpoint at 32 epochs
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 13/13, 16.9 task/s, elapsed: 1s, ETA: 0s2022-12-05 15:52:00,425 - mmdet - INFO - Evaluating bbox...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:52:00,439 - mmdet - INFO -
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.011
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.024
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.004
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.020
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.275
2022-12-05 15:52:00,439 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:52:00,439 - mmdet - INFO - Epoch(val) [32][13] bbox_mAP: 0.0110, bbox_mAP_50: 0.0240, bbox_mAP_75: 0.0040, bbox_mAP_s: -1.0000, bbox_mAP_m: 0.0000, bbox_mAP_l: 0.0200, bbox_mAP_copypaste: 0.011 0.024 0.004 -1.000 0.000 0.020
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:52:08,097 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:52:08,097 - mmdet - INFO - Epoch(val) [32][4] loss_rpn_cls: 0.0293, loss_rpn_bbox: 0.0088, s0.loss_cls: 0.1947, s0.acc: 95.7886, s0.loss_bbox: 0.0578, s1.loss_cls: 0.1077, s1.acc: 95.7886, s1.loss_bbox: 0.0552, s2.loss_cls: 0.0488, s2.acc: 96.5454, s2.loss_bbox: 0.0322, loss: 0.5344
2022-12-05 15:52:10,854 - mmdet - INFO - Epoch [33][1/4] lr: 1.938e-05, eta: 0:00:14, time: 2.717, data_time: 2.326, memory: 6815, loss_rpn_cls: 0.0204, loss_rpn_bbox: 0.0091, s0.loss_cls: 0.2099, s0.acc: 94.6777, s0.loss_bbox: 0.0590, s1.loss_cls: 0.1213, s1.acc: 94.4824, s1.loss_bbox: 0.0654, s2.loss_cls: 0.0629, s2.acc: 95.2637, s2.loss_bbox: 0.0343, loss: 0.5823
2022-12-05 15:52:11,230 - mmdet - INFO - Epoch [33][2/4] lr: 1.719e-05, eta: 0:00:13, time: 0.379, data_time: 0.048, memory: 6815, loss_rpn_cls: 0.0101, loss_rpn_bbox: 0.0048, s0.loss_cls: 0.0743, s0.acc: 97.6562, s0.loss_bbox: 0.0365, s1.loss_cls: 0.0556, s1.acc: 97.6074, s1.loss_bbox: 0.0256, s2.loss_cls: 0.0313, s2.acc: 97.6074, s2.loss_bbox: 0.0124, loss: 0.2506
2022-12-05 15:52:11,631 - mmdet - INFO - Epoch [33][3/4] lr: 1.511e-05, eta: 0:00:12, time: 0.358, data_time: 0.039, memory: 6815, loss_rpn_cls: 0.0157, loss_rpn_bbox: 0.0086, s0.loss_cls: 0.2130, s0.acc: 94.1895, s0.loss_bbox: 0.0677, s1.loss_cls: 0.1320, s1.acc: 93.6035, s1.loss_bbox: 0.0709, s2.loss_cls: 0.0671, s2.acc: 94.5312, s2.loss_bbox: 0.0341, loss: 0.6090
2022-12-05 15:52:11,914 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:52:11,914 - mmdet - INFO - Epoch [33][4/4] lr: 1.315e-05, eta: 0:00:11, time: 0.326, data_time: 0.085, memory: 6815, loss_rpn_cls: 0.0121, loss_rpn_bbox: 0.0066, s0.loss_cls: 0.2169, s0.acc: 94.1895, s0.loss_bbox: 0.0483, s1.loss_cls: 0.1413, s1.acc: 92.9199, s1.loss_bbox: 0.0520, s2.loss_cls: 0.0762, s2.acc: 92.7734, s2.loss_bbox: 0.0376, loss: 0.5911
2022-12-05 15:52:15,136 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:52:15,136 - mmdet - INFO - Epoch(val) [33][4] loss_rpn_cls: 0.0285, loss_rpn_bbox: 0.0092, s0.loss_cls: 0.2004, s0.acc: 95.6299, s0.loss_bbox: 0.0589, s1.loss_cls: 0.1126, s1.acc: 95.6055, s1.loss_bbox: 0.0621, s2.loss_cls: 0.0497, s2.acc: 96.4600, s2.loss_bbox: 0.0342, loss: 0.5558
2022-12-05 15:52:17,892 - mmdet - INFO - Epoch [34][1/4] lr: 1.130e-05, eta: 0:00:10, time: 2.712, data_time: 2.354, memory: 6815, loss_rpn_cls: 0.0210, loss_rpn_bbox: 0.0075, s0.loss_cls: 0.1938, s0.acc: 95.1172, s0.loss_bbox: 0.0416, s1.loss_cls: 0.1225, s1.acc: 94.3359, s1.loss_bbox: 0.0612, s2.loss_cls: 0.0657, s2.acc: 94.5801, s2.loss_bbox: 0.0439, loss: 0.5573
2022-12-05 15:52:18,271 - mmdet - INFO - Epoch [34][2/4] lr: 9.581e-06, eta: 0:00:09, time: 0.384, data_time: 0.044, memory: 6815, loss_rpn_cls: 0.0059, loss_rpn_bbox: 0.0047, s0.loss_cls: 0.0750, s0.acc: 97.6562, s0.loss_bbox: 0.0364, s1.loss_cls: 0.0550, s1.acc: 97.6562, s1.loss_bbox: 0.0234, s2.loss_cls: 0.0283, s2.acc: 97.9004, s2.loss_bbox: 0.0097, loss: 0.2384
2022-12-05 15:52:18,576 - mmdet - INFO - Epoch [34][3/4] lr: 7.989e-06, eta: 0:00:08, time: 0.296, data_time: 0.038, memory: 6815, loss_rpn_cls: 0.0102, loss_rpn_bbox: 0.0051, s0.loss_cls: 0.1444, s0.acc: 96.5332, s0.loss_bbox: 0.0379, s1.loss_cls: 0.0896, s1.acc: 96.0449, s1.loss_bbox: 0.0524, s2.loss_cls: 0.0403, s2.acc: 97.0215, s2.loss_bbox: 0.0183, loss: 0.3982
2022-12-05 15:52:18,930 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:52:18,931 - mmdet - INFO - Epoch [34][4/4] lr: 6.529e-06, eta: 0:00:07, time: 0.358, data_time: 0.047, memory: 6815, loss_rpn_cls: 0.0084, loss_rpn_bbox: 0.0049, s0.loss_cls: 0.2162, s0.acc: 93.6523, s0.loss_bbox: 0.0654, s1.loss_cls: 0.1320, s1.acc: 93.1641, s1.loss_bbox: 0.0639, s2.loss_cls: 0.0669, s2.acc: 94.0430, s2.loss_bbox: 0.0273, loss: 0.5850
2022-12-05 15:52:22,292 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:52:22,292 - mmdet - INFO - Epoch(val) [34][4] loss_rpn_cls: 0.0291, loss_rpn_bbox: 0.0088, s0.loss_cls: 0.2241, s0.acc: 95.0317, s0.loss_bbox: 0.0713, s1.loss_cls: 0.1263, s1.acc: 95.0195, s1.loss_bbox: 0.0725, s2.loss_cls: 0.0513, s2.acc: 96.4111, s2.loss_bbox: 0.0336, loss: 0.6171
2022-12-05 15:52:25,051 - mmdet - INFO - Epoch [35][1/4] lr: 5.206e-06, eta: 0:00:06, time: 2.697, data_time: 2.322, memory: 6815, loss_rpn_cls: 0.0038, loss_rpn_bbox: 0.0047, s0.loss_cls: 0.0743, s0.acc: 97.6562, s0.loss_bbox: 0.0363, s1.loss_cls: 0.0537, s1.acc: 97.7051, s1.loss_bbox: 0.0249, s2.loss_cls: 0.0286, s2.acc: 97.8516, s2.loss_bbox: 0.0100, loss: 0.2364
2022-12-05 15:52:25,360 - mmdet - INFO - Epoch [35][2/4] lr: 4.024e-06, eta: 0:00:05, time: 0.332, data_time: 0.063, memory: 6815, loss_rpn_cls: 0.0126, loss_rpn_bbox: 0.0047, s0.loss_cls: 0.1713, s0.acc: 95.6055, s0.loss_bbox: 0.0356, s1.loss_cls: 0.1038, s1.acc: 95.1660, s1.loss_bbox: 0.0554, s2.loss_cls: 0.0515, s2.acc: 95.7520, s2.loss_bbox: 0.0383, loss: 0.4733
2022-12-05 15:52:25,711 - mmdet - INFO - Epoch [35][3/4] lr: 2.987e-06, eta: 0:00:04, time: 0.353, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.0097, loss_rpn_bbox: 0.0083, s0.loss_cls: 0.1730, s0.acc: 96.0938, s0.loss_bbox: 0.0408, s1.loss_cls: 0.1016, s1.acc: 95.7520, s1.loss_bbox: 0.0357, s2.loss_cls: 0.0551, s2.acc: 95.5566, s2.loss_bbox: 0.0234, loss: 0.4475
2022-12-05 15:52:25,985 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:52:25,985 - mmdet - INFO - Epoch [35][4/4] lr: 2.099e-06, eta: 0:00:03, time: 0.274, data_time: 0.039, memory: 6815, loss_rpn_cls: 0.0086, loss_rpn_bbox: 0.0107, s0.loss_cls: 0.2343, s0.acc: 93.4082, s0.loss_bbox: 0.0707, s1.loss_cls: 0.1417, s1.acc: 92.7734, s1.loss_bbox: 0.0655, s2.loss_cls: 0.0745, s2.acc: 93.3105, s2.loss_bbox: 0.0336, loss: 0.6396
2022-12-05 15:52:29,382 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:52:29,383 - mmdet - INFO - Epoch(val) [35][4] loss_rpn_cls: 0.0241, loss_rpn_bbox: 0.0079, s0.loss_cls: 0.2056, s0.acc: 95.4712, s0.loss_bbox: 0.0622, s1.loss_cls: 0.1157, s1.acc: 95.4224, s1.loss_bbox: 0.0659, s2.loss_cls: 0.0493, s2.acc: 96.4966, s2.loss_bbox: 0.0325, loss: 0.5631
2022-12-05 15:52:32,136 - mmdet - INFO - Epoch [36][1/4] lr: 1.363e-06, eta: 0:00:02, time: 2.707, data_time: 2.360, memory: 6815, loss_rpn_cls: 0.0140, loss_rpn_bbox: 0.0076, s0.loss_cls: 0.2066, s0.acc: 94.7266, s0.loss_bbox: 0.0488, s1.loss_cls: 0.1304, s1.acc: 93.8477, s1.loss_bbox: 0.0621, s2.loss_cls: 0.0727, s2.acc: 94.2871, s2.loss_bbox: 0.0355, loss: 0.5777
2022-12-05 15:52:32,523 - mmdet - INFO - Epoch [36][2/4] lr: 7.849e-07, eta: 0:00:01, time: 0.390, data_time: 0.051, memory: 6815, loss_rpn_cls: 0.0114, loss_rpn_bbox: 0.0082, s0.loss_cls: 0.2277, s0.acc: 93.8965, s0.loss_bbox: 0.0763, s1.loss_cls: 0.1298, s1.acc: 93.7988, s1.loss_bbox: 0.0745, s2.loss_cls: 0.0630, s2.acc: 94.9707, s2.loss_bbox: 0.0313, loss: 0.6221
2022-12-05 15:52:32,806 - mmdet - INFO - Epoch [36][3/4] lr: 3.672e-07, eta: 0:00:00, time: 0.289, data_time: 0.045, memory: 6815, loss_rpn_cls: 0.0017, loss_rpn_bbox: 0.0050, s0.loss_cls: 0.0744, s0.acc: 97.6562, s0.loss_bbox: 0.0352, s1.loss_cls: 0.0538, s1.acc: 97.7051, s1.loss_bbox: 0.0219, s2.loss_cls: 0.0291, s2.acc: 97.8027, s2.loss_bbox: 0.0090, loss: 0.2301
2022-12-05 15:52:33,172 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:52:33,172 - mmdet - INFO - Epoch [36][4/4] lr: 1.140e-07, eta: 0:00:00, time: 0.366, data_time: 0.040, memory: 6815, loss_rpn_cls: 0.0124, loss_rpn_bbox: 0.0038, s0.loss_cls: 0.1952, s0.acc: 94.7266, s0.loss_bbox: 0.0418, s1.loss_cls: 0.1295, s1.acc: 93.5547, s1.loss_bbox: 0.0518, s2.loss_cls: 0.0672, s2.acc: 93.6523, s2.loss_bbox: 0.0378, loss: 0.5396
2022-12-05 15:52:33,255 - mmdet - INFO - Saving checkpoint at 36 epochs
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 13/13, 15.7 task/s, elapsed: 1s, ETA: 0s2022-12-05 15:52:35,972 - mmdet - INFO - Evaluating bbox...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:52:35,986 - mmdet - INFO -
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.011
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.024
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.004
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.020
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.183
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.275
2022-12-05 15:52:35,987 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:52:35,987 - mmdet - INFO - Epoch(val) [36][13] bbox_mAP: 0.0110, bbox_mAP_50: 0.0240, bbox_mAP_75: 0.0040, bbox_mAP_s: -1.0000, bbox_mAP_m: 0.0000, bbox_mAP_l: 0.0200, bbox_mAP_copypaste: 0.011 0.024 0.004 -1.000 0.000 0.020
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.01s).
2022-12-05 15:52:43,714 - mmdet - INFO - Exp name: cascade_rcnn_r50_fpn_1x_coco.py
2022-12-05 15:52:43,716 - mmdet - INFO - Epoch(val) [36][4] loss_rpn_cls: 0.0342, loss_rpn_bbox: 0.0095, s0.loss_cls: 0.2102, s0.acc: 95.3979, s0.loss_bbox: 0.0675, s1.loss_cls: 0.1184, s1.acc: 95.3857, s1.loss_bbox: 0.0645, s2.loss_cls: 0.0515, s2.acc: 96.3501, s2.loss_bbox: 0.0344, loss: 0.5902
wandb: Waiting for W&B process to finish... (success). wandb: wandb: Run history: wandb: learning_rate ▁▂▂▃▄▄▅▅▆▆▇▇▇████████▇▇▇▆▆▆▅▅▄▄▃▃▂▂▂▁▁▁▁ wandb: momentum ▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁ wandb: train/loss ▇█▇▇▆▅▅▃▃▃▁▁▂▂▂▂▁▁▂▂▂▂▂▂▂▂▁▂▁▂▁▂▁▂▁▁▂▂▂▂ wandb: train/loss_rpn_bbox ▂▆▃▃▃▂█▂▆▇▃▃▂▂▄▅▃▂▅▂▄▃▄▂▅▃▂▄▂▄▂▄▃▂▄▂▂▂▄▁ wandb: train/loss_rpn_cls ▁▄▁▁▁▁█▁▆▆▁▁▂▂▂▂▁▁▂▁▂▂▂▂▁▂▁▁▁▂▁▁▂▁▂▁▁▁▁▁ wandb: train/s0.acc ▂▁▃▅████████████████████████████████████ wandb: train/s0.loss_bbox ▆▅▇▆▆▆▂▆▅▃▃▃▆▅▇▆▃▁▃▂██▃▂▇▅▁▆▁▂▂▄▂▆▁▂▃▅▅▃ wandb: train/s0.loss_cls ██▇▇▆▅▅▃▃▂▁▁▂▂▂▂▁▁▂▂▂▂▁▁▂▂▁▂▁▁▁▂▁▂▁▁▂▂▂▂ wandb: train/s1.acc ▁▁▂▃▆████████████████▇███████████▇██████ wandb: train/s1.loss_bbox ▂▄▁▁▁▁▂▂▃▁▁▁▅▄█▆▂▂▃▃▇▇▄▅▆▆▂▇▂▃▁▅▃▇▂▁▄▅▅▄ wandb: train/s1.loss_cls ███▇▇▆▆▄▃▃▂▁▂▁▂▂▁▁▁▁▂▂▁▁▂▂▁▂▁▁▁▁▁▂▁▁▂▂▂▂ wandb: train/s2.acc ▁▁▁▂▅▇██████████████████████████████████ wandb: train/s2.loss_bbox ▁▃▁▁▁▂▂▂▃▂▁▁▄▃▆▃▁▃▄▄▄▅▃▄▄▆▁▅▁▅▁▅▄█▃▂▅▄▅▅ wandb: train/s2.loss_cls ███▇▇▆▅▄▄▃▂▁▂▁▂▂▁▁▁▁▂▂▁▁▂▂▁▂▁▁▁▂▁▂▁▁▂▂▂▂ wandb: val/bbox_mAP ▂█▆▁▂▄▇▇▇ wandb: val/bbox_mAP_50 ▁█▅▁▂▄▆▆▆ wandb: val/bbox_mAP_75 ▇██▁▁▁▅▇▇ wandb: val/bbox_mAP_l ▂█▆▁▁▂▄▅▅ wandb: val/bbox_mAP_m ▁▁▁▁▁▁▁▁▁ wandb: val/bbox_mAP_s ▁▁▁▁▁▁▁▁▁ wandb: val/loss ██▇▅▄▃▂▂▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁ wandb: val/loss_rpn_bbox ▄▇▅█▆▆▅▆▇█▆▃▃▃▄▄▇▃▃▆▄▄▁▃▄▃▁ wandb: val/loss_rpn_cls ▅▇▅█▆▃▅▃▄▄▄▂▁▂▁▂▃▃▂▃▂▃▂▁▂▂▁ wandb: val/s0.acc ▁▂▅████████████████████████ wandb: val/s0.loss_bbox ▅▅▆▁▄▆▆█▂▄▃▆▆▃▄▅▃▅▅▅▁▃▅▄▃▆▄ wandb: val/s0.loss_cls ██▇▅▄▃▂▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁ wandb: val/s1.acc ▁▂▃████████████████████████ wandb: val/s1.loss_bbox █▄▅▂▅▆▆▆▄▆▄▅█▅▇▇▂▇▄▁▁▃▅▅▃▅▄ wandb: val/s1.loss_cls ██▇▅▄▄▂▂▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁ wandb: val/s2.acc ▁▁▃████████████████████████ wandb: val/s2.loss_bbox ▇▄▅▁▅▅▅▆▃▆▃▅█▅▅▆▂▄▃▁▁▃▃▅▄▄▃ wandb: val/s2.loss_cls ██▇▆▅▄▂▂▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁ wandb: wandb: Run summary: wandb: learning_rate 0.0 wandb: momentum 0.9 wandb: train/loss 0.53957 wandb: train/loss_rpn_bbox 0.00381 wandb: train/loss_rpn_cls 0.01236 wandb: train/s0.acc 94.72656 wandb: train/s0.loss_bbox 0.04182 wandb: train/s0.loss_cls 0.19517 wandb: train/s1.acc 93.55469 wandb: train/s1.loss_bbox 0.05181 wandb: train/s1.loss_cls 0.12954 wandb: train/s2.acc 93.65234 wandb: train/s2.loss_bbox 0.03782 wandb: train/s2.loss_cls 0.06725 wandb: val/bbox_mAP 0.011 wandb: val/bbox_mAP_50 0.024 wandb: val/bbox_mAP_75 0.004 wandb: val/bbox_mAP_l 0.02 wandb: val/bbox_mAP_m 0.0 wandb: val/bbox_mAP_s -1.0 wandb: val/loss 0.56313 wandb: val/loss_rpn_bbox 0.00792 wandb: val/loss_rpn_cls 0.02405 wandb: val/s0.acc 95.47119 wandb: val/s0.loss_bbox 0.06216 wandb: val/s0.loss_cls 0.20561 wandb: val/s1.acc 95.42236 wandb: val/s1.loss_bbox 0.0659 wandb: val/s1.loss_cls 0.11573 wandb: val/s2.acc 96.49658 wandb: val/s2.loss_bbox 0.0325 wandb: val/s2.loss_cls 0.04927 wandb:
Learning_rate (학습률, η , eta)
training 되는 양 또는 단계, 오류의 양을 추정,
미분 기울기의 이동 step
– lr값이 작다 = 기울기의 이동 step의 간격이 작아진다 = 학습속도가 느리다
= 학습의 반복수가적을 경우 Minima에 도달전에 끝날수 있음 = cost 값의 변화가 없는 경우
– lr값이 크다 = 기울기의 이동 step의 간격이 커진다 = 너무 값이 커지면 반대쪽 그래프로 이동하여 그래프를 벗어나는 결과 값을 도출될 수 있음(overshooting)
딥러닝 NN (Neural Networks)은 학습과정(weight를 조정하는 과정)에서 SGD알고리즘을 사용한다.
SGD(Stochastic gradient descent)는 Loss함수계산시 전체데이터(Batch)대신 일부데이터(Mini-Batch)를 사용하여
계산속도향상, 메모리부족해결한 알고리즘.
이를 여러번 수행하면 BGD (Batch gradient descent)로 수렴한고, 오히려 Local Minima에 빠지지 않고 더 좋은 방향으로 Global Minima에 수렴하는데 도움이 된다.
변형 알고리즘으로 Navice SGD, Momentum, NAG, Adagrad, AdaDelta, RMSprop등이 있다.
이런 SGD에서 가중치를 업데이트할때 사용되는 기준점 중 하나가 Learning rate이다.
정확한 기준점을 알고 있어야 정확도를 높일 수가 있다.
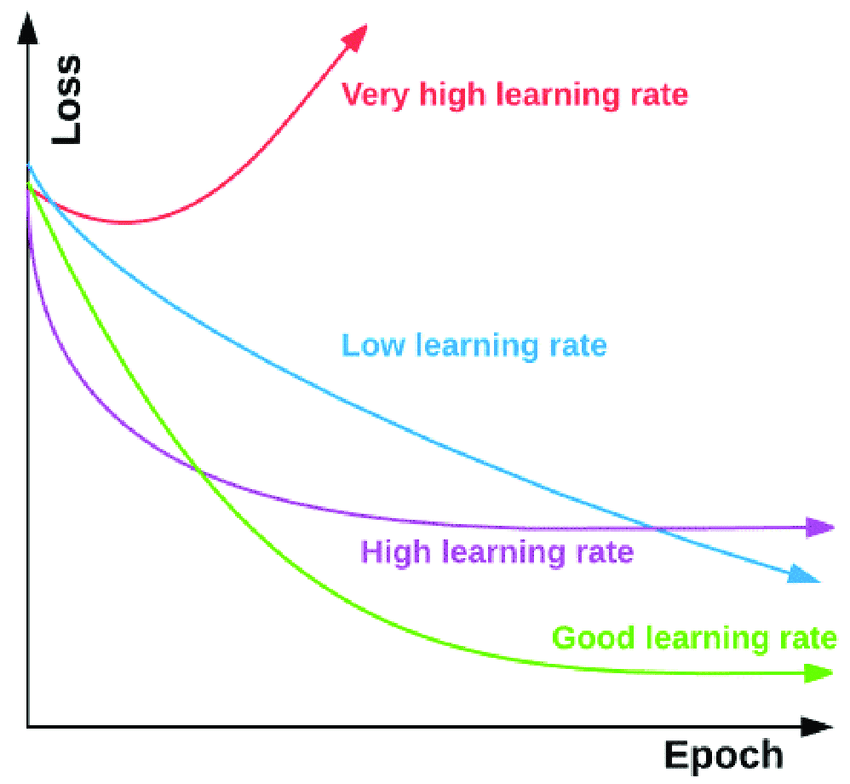
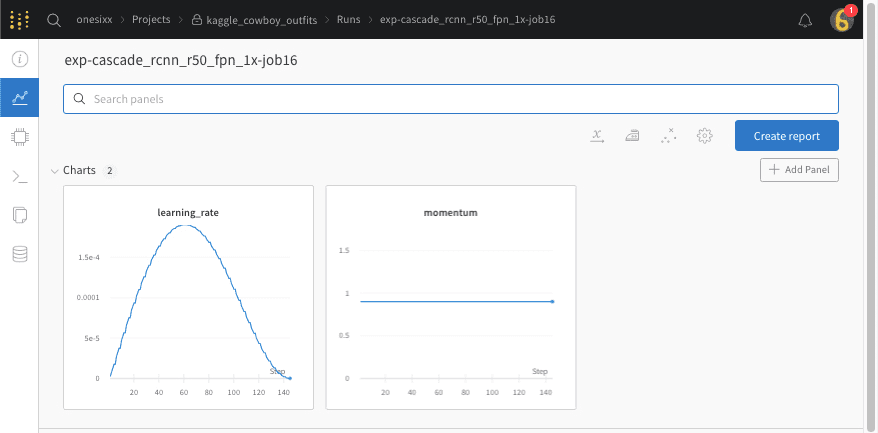
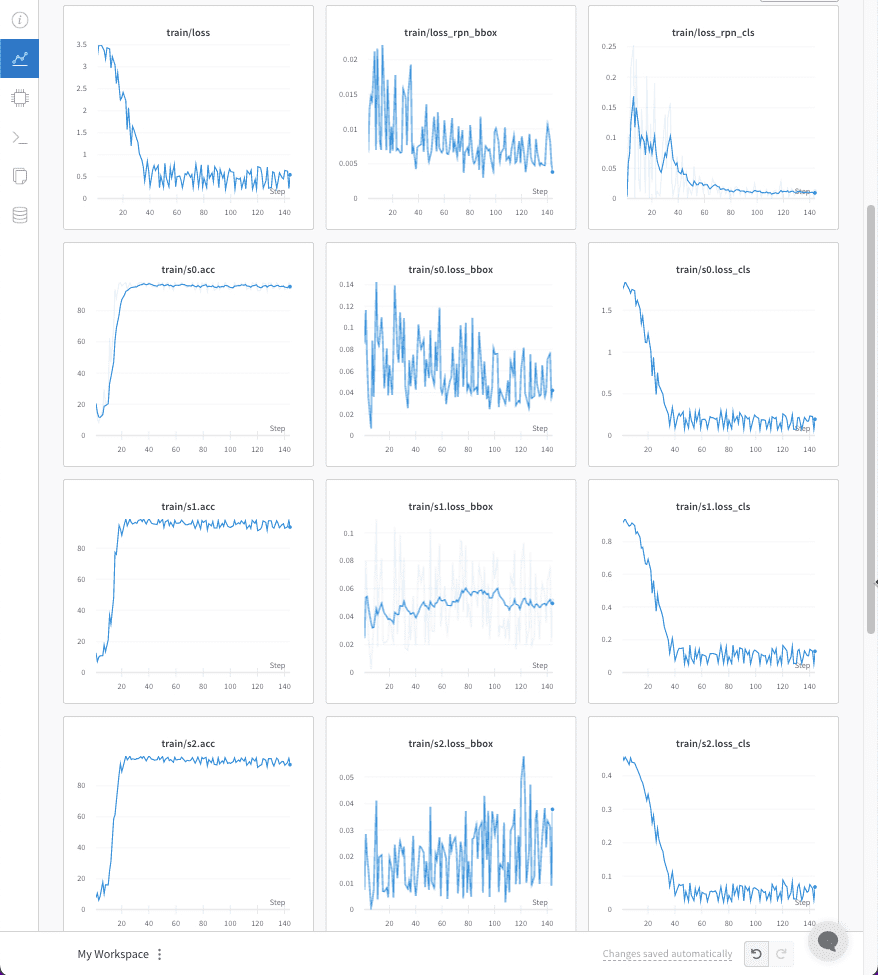
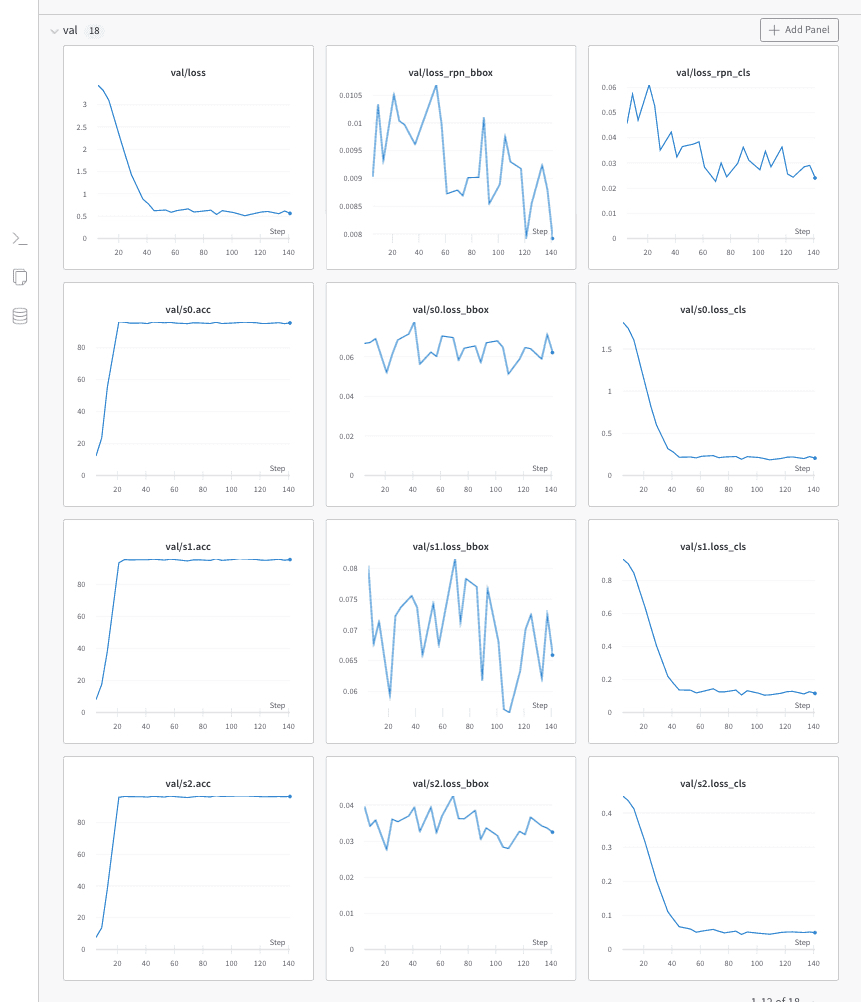
https://wandb.ai/onesixx/kaggle_cowboy_outfits/runs/25x8bwd3
wandb: Synced exp-cascade_rcnn_r50_fpn_1x-job16: https://wandb.ai/onesixx/kaggle_cowboy_outfits/runs/25x8bwd3 wandb: Synced 6 W&B file(s), 0 media file(s), 25 artifact file(s) and 1 other file(s) wandb: Find logs at: ./wandb/run-20221205_154726-25x8bwd3/logs
train.py
# Copyright (c) OpenMMLab. All rights reserved.
import argparse, copy, time, warnings
import os, os.path as osp
import torch
import torch.distributed as dist
import mmcv
from mmcv import Config, DictAction
from mmcv.runner import get_dist_info, init_dist
from mmcv.utils import get_git_hash
from mmdet import __version__
from mmdet.apis import init_random_seed, set_random_seed, train_detector
from mmdet.datasets import build_dataset
from mmdet.models import build_detector
from mmdet.utils import (collect_env, get_device, get_root_logger,
replace_cfg_vals, setup_multi_processes, update_data_root)
def parse_args():
parser = argparse.ArgumentParser(description='Train a detector')
parser.add_argument('config', help='train config file path')
parser.add_argument('--work-dir', help='the dir to save logs and models')
parser.add_argument('--resume-from', help='the checkpoint file to resume from')
parser.add_argument('--auto-resume', action='store_true', help='resume from the latest checkpoint automatically')
parser.add_argument('--no-validate', action='store_true', help='whether not to evaluate the checkpoint during training')
group_gpus = parser.add_mutually_exclusive_group()
group_gpus.add_argument('--gpus', type=int, help='(Deprecated, please use --gpu-id) number of gpus to use (only applicable to non-distributed training)')
group_gpus.add_argument('--gpu-ids',type=int, nargs='+', help='(Deprecated, please use --gpu-id) ids of gpus to use (only applicable to non-distributed training)')
group_gpus.add_argument('--gpu-id', type=int, default=0, help='id of gpu to use (only applicable to non-distributed training)')
parser.add_argument('--seed', type=int, default=None, help='random seed')
parser.add_argument('--diff-seed', action='store_true', help='Whether or not set different seeds for different ranks')
parser.add_argument('--deterministic', action='store_true', help='whether to set deterministic options for CUDNN backend.')
parser.add_argument('--options', nargs='+', action=DictAction,help='override some settings in the used config, the key-value pair in xxx=yyy format will be merged into config file (deprecate), change to --cfg-options instead.')
parser.add_argument('--cfg-options', nargs='+', action=DictAction,
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file. If the value to '
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
'Note that the quotation marks are necessary and that no white space is allowed.')
parser.add_argument('--launcher', choices=['none', 'pytorch', 'slurm', 'mpi'],
default='none', help='job launcher')
parser.add_argument('--local_rank', type=int, default=0)
parser.add_argument('--auto-scale-lr', action='store_true', help='enable automatically scaling LR.')
args = parser.parse_args()
if 'LOCAL_RANK' not in os.environ:
os.environ['LOCAL_RANK'] = str(args.local_rank)
if args.options and args.cfg_options:
raise ValueError(
'--options and --cfg-options cannot be both '
'specified, --options is deprecated in favor of --cfg-options')
if args.options:
warnings.warn('--options is deprecated in favor of --cfg-options')
args.cfg_options = args.options
return args
def main():
args = parse_args()
cfg = Config.fromfile(args.config)
cfg = replace_cfg_vals(cfg) # replace the ${key} with the value of cfg.key
update_data_root(cfg) # update data root according to MMDET_DATASETS
if args.cfg_options is not None:
cfg.merge_from_dict(args.cfg_options)
if args.auto_scale_lr:
if 'auto_scale_lr' in cfg and \\
'enable' in cfg.auto_scale_lr and 'base_batch_size' in cfg.auto_scale_lr:
cfg.auto_scale_lr.enable = True
else:
warnings.warn('Can not find "auto_scale_lr" or "auto_scale_lr.enable" or "auto_scale_lr.base_batch_size" in your configuration file. '
'Please update all the configuration files to mmdet >= 2.24.1.')
# set multi-process settings
setup_multi_processes(cfg)
# set cudnn_benchmark
if cfg.get('cudnn_benchmark', False):
torch.backends.cudnn.benchmark = True
# work_dir is determined in this priority: CLI > segment in file > filename
if args.work_dir is not None:
# update configs according to CLI args if args.work_dir is not None
cfg.work_dir = args.work_dir
elif cfg.get('work_dir', None) is None:
# use config filename as default work_dir if cfg.work_dir is None
cfg.work_dir = osp.join('./work_dirs', osp.splitext(osp.basename(args.config))[0])
if args.resume_from is not None:
cfg.resume_from = args.resume_from
cfg.auto_resume = args.auto_resume
if args.gpus is not None:
cfg.gpu_ids = range(1)
warnings.warn('`--gpus` is deprecated because we only support single GPU mode in non-distributed training. Use `gpus=1` now.')
if args.gpu_ids is not None:
cfg.gpu_ids = args.gpu_ids[0:1]
warnings.warn('`--gpu-ids` is deprecated, please use `--gpu-id`. Because we only support single GPU mode in non-distributed training. Use the first GPU in `gpu_ids` now.')
if args.gpus is None and args.gpu_ids is None:
cfg.gpu_ids = [args.gpu_id]
# init distributed env first, since logger depends on the dist info.
if args.launcher == 'none':
distributed = False
else:
distributed = True
init_dist(args.launcher, **cfg.dist_params)
# re-set gpu_ids with distributed training mode
_, world_size = get_dist_info()
cfg.gpu_ids = range(world_size)
# create work_dir
mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
# dump config
cfg.dump(osp.join(cfg.work_dir, osp.basename(args.config)))
# init the logger before other steps
timestamp = time.strftime('%Y%m%d_%H%M%S', time.localtime())
log_file = osp.join(cfg.work_dir, f'{timestamp}.log')
logger = get_root_logger(log_file=log_file, log_level=cfg.log_level)
# init the meta dict to record some important information such as
# environment info and seed, which will be logged
meta = dict()
# log env info
env_info_dict = collect_env()
env_info = '\
'.join([(f'{k}: {v}') for k, v in env_info_dict.items()])
dash_line = '-' * 60 + '\
'
logger.info('Environment info:\
' + dash_line + env_info + '\
' + dash_line)
meta['env_info'] = env_info
meta['config'] = cfg.pretty_text
# log some basic info
logger.info(f'Distributed training: {distributed}')
logger.info(f'Config:\
{cfg.pretty_text}')
cfg.device = get_device()
# set random seeds
seed = init_random_seed(args.seed, device=cfg.device)
seed = seed + dist.get_rank() if args.diff_seed else seed
logger.info(f'Set random seed to {seed}, deterministic: {args.deterministic}')
set_random_seed(seed, deterministic=args.deterministic)
cfg.seed = seed
meta['seed'] = seed
meta['exp_name'] = osp.basename(args.config)
model = build_detector(cfg.model, train_cfg=cfg.get('train_cfg'), test_cfg=cfg.get('test_cfg'))
model.init_weights()
datasets = [build_dataset(cfg.data.train)]
if len(cfg.workflow) == 2:
assert 'val' in [mode for (mode, _) in cfg.workflow]
val_dataset = copy.deepcopy(cfg.data.val)
val_dataset.pipeline = cfg.data.train.get(
'pipeline', cfg.data.train.dataset.get('pipeline'))
datasets.append(build_dataset(val_dataset))
if cfg.checkpoint_config is not None:
# save mmdet version, config file content and class names in
# checkpoints as meta data
cfg.checkpoint_config.meta = dict(
mmdet_version=__version__ + get_git_hash()[:7],
CLASSES=datasets[0].CLASSES)
# add an attribute for visualization convenience
model.CLASSES = datasets[0].CLASSES
train_detector(
model,
datasets,
cfg,
distributed=distributed,
validate=(not args.no_validate),
timestamp=timestamp,
meta=meta)
if __name__ == '__main__':
main()
