mmdet 5: Customize Runtime Settings
TUTORIAL 5: CUSTOMIZE RUNTIME SETTINGS
optimization settings 수정
(Pytorch에서 지원하는) optimizer 수정
MMDet은 PyTorch로 구현된 모든 optimizer를 지원하며,
config의 argument를 수정을 통해 optimizer를 지정할수 있다.
optimizer = dict(type='Adam', lr=0.0003, weight_decay=0.0001)
ex) ADAM Optiimizer를 지정하고, 모델의 lr(learning rate)를 수정
PyTorch의 API doc 를 참조해서 weight_decay(가중치 감쇠)같은 argument의 파라미터를 직접 수정할 수 있다.
(self-implemented) optimizer 수정
Read More...자신만의 optimizer를 정의하여 사용할 수 있다.
1. Define a new optimizer
Assume you want to add a optimizer named MyOptimizer, which has arguments a, b, and c. You need to create a new directory named mmdet/core/optimizer. And then implement the new optimizer in a file, e.g., in mmdet/core/optimizer/my_optimizer.py:
from .registry import OPTIMIZERS
from torch.optim import Optimizer
@OPTIMIZERS.register_module()
class MyOptimizer(Optimizer):
def __init__(self, a, b, c)
2. Add the optimizer to registry
To find the above module defined above, this module should be imported into the main namespace at first. There are two options to achieve it.
- Modify
mmdet/core/optimizer/__init__.pyto import it.The newly defined module should be imported inmmdet/core/optimizer/__init__.pyso that the registry will find the new module and add it:
from .my_optimizer import MyOptimizer
- Use
custom_importsin the config to manually import it
custom_imports = dict(imports=['mmdet.core.optimizer.my_optimizer'], allow_failed_imports=False)
The module mmdet.core.optimizer.my_optimizer will be imported at the beginning of the program and the class MyOptimizer is then automatically registered. Note that only the package containing the class MyOptimizer should be imported. mmdet.core.optimizer.my_optimizer.MyOptimizer cannot be imported directly.
Actually users can use a totally different file directory structure using this importing method, as long as the module root can be located in PYTHONPATH.
3. Specify the optimizer in the config file
Then you can use MyOptimizer in optimizer field of config files. In the configs, the optimizers are defined by the field optimizer like the following:
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
To use your own optimizer, the field can be changed to
optimizer = dict(type='MyOptimizer', a=a_value, b=b_value, c=c_value)
Customize optimizer constructor
Read More...Some models may have some parameter-specific settings for optimization, e.g. weight decay for BatchNorm layers. The users can do those fine-grained parameter tuning through customizing optimizer constructor.
from mmcv.utils import build_from_cfg
from mmcv.runner.optimizer import OPTIMIZER_BUILDERS, OPTIMIZERS
from mmdet.utils import get_root_logger
from .my_optimizer import MyOptimizer
@OPTIMIZER_BUILDERS.register_module()
class MyOptimizerConstructor(object):
def __init__(self, optimizer_cfg, paramwise_cfg=None):
def __call__(self, model):
return my_optimizer
The default optimizer constructor is implemented here, which could also serve as a template for new optimizer constructor.
Additional settings
Read More...Optimizer로 실행할 수 없는 트릭들은 optimizer constructor 혹은 hook을 통해 실행한다. 다음은 학습을 안정화 혹은 가속화시킬 수 있는 몇 가지 일반적인 세팅들이다.
Tricks not implemented by the optimizer should be implemented through optimizer constructor (e.g., set parameter-wise learning rates) or hooks. We list some common settings that could stabilize the training or accelerate the training. Feel free to create PR, issue for more settings.
- Use gradient clip to stabilize training: Some models need gradient clip to clip the gradients to stabilize the training process. An example is as below:optimizer_config = dict( _delete_=True, grad_clip=dict(max_norm=35, norm_type=2)) If your config inherits the base config which already sets the
optimizer_config, you might need_delete_=Trueto override the unnecessary settings. See the config documentation for more details.
optimizer_config = dict (
\t_delete_ = True,
grad_clip = dict(max_norm=35, norm_type=2))
- Use momentum schedule to accelerate model convergence: We support momentum scheduler to modify model’s momentum according to learning rate, which could make the model converge in a faster way. Momentum scheduler is usually used with LR scheduler, for example, the following config is used in 3D detection to accelerate convergence. For more details, please refer to the implementation of CyclicLrUpdater and CyclicMomentumUpdater.
lr_config = dict(
policy='cyclic',
target_ratio=(10, 1e-4),
cyclic_times=1,
step_ratio_up=0.4,
)
momentum_config = dict(
policy='cyclic',
target_ratio=(0.85 / 0.95, 1),
cyclic_times=1,
step_ratio_up=0.4,
)
training schedules 수정
https://onesixx.com/lr-scheduler
learning scheduler의 디폴트 세팅은 MMCV에서 StepLRHook이라 불리는 1x schedule의 step learning rate이다. MMDet은 CosineAnnealing이나 Poly schedule과 같은 많은 lr schedule을 제공한다.
We support many other learning rate schedule here, such as CosineAnnealing and Poly schedule.
# Poly schedule
lr_config = dict(
policy='poly',
power=0.9,
min_lr=1e-4,
by_epoch=False)
# ConsineAnnealing schedule
lr_config = dict(
policy='CosineAnnealing',
warmup='linear',
warmup_iters=1000,
warmup_ratio=1.0 / 10,
min_lr_ratio=1e-5)
- LAMBDA LR
- MultiplicativeLR
- StepLR <——- default로 step learning rate with 1x schedule 사용함 (
StepLRHookin MMCV) - MultiStepLR
- ExponentialLR
- CosineAnnealingLR
- CyclicLR – triangular
- CyclicLR – triangular2
- CyclicLR – exp_range
- OneCycleLR – cos
- OneCycleLR – linear
- CosineAnnealingWarmRestarts
workflow 수정
Workflow는 실행순서와 epoch을 설정하기 위한 (phase, epochs)의 리스트
# default : training을 위해 1epoch를 실행
workflow = [('train', 1)]
# validate set에 대해 모델에 대한 metric(loss, accuracy 같은 측정항목)의 값을 구하기 위해서는
# validataion에서도 1 epoch를 실행
workflow = [('train', 1), ('val', 1)]
Note:
- The parameters of model will not be updated during val epoch.
- Keyword
total_epochsin the config only controls the number of training epochs and will not affect the validation workflow. - Workflows
[('train', 1), ('val', 1)]and[('train', 1)]will not change the behavior ofEvalHook
becauseEvalHookis called byafter_train_epochand validation workflow only affect hooks that are called throughafter_val_epoch.
Therefore, the only difference between[('train', 1), ('val', 1)]and[('train', 1)]is that the runner will calculate losses on validation set after each training epoch.
hooks 수정
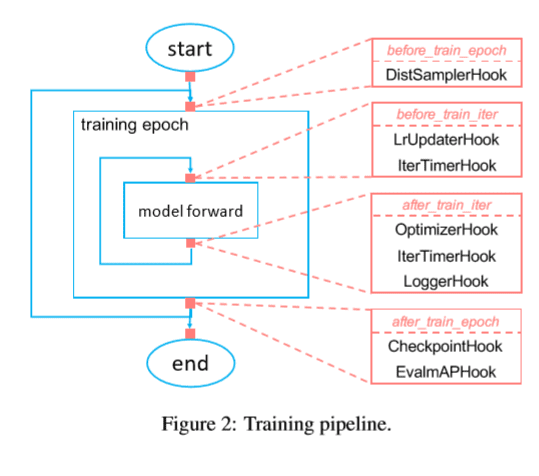
자체 구현 hooks
1. 신규 Hook 구현
새로운 Hook을 구현이 필요한 경우, MMDetection은 v2.3.0부터 training에서 customized hooks을 지원한다.
그러므로, 사용자가 mmdet에서 직접 hook을 구현하고, config를 수정하여 사용한다.
hook의 기능에 기반해서, 사용자는 training의 각 단계별로
(before_run, before_epoch, before_iter,
after_run, after_epoch, after_iter) hook이 할 일을 설정할 필요가 있다.
from mmcv.runner import HOOKS, Hook
@HOOKS.register_module()
class MyHook(Hook):
def __init__(self, a, b):
pass
def before_run(self, runner):
pass
def after_run(self, runner):
pass
def before_epoch(self, runner):
pass
def after_epoch(self, runner):
pass
def before_iter(self, runner):
pass
def after_iter(self, runner):
pass
2. 신규 Hook 등록
mmdet/core/utils/my_hook.py에 파일이 있다고 가정하면,
MyHook를 import하는 2가지 방법이 있다.
# import하기 위해 mmdet/core/utils/__init__.py을 수정한다.
# 새롭게 정의된 모듈은 mmdet/core/utils/__init__.py에서 import되야 한다.
# 그 결과 registry는 새로운 모듈에서 있고, 추가된다.
from .my_hook import MyHook
# 수동으로 import하기 위해 config에서 custom_imports를 사용한다.
custom_imports = dict(
imports=['mmdet.core.utils.my_hook'],
allow_failed_imports=False
)
3. config 수정
# hook 등록시 , 우선순위 default 는 NORMAL
custom_hooks = [
dict(type='MyHook', a=a_value, b=b_value)
]
# hook 우선순위 설정 : priority키에 'NORMAL'또는 'HIGHEST'
custom_hooks = [
dict(type='MyHook', a=a_value, b=b_value, priority='NORMAL')
]
MMCV의 구현된 Hook 사용
MMCV에 필요한 Hook이 이미 구현되어 있다면, config수정을 통해 사용할 수 있다.
mmdetection/mmdet/datasets/utils.py
...
@HOOKS.register_module()
class NumClassCheckHook(Hook):
def _check_head(self, runner):
"""Check whether the `num_classes` in head matches the length of
`CLASSES` in `dataset`.
Args:
runner (obj:`EpochBasedRunner`): Epoch based Runner.
"""
model = runner.model
dataset = runner.data_loader.dataset
if dataset.CLASSES is None:
runner.logger.warning(
f'Please set `CLASSES` '
f'in the {dataset.__class__.__name__} and'
f'check if it is consistent with the `num_classes` '
f'of head')
else:
assert type(dataset.CLASSES) is not str, \\
(f'`CLASSES` in {dataset.__class__.__name__}'
f'should be a tuple of str.'
f'Add comma if number of classes is 1 as '
f'CLASSES = ({dataset.CLASSES},)')
for name, module in model.named_modules():
if hasattr(module, 'num_classes') and not isinstance(
module, (RPNHead, VGG, FusedSemanticHead, GARPNHead)):
assert module.num_classes == len(dataset.CLASSES), \\
(f'The `num_classes` ({module.num_classes}) in '
f'{module.__class__.__name__} of '
f'{model.__class__.__name__} does not matches '
f'the length of `CLASSES` '
f'{len(dataset.CLASSES)}) in '
f'{dataset.__class__.__name__}')
def before_train_epoch(self, runner):
"""Check whether the training dataset is compatible with head.
Args:
runner (obj:`EpochBasedRunner`): Epoch based Runner.
"""
self._check_head(runner)
def before_val_epoch(self, runner):
"""Check whether the dataset in val epoch is compatible with head.
Args:
runner (obj:`EpochBasedRunner`): Epoch based Runner.
"""
self._check_head(runner)
Head의 num_classes가 Dataset의 CLASSES의 length와 일치하는 확인하기 위해
default_runtime.py 에 아래 내용을 설정한다.
custom_hooks = [dict(type='NumClassCheckHook')]
default runtime hooks 수정
custom_hooks를 통해 등록되지 않았지만, 일반적으로 쓰는 hook들이 있다.
(우선순위는 모두 Normal이고, logger hook만 very_low이다. )
- checkpoint_config
- log_config
- evaluation
- lr_config
- optimizer_config
- momentum_config
Checkpoint config
MMCV runner 는 CheckpointHook(mmcv/mmcv/runner/hooks/checkpoint.py)를 초기화하기 위해 checkpoint_config를 사용한다.
checkpoint_config = dict(interval=1)
More details of the arguments are here
The users could set max_keep_ckpts to only save only small number of checkpoints or decide whether to store state dict of optimizer by save_optimizer.
Log config
https://onesixx.com/wandb-with-mmdetection
The log_config wraps multiple logger hooks and enables to set intervals. Now MMCV supports WandbLoggerHook, MlflowLoggerHook, and TensorboardLoggerHook.
The detail usages can be found in the doc.
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook')
])
log_config = dict(
interval=10,
hooks=[
dict(type='TextLoggerHook'),
dict(type='WandbLoggerHook',
init_kwargs=dict(
project='faster_rcnn_r50_fpn_1x',
name='sixx_tray')
)
]
)
https://mmcv.readthedocs.io/en/latest/_modules/index.html
mmcv.runner.hooks.checkpoint mmcv.runner.hooks.ema mmcv.runner.hooks.evaluation mmcv.runner.hooks.logger.base mmcv.runner.hooks.logger.clearml mmcv.runner.hooks.logger.dvclive mmcv.runner.hooks.logger.mlflow mmcv.runner.hooks.logger.neptune mmcv.runner.hooks.logger.pavi mmcv.runner.hooks.logger.segmind mmcv.runner.hooks.logger.tensorboard mmcv.runner.hooks.logger.text mmcv.runner.hooks.logger.wandb mmcv.runner.hooks.lr_updater mmcv.runner.hooks.momentum_updater mmcv.runner.hooks.optimizer mmcv.runner.hooks.sampler_seed mmcv.runner.hooks.sync_buffer
Evaluation config
The config of evaluation will be used to initialize the EvalHook.
Except the key interval, other arguments such as metric will be passed to the dataset.evaluate()
evaluation = dict(interval=1, metric='bbox')
