mmdet 2: Customize Datasets
TUTORIAL 2: CUSTOMIZE DATASETS
Support new data format
데이터셋은 일단 Middle format으로 바뀌어서 Training이나 Inference에 활용된다고 가정하면,
CoCo처럼 이미 등록된 데이터셋(mmdet>datasets>__init__.py)은 Middle format으로 바꿀 ConvertingRule을 이미 제공하고 있고, 그런게 준비된지 않는 datasets는 따로 코딩해 줘야 한다.
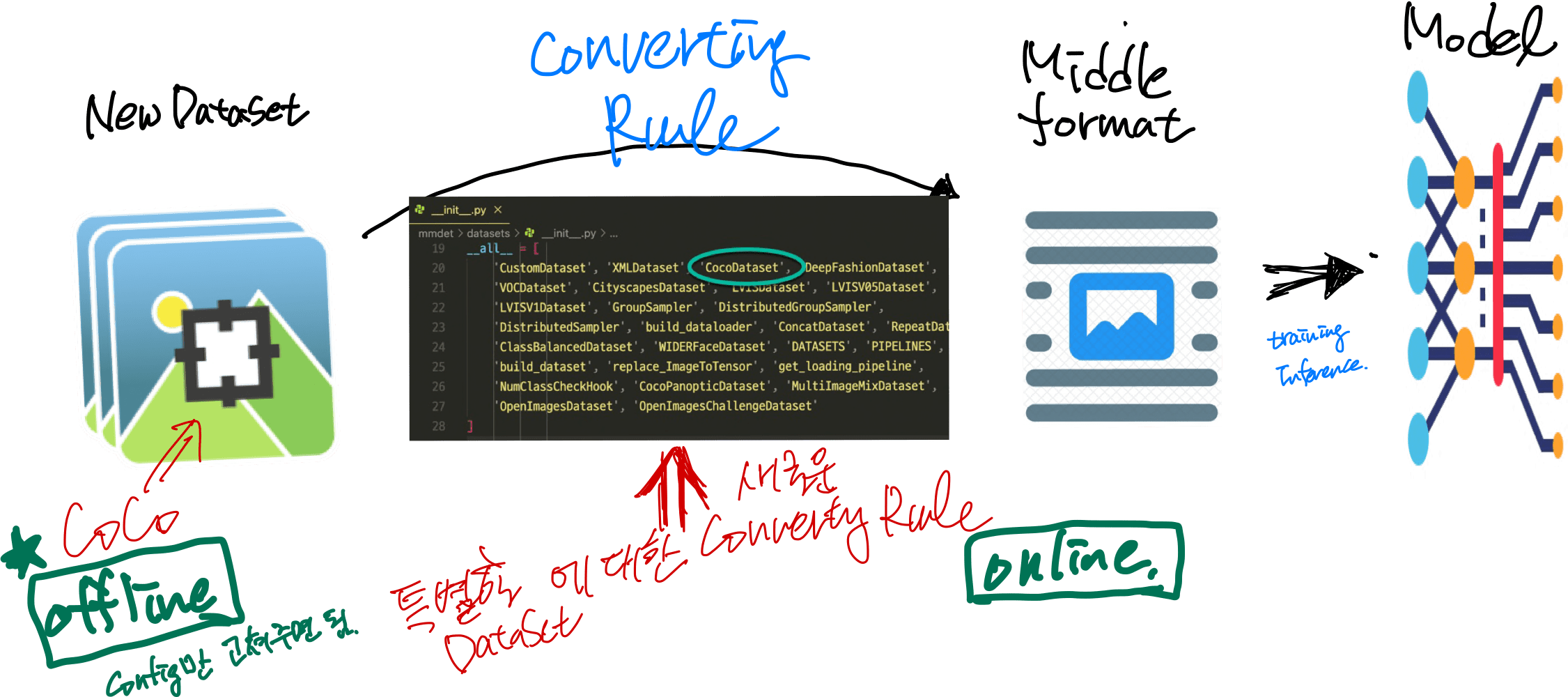
일단 새로운 데이터셋은 CoCo(existing formats)인지 확인하고 아니면 CoCo로 바꿀수 있는지 확인해본다: offline
아니면 직접 middle format으로 바꾼다 : on-line
Off-line :: Coco 포멧으로 (신규데이터셋을) 재편성.
데이터셋 자체를 COCO 포멧으로 바꾼다.
COCO포멧의 annotation JSON파일에 3가지 key

일단 COCO 포멧으로 바꿔 놓기만 하면, 그다음에는 Config 파일을 조금 고치고,
- Modify the config file for using the customized dataset.
- Check the annotations of the customized dataset.
Here we give an example to show the above two steps, which uses a customized dataset of 5 classes with COCO format to train an existing Cascade Mask R-CNN R50-FPN detector.
example>
1. Modify the config file for using the customized dataset
There are two aspects involved in the modification of config file:
- The
datafield. Specifically, you need to explicitly add theclassesfields indata.train,data.valanddata.test. - The
num_classesfield in themodelpart. Explicitly over-write all thenum_classesfrom default value (e.g. 80 in COCO) to your classes number.
In configs/my_custom_config.py:
# the new config inherits the base configs to highlight the necessary modification
_base_ = './cascade_mask_rcnn_r50_fpn_1x_coco.py'
# 1. dataset settings
dataset_type = 'CocoDataset'
classes = ('a', 'b', 'c', 'd', 'e')
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
# explicitly add your class names to the field `classes`
classes=classes,
ann_file='path/to/your/train/annotation_data',
img_prefix='path/to/your/train/image_data'),
val=dict(
type=dataset_type,
# explicitly add your class names to the field `classes`
classes=classes,
ann_file='path/to/your/val/annotation_data',
img_prefix='path/to/your/val/image_data'),
test=dict(
type=dataset_type,
# explicitly add your class names to the field `classes`
classes=classes,
ann_file='path/to/your/test/annotation_data',
img_prefix='path/to/your/test/image_data'))
# 2. model settings
# explicitly over-write all the `num_classes` field from default 80 to 5.
model = dict(
roi_head=dict(
bbox_head=[
dict(
type='Shared2FCBBoxHead',
# explicitly over-write all the `num_classes` field from default 80 to 5.
num_classes=5),
dict(
type='Shared2FCBBoxHead',
# explicitly over-write all the `num_classes` field from default 80 to 5.
num_classes=5),
dict(
type='Shared2FCBBoxHead',
# explicitly over-write all the `num_classes` field from default 80 to 5.
num_classes=5)],
# explicitly over-write all the `num_classes` field from default 80 to 5.
mask_head=dict(num_classes=5)))
2. Check the annotations of the customized dataset
Assuming your customized dataset is COCO format, make sure you have the correct annotations in the customized dataset:
- The length for
categoriesfield in annotations should exactly equal the tuple length ofclassesfields in your config, meaning the number of classes (e.g. 5 in this example). - The
classesfields in your config file should have exactly the same elements and the same order with thenameincategoriesof annotations. MMDetection automatically maps the uncontinuousidincategoriesto the continuous label indices, so the string order ofnameincategoriesfield affects the order of label indices. Meanwhile, the string order ofclassesin config affects the label text during visualization of predicted bounding boxes. - The
category_idinannotationsfield should be valid, i.e., all values incategory_idshould belong toidincategories.
Here is a valid example of annotations:
'annotations': [
{
'segmentation': [[192.81,
247.09,
...
219.03,
249.06]], # if you have mask labels
'area': 1035.749,
'iscrowd': 0,
'image_id': 1268,
'bbox': [192.81, 224.8, 74.73, 33.43],
'category_id': 16,
'id': 42986
},
...
],
# MMDetection automatically maps the uncontinuous `id` to the continuous label indices.
'categories': [
{'id': 1, 'name': 'a'}, {'id': 3, 'name': 'b'}, {'id': 4, 'name': 'c'}, {'id': 16, 'name': 'd'}, {'id': 17, 'name': 'e'},
]
We use this way to support CityScapes dataset. The script is in cityscapes.py and we also provide the finetuning configs.
Note
- For instance segmentation datasets, MMDetection only supports evaluating mask AP of dataset in COCO format for now.
- It is recommended to convert the data offline before training, thus you can still use
CocoDatasetand only need to modify the path of annotations and the training classes.
On-line :: middle format 재편성
It is also fine if you do not want to convert the annotation format to COCO or PASCAL format.
Actually, we define a simple annotation format and all existing datasets are processed to be compatible with it, either online or offline.
The annotation of a dataset is a list of dict, each dict corresponds to an image. There are 3 field filename (relative path), width, height for testing, and an additional field ann for training. ann is also a dict containing at least 2 fields: bboxes and labels, both of which are numpy arrays. Some datasets may provide annotations like crowd/difficult/ignored bboxes, we use bboxes_ignore and labels_ignore to cover them.
Here is an example.
[
{
'filename': 'a.jpg',
'width': 1280,
'height': 720,
'ann': {
'bboxes': <np.ndarray, float32> (n, 4),
'labels': <np.ndarray, int64> (n, ),
'bboxes_ignore': <np.ndarray, float32> (k, 4),
'labels_ignore': <np.ndarray, int64> (k, ) (optional field)
}
},
...
]
There are two ways to work with custom datasets.
- online conversionYou can write a new Dataset class inherited from
CustomDataset, and overwrite two methodsload_annotations(self, ann_file)andget_ann_info(self, idx), like CocoDataset and VOCDataset. - offline conversionYou can convert the annotation format to the expected format above and save it to a pickle or json file, like pascal_voc.py. Then you can simply use
CustomDataset.
An example of customized dataset
Assume the annotation is in a new format in text files. The bounding boxes annotations are stored in text file annotation.txt as the following
# 000001.jpg 1280 720 2 10 20 40 60 1 20 40 50 60 2 # 000002.jpg 1280 720 3 50 20 40 60 2 20 40 30 45 2 30 40 50 60 3
We can create a new dataset in mmdet/datasets/my_dataset.py to load the data.
import mmcv
import numpy as np
from .builder import DATASETS
from .custom import CustomDataset
@DATASETS.register_module()
class MyDataset(CustomDataset):
CLASSES = ('person', 'bicycle', 'car', 'motorcycle')
def load_annotations(self, ann_file):
ann_list = mmcv.list_from_file(ann_file)
data_infos = []
for i, ann_line in enumerate(ann_list):
if ann_line != '#':
continue
img_shape = ann_list[i + 2].split(' ')
width = int(img_shape[0])
height = int(img_shape[1])
bbox_number = int(ann_list[i + 3])
anns = ann_line.split(' ')
bboxes = []
labels = []
for anns in ann_list[i + 4:i + 4 + bbox_number]:
bboxes.append([float(ann) for ann in anns[:4]])
labels.append(int(anns[4]))
data_infos.append(
dict(
filename=ann_list[i + 1],
width=width,
height=height,
ann=dict(
bboxes=np.array(bboxes).astype(np.float32),
labels=np.array(labels).astype(np.int64))
))
return data_infos
def get_ann_info(self, idx):
return self.data_infos[idx]['ann']
Then in the config, to use MyDataset you can modify the config as the following
dataset_A_train = dict(
type='MyDataset',
ann_file = 'image_list.txt',
pipeline=train_pipeline
)
Customize datasets by dataset wrappers
MMDetection also supports many dataset wrappers to mix the dataset or modify the dataset distribution for training.
Currently it supports to three dataset wrappers as below:
RepeatDataset: simply repeat the whole dataset.ClassBalancedDataset: repeat dataset in a class balanced manner.ConcatDataset: concat datasets.
Repeat dataset
We use RepeatDataset as wrapper to repeat the dataset. For example, suppose the original dataset is Dataset_A, to repeat it, the config looks like the following
dataset_A_train = dict(
type='RepeatDataset',
times=N,
dataset=dict( # This is the original config of Dataset_A
type='Dataset_A',
...
pipeline=train_pipeline
)
)
Class balanced dataset
We use ClassBalancedDataset as wrapper to repeat the dataset based on category frequency. The dataset to repeat needs to instantiate function self.get_cat_ids(idx) to support ClassBalancedDataset. For example, to repeat Dataset_A with oversample_thr=1e-3, the config looks like the following
dataset_A_train = dict(
type='ClassBalancedDataset',
oversample_thr=1e-3,
dataset=dict( # This is the original config of Dataset_A
type='Dataset_A',
...
pipeline=train_pipeline
)
)
You may refer to source code for details.
Concatenate dataset
There are three ways to concatenate the dataset.
- If the datasets you want to concatenate are in the same type with different annotation files, you can concatenate the dataset configs like the following.dataset_A_train = dict( type=‘Dataset_A’, ann_file = [‘anno_file_1’, ‘anno_file_2’], pipeline=train_pipeline ) If the concatenated dataset is used for test or evaluation, this manner supports to evaluate each dataset separately. To test the concatenated datasets as a whole, you can set
separate_eval=Falseas below.dataset_A_train = dict( type=‘Dataset_A’, ann_file = [‘anno_file_1’, ‘anno_file_2’], separate_eval=False, pipeline=train_pipeline ) - In case the dataset you want to concatenate is different, you can concatenate the dataset configs like the following.dataset_A_train = dict() dataset_B_train = dict() data = dict( imgs_per_gpu=2, workers_per_gpu=2, train = [ dataset_A_train, dataset_B_train ], val = dataset_A_val, test = dataset_A_test ) If the concatenated dataset is used for test or evaluation, this manner also supports to evaluate each dataset separately.
- We also support to define
ConcatDatasetexplicitly as the following.dataset_A_val = dict() dataset_B_val = dict() data = dict( imgs_per_gpu=2, workers_per_gpu=2, train=dataset_A_train, val=dict( type=‘ConcatDataset’, datasets=[dataset_A_val, dataset_B_val], separate_eval=False)) This manner allows users to evaluate all the datasets as a single one by settingseparate_eval=False.
Note:
- The option
separate_eval=Falseassumes the datasets useself.data_infosduring evaluation. Therefore, COCO datasets do not support this behavior since COCO datasets do not fully rely onself.data_infosfor evaluation. Combining different types of datasets and evaluating them as a whole is not tested thus is not suggested. - Evaluating
ClassBalancedDatasetandRepeatDatasetis not supported thus evaluating concatenated datasets of these types is also not supported.
A more complex example that repeats Dataset_A and Dataset_B by N and M times, respectively, and then concatenates the repeated datasets is as the following.
dataset_A_train = dict(
type='RepeatDataset',
times=N,
dataset=dict(
type='Dataset_A',
...
pipeline=train_pipeline
)
)
dataset_A_val = dict(
...
pipeline=test_pipeline
)
dataset_A_test = dict(
...
pipeline=test_pipeline
)
dataset_B_train = dict(
type='RepeatDataset',
times=M,
dataset=dict(
type='Dataset_B',
...
pipeline=train_pipeline
)
)
data = dict(
imgs_per_gpu=2,
workers_per_gpu=2,
train = [
dataset_A_train,
dataset_B_train
],
val = dataset_A_val,
test = dataset_A_test
)
Modify Dataset Classes
With existing dataset types, we can modify the class names of them to train subset of the annotations. For example, if you want to train only three classes of the current dataset, you can modify the classes of dataset. The dataset will filter out the ground truth boxes of other classes automatically.
classes = ('person', 'bicycle', 'car')
data = dict(
train=dict(classes=classes),
val=dict(classes=classes),
test=dict(classes=classes))
MMDetection V2.0 also supports to read the classes from a file, which is common in real applications. For example, assume the classes.txt contains the name of classes as the following.
person bicycle car
Users can set the classes as a file path, the dataset will load it and convert it to a list automatically.
classes = 'path/to/classes.txt'
data = dict(
train=dict(classes=classes),
val=dict(classes=classes),
test=dict(classes=classes))
Note:
- Before MMDetection v2.5.0, the dataset will filter out the empty GT images automatically if the classes are set and there is no way to disable that through config. This is an undesirable behavior and introduces confusion because if the classes are not set, the dataset only filter the empty GT images when
filter_empty_gt=Trueandtest_mode=False. After MMDetection v2.5.0, we decouple the image filtering process and the classes modification, i.e., the dataset will only filter empty GT images whenfilter_empty_gt=Trueandtest_mode=False, no matter whether the classes are set. Thus, setting the classes only influences the annotations of classes used for training and users could decide whether to filter empty GT images by themselves. - Since the middle format only has box labels and does not contain the class names, when using
CustomDataset, users cannot filter out the empty GT images through configs but only do this offline. - Please remember to modify the
num_classesin the head when specifyingclassesin dataset. We implemented NumClassCheckHook to check whether the numbers are consistent since v2.9.0(after PR#4508). - The features for setting dataset classes and dataset filtering will be refactored to be more user-friendly in the future (depends on the progress).
COCO Panoptic Dataset
Now we support COCO Panoptic Dataset, the format of panoptic annotations is different from COCO format. Both the foreground and the background will exist in the annotation file. The annotation json files in COCO Panoptic format has the following necessary keys:
'images': [
{
'file_name': '000000001268.jpg',
'height': 427,
'width': 640,
'id': 1268
},
...
]
'annotations': [
{
'filename': '000000001268.jpg',
'image_id': 1268,
'segments_info': [
{
'id':8345037, # One-to-one correspondence with the id in the annotation map.
'category_id': 51,
'iscrowd': 0,
'bbox': (x1, y1, w, h), # The bbox of the background is the outer rectangle of its mask.
'area': 24315
},
...
]
},
...
]
'categories': [ # including both foreground categories and background categories
{'id': 0, 'name': 'person'},
...
]
Moreover, the seg_prefix must be set to the path of the panoptic annotation images.
data = dict(
type='CocoPanopticDataset',
train=dict(
seg_prefix = 'path/to/your/train/panoptic/image_annotation_data'
),
val=dict(
seg_prefix = 'path/to/your/train/panoptic/image_annotation_data'
)
)
