중복 duplicated, rleid
duplicated(), Unique()
data(iris) dd <- data.table(iris) dd %>% distinct() dd[ , unique(.SD)] ## 행의 모든 컬럼이 (다른 행과) 중복값을 가지는 경우 duplicated(dd) %>% sum() # 1개 duplicated(dd) %>% which() # 143번째 (102번째값과 모든 컬럼이 일치) result1 <- unique(dd) # 143번째 삭제 # dim(d0) #[1] 149 5
항상 가장 위에 있는 것만 남김.
따라서, 잘 정렬후 중복을 삭제할 필요가 있음.
## 특정 컬럼이 중복값을 가지는 경우 # Species 컬럼의 중복 행수 확인 duplicated(dd$Species) %>% sum() # 147개 duplicated(dd$Species) %>% which() # (1, 51, 101번째값 제외) result2 <- dd[!duplicated(iris$Species), ] # Sepal.Length Sepal.Width Petal.Length Petal.Width Species #1 5.1 3.5 1.4 0.2 setosa #51 7.0 3.2 4.7 1.4 versicolor #101 6.3 3.3 6.0 2.5 virginica
result3 <- dd1[!duplicated(dd1$Species), ] # Sepal.Length Sepal.Width Petal.Length Petal.Width Species #1 7.9 3.8 6.4 2.0 virginica #13 7.0 3.2 4.7 1.4 versicolor #71 5.8 4.0 1.2 0.2 setosa
duplicated() 한계
unique()나 duplicated()는 중복을 제거하는데 유용하지만,
연속된(consecutive) 중복값을 제거하는데 사용할 수 없다.
a <- c(1,1,1,2,2,3,4,4,4,4,5,5,5,5,1,1,1,2,2,3) a[!duplicated(a)] # [1] 1 2 3 4 5 원하는 값은 # [1] 1 2 3 4 5 1 2 3 또는 [1] 1 1 2 2 3 4 4 5 5 1 1 2 2 3
순서가 있는 경우는 duplicated()도 유용하게 사용된다.
a <- c(1,1,1,2,2,3,4,4,4,4,5,5,5,5)
F T T F T F F T T T F T T T # 앞을 기준으로 중복
T T F T F F T T T F T T T F # 뒤를 기준으로 중복
F T F F F F F T T F F T T F # 중복 시작 끝만 F
T F T T T T T F F T T F F T # 중복 시작 끝만 T
duplicated(a)
duplicated(a, fromLast=T)
duplicated(a) & duplicated(a, fromLast=T)
!(duplicated(a) & duplicated(a, fromLast=T))
DT <- fread("
A B C
1 a 1
2 a 1
3 a 1
4 a 2
5 a 3
6 a 3
7 a 1
8 a 2
9 a 2
10 a 2
")
DT <- read.table(header=T, stringsAsFactors=F, text="
A B C
1 a 1
2 a 1
3 a 1
4 a 2
5 a 3
6 a 3
7 a 1
8 a 2
9 a 2
10 a 2
") %>% data.table()
# 원하는 결과가 아님
DT[!duplicated(DT[,c('C')]),] # 변수명으로 제거
DT[!duplicated(DT[,c(3)]),] # 인덱스로 제거
# A B C
# 1: 1 a 1
# 2: 4 a 2
# 3: 5 a 3
rleid() :: run length encoding id
run-length 형태의 group id
rle는 (잘 사용되진 않지만) 압축방법중, 같은값이 연속될때 그 반복수와 반복되는 값만으로 표현하는 방법.
- 원래 문자열 : ("a","a","a","c","c","b","b","b","b")
- 압축 문자열 : a3c2b4
a가 3개 , c가 2개, b가 4개로 저장
code[] = {a, c, b}, len[]={ 3, 2, 4}
> DT = data.table(grp=c("a","a","a","c","c","b","b","b","b"))
> DT[ , gid:=rleid(grp)]
grp gid
1: a 1
2: a 1
3: a 1
4: c 2
5: c 2
6: b 3
7: b 3
8: b 3
9: b 3
> rleid(DT$grp)
> rleidv(DT,"grp") # same as above
[1] 1 1 1 2 2 3 3 3 3
> rleid(DT$grp, prefix="grp") # prefix with 'grp'
[1] "grp1" "grp1" "grp1" "grp2" "grp2" "grp3" "grp3" "grp3" "grp3"
> DT = data.table(grp=c("a","a","a","c","c","b","b","b","b"), value=1:9)
> DT[, cumsum(value), by=.(grp, rleid(grp))]
grp rleid V1
1: a 1 1
2: a 1 3
3: a 1 6
4: c 2 4
5: c 2 9
6: b 3 6
7: b 3 13
8: b 3 21
9: b 3 30
> DT[, sum(value), by=.(grp, rleid(grp))]
grp rleid V1
1: a 1 6
2: c 2 9
3: b 3 30
rleid() plot에 활용
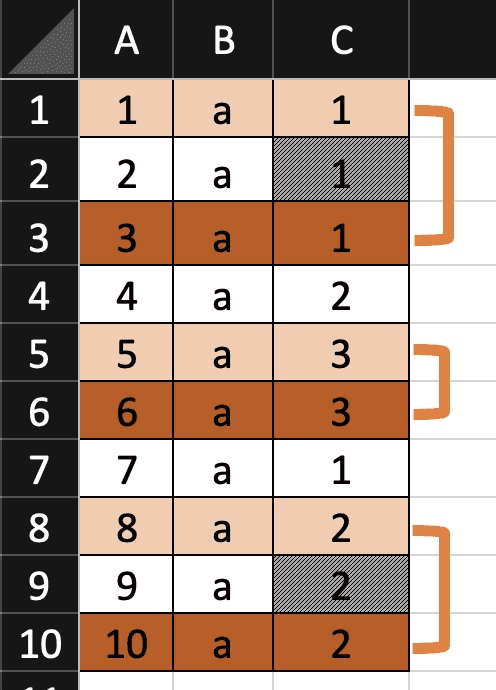
DT[, rleid(C)]
# [1] 1 1 1 2 3 3 4 5 5 5
> DT[, rleC:=rleid(C)]
> DT
A B C rleC
1: 1 a 1 1
2: 2 a 1 1
3: 3 a 1 1
4: 4 a 2 2
5: 5 a 3 3
6: 6 a 3 3
7: 7 a 1 4
8: 8 a 2 5
9: 9 a 2 5
10: 10 a 2 5 data.table의 rleid()는 활용해 rle형식의 id를 만들어 주고, 이를 활용해 중복값의 시작id과 마지막id를 찾을 수 있다.
# 중복rleid 첫값
> DT[!(duplicated(rleid(C)))]
A B C rleC
1: 1 a 1 1
2: 4 a 2 2
3: 5 a 3 3
4: 7 a 1 4
5: 8 a 2 5
# 중복rleid 마지막값
> DT[!(duplicated(rleid(C), fromLast=T))]
A B C rleC
1: 3 a 1 1
2: 4 a 2 2
3: 6 a 3 3
4: 7 a 1 4
5: 10 a 2 5
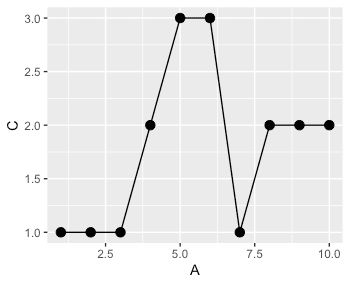
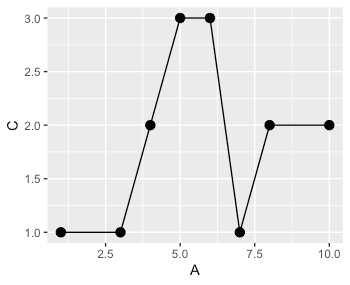
그래프를 그리기 위해, 중복 첫값과 마지막 값을 남긴다.
DTdup <- DT[!(duplicated(rleid(C)) & duplicated(rleid(C), fromLast=T)), ] # A B C # 1: 1 a 1 # 2: 3 a 1 # 3: 4 a 2 # 4: 5 a 3 # 5: 6 a 3 # 6: 7 a 1 # 7: 8 a 2 DT %>% ggplot(aes(x=A, y=C)) + geom_point(size=3) + geom_line() DTdup %>% ggplot(aes(x=A, y=C)) + geom_point(size=3) + geom_line()
rleid 활용
# using rleid, get max(y) and min of all cols in .SDcols for each consecutive run of 'v'
> DT = data.table(x=rep(c("b","a","c"),each=3),
v=c(1,1,1,2,2,1,1,2,2),
y=c(1,3,6),
a=1:9,
b=9:1)
> DT
x v y a b
1: b 1 1 1 9
2: b 1 3 2 8
3: b 1 6 3 7
4: a 2 1 4 6
5: a 2 3 5 5
6: a 1 6 6 4
7: c 1 1 7 3
8: c 2 3 8 2
9: c 2 6 9 1
> DT[, c(.(y=max(y)), lapply(.SD, min)), by=rleid(v), .SDcols=v:b]
rleid y v y a b
1: 1 6 1 1 1 7
2: 2 3 2 1 4 5
3: 3 6 1 1 6 3
4: 4 6 2 3 8 1
flipTheCoin <- sample(c("H", "T"), 10, replace = TRUE)
rle(flipTheCoin)
DT <- read.table(header=T, stringsAsFactors=F, text=" A B C 1 a 1 2 a 1 3 a 1 4 a 2 5 a 3 6 a 3 7 a 1 8 a 2 9 a 2 10 a 2 11 b 2 12 b 2 13 b 3 14 b 3 15 b 3 16 b 2 17 b 2 18 b 2 19 b 3 ") %>% data.table() DT[, .SD[!(duplicated(rleid(C)) & duplicated(rleid(C), fromLast=T)), ], by=.(B)]
Signal
> DT = data.table(grp=c(NA,0,0,0,1,1,-1,-1,-1,1), value=1:10)
> DT[, cumsum(value), by=.(grp, rleid(grp))]
grp rleid V1
1: NA 1 1
2: 0 2 2
3: 0 2 5
4: 0 2 9
5: 1 3 5
6: 1 3 11
7: -1 4 7
8: -1 4 15
9: -1 4 24
10: 1 5 10
> DT[, sum(value), by=.(grp, rleid(grp))]
grp rleid V1
1: NA 1 1
2: 0 2 9
3: 1 3 11
4: -1 4 24
5: 1 5 10 