data.table Tip
Table of contents
Using thread
?getDTthreads
생략된 rows 보기
많지 않은 데이터 전체를 Console창에서 보고 싶을때, 가장 쉽게 View(데이터.테이블) 도 있지만,
옵션의 max.print를 늘리는 방법이 있다.
options(max.print=6666)
[ reached getOption("max.print") -- omitted 93 rows ]
# 현재 max.print값 확인
getOption("max.print") # [1] 1000
# options값 변경
options(max.print=2000)
myData %>% print(nrow=666)
display entire row
data[ , col1 , with=FALSE] %>% print(n=Inf)
Union
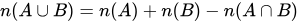
AB <- rbind(A, B) AB <- AB[!duplicated(AB),]
Shift
shift() example
DT <- data.table(A=1:5) # A # 1: 1 # 2: 2 # 3: 3 # 4: 4 # 5: 5
DT[ , D:= shift(A)] DT[ , D:= shift(A, n=1, type="lag", fill=NA)] # A D # 1: 1 NA # 2: 2 1 # 3: 3 2 # 4: 4 3 # 5: 5 4 DT[ , D:= shift(A, 2, type="lead", fill=0)] # A D # 1: 1 3 # 2: 2 4 # 3: 3 5 # 4: 4 0 # 5: 5 0
https://www.rdocumentation.org/packages/data.table/versions/1.12.8/topics/shift
DT = data.table(year=2010:2014, v1=runif(5), v2=1:5, v3=letters[1:5])
# with names automatically set
DT[, shift(.SD, n=1:2, fill=NA, type="lag", give.names=TRUE), .SDcols=2:4]
# lag columns 'v1,v2,v3' DT by 1 and fill with 0
cols = c("v1","v2","v3")
anscols = str_c("lead", cols, sep="_")
DT[ , (anscols) := shift(.SD, n=1, fill=NA, type="lead"), .SDcols=cols]
# lag/lead in the right order
DT = DT[sample(nrow(DT))]
DT[order(year), (anscols) := shift(.SD, n=1, fill=NA, type="lead"), .SDcols=cols]
shift() vs. diff()
shift(x, n=1L, fill=NA, type=c("lag", "lead", "shift"), give.names=FALSE)
set.seed(666) DT <- data.table(A=sample(1:10, 6)) #-------------------------------------- DT[ , lagA:= shift(A, n=1, fill=0)] DT[ , lagDiff1:= A - shift(A, fill=0)] DT[ , lagDiff2:= A - shift(A)] DT[is.na(lagDiff2), lagDiff2:=0] DT[ , oriDiff:= c(0, diff(A))] # A lagA lagDiff1 lagDiff2 oriDiff # 1: 8 0 8 0 0 # 2: 2 8 -6 -6 -6 # 3: 10 2 8 8 8 # 4: 9 10 -1 -1 -1 # 5: 3 9 -6 -6 -6 # 6: 4 3 1 1 1
lapply(.SD 활용
DT[3:5,] DT[, .SD[3:5]] #identical
A B C D
1: b 3 5 4
2: b 1 3 2
3: c 2 4 1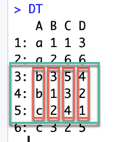
data.table에서는 colSums보다는 lapply(.SD,...) 을 많이 사용한다. cf. rowSums은 rowSums
DT[ , lapply(.SD, sum), .SDcols=2:4]
B C D
1: 12 21 21DT[ , colSums(.SD), .SDcols=!"A"]
B C D
12 21 21 .SD는 lapply에서 Column 기준으로 반복
DT[, .SD[2], by=A] # 2nd row of each group (group by)
DT[, lapply(.SD, sum), by=A, .SDcols=2:4] # colSums of each group (group by)
DT[, lapply(.SD, function(x){is.numeric(x)})]
# 2nd row of each group
A B C D
1: a 2 6 6
2: b 1 3 2
3: c 3 2 5
# colSums of each group
A B C D
1: a 3 7 9
2: b 4 8 6
3: c 5 6 6
#
A B C D
1: FALSE TRUE TRUE TRUE
숫자인 열만 가져오기
data <- iris setDT(data)[ , .SD, .SDcols=is.numeric]
NA 처리
df는 Logical(T/F) matrix를 이용한 Indexing이 가능하지만, data.table은 다르다. (http://onesixx.com/indexing/ )
set.seed(666)
df <- data.frame(
a=sample(c(1,2,NA), 10, replace=T),
b=sample(c(1,2,NA), 10, replace=T),
c=sample(c(1:5,NA), 10, replace=T))
df[is.na(df)]<-0
colNm <- c("a","b")
df[,colNm][is.na(df[,colNm])]<-0
colIdx <- c(1:2)
df[,colIdx][is.na(df[,colIdx])]<-0
colIdx <- c(1:2)
for(i in colIdx){
df[,i][is.na(df[,i])]<-0
}","showLines":false,"wrapLines":false,"highlightStart":"9","highlightEnd":"18 set.seed(666) DT <- data.table( a=sample(c(1,2,NA), 10, replace=T), b=sample(c(1,2,NA), 10, replace=T), c=sample(c(1:5,NA), 10, replace=T)) # a b c # 1: NA NA NA # 2: 1 1 4 # 3: NA 1 1 # 4: 1 1 1 # 5: 2 1 5 # 6: NA NA 2 # 7: NA 1 1 # 8: 2 NA 4 # 9: 1 2 4 # 10: 1 2 NA
DT[is.na(DT)] <- 0 # data.table은 이것만 가능
remove NA rows
> na.omit(DT) > DT[ is.finite(rowSums(DT))] a b c 1: 1 1 4 2: 1 1 1 3: 2 1 5 4: 1 2 4
https://stackoverflow.com/questions/7235657/fastest-way-to-replace-nas-in-a-large-data-table
colNm <- c("a","b")
colIdx <- c(1:2)
f_dowle3 = function(DT) {
# by name :
for (j in names(DT))
set(DT,which(is.na(DT[[j]])),j,0)
for (j in colNm)
set(DT,which(is.na(DT[,..j])),j,0)
# by number : (slightly faster than by name) :
for (j in seq_len(ncol(DT)))
set(DT,which(is.na(DT[[j]])),j,0)
for (j in colIdx)
set(DT,which(is.na(DT[,..j])),j,0)
}
setDT() vs. as.data.table()
setDT()
typeof()가 list인 object를 data.table로 변환해 준다.
(vector나 column이 하나인 list, matrix, array는 에러난다. )
Copy없이 같은 list를 공유하면서 만들기 때문에 memory 주소가 같다. tracemem()
as.data.table()
Type 상관없이 data.table로 모두 변환해 준다
Copy해서 만들기 때문에 memory 주소가 다르다. tracemem()
Special symbols
?"special-symbols"
. .SD .SDcols .I .N .GRP .BY .EACHI.SD, .BY, .N, .I and .GRP are read only symbols for use in j. (.N can be used in i as well)
.I (row순번) .N (row 갯수)
DT[, .I] # row number DT[, .I[2], by=A] # 2nd row number of each group
[1] 1 2 3 4 5 6
A V1
1: a 2
2: b 4
3: c 6DT[, .N] # total number of rows in DT nrow(DT) # identical DT[, .N, by=A][order(-A)] # number of rows in each group
[1] 6
A N
1: a 2
2: b 2
3: c 2.GRP
DT[, grp := .GRP, by=x] # add a group counter column
.BY
X[, DT[.BY, y, on="x"], by=x] # join within each group
:=
data.table's reference semantics vignette
update, data의 불필요한 Copy를 방지
Subsetting의 인덱싱 결과는 또 다른 새로운 data.table이다.(즉 원래 DT에 재할당하지 않는 이상, DT는 변하지 않고 유지된다) 따라서, DT의 size가 big한 경우, := 를 사용하여 컬럼을 참조하여 update함으로써 data의 불필요한 Copy를 방지한다.
Column Type변환
cName <- c('A')
DT[ , (cName):= lapply(.SD, as.factor), .SDcols=cName]
cIdx <- which(sapply(DT, is.character))
DT[ , (cIdx):=lapply(.SD, as.factor), .SDcols=cIdx]
여러 방법을 통해 out_idx를 정의하고, 해당 컬럼에 함수(as.factor)를 적용하여, column type을 covert한다.
data.table이 각 element가 column인 list로 여겨질수 있다는 것이다.
(out_idx)를 괄호로 감싸는 이유는 컬럼명으로 인식하게 하기 위해.
Data.Frame을 사용해서도 같은 결과를 얻을수 있다.
setDF(DT) # convert to data.frame for illustration sapply(DT[ ,out_idx], is.character)
Transpose
> fread(valuePath)
V1 x
1: PER 16.7
2: PBR 1.4
3: PCR 7.9
4: PSR 1.6
> fread(valuePath) %>% transpose(make.names="V1")
PER PBR PCR PSR
1: 16.7 1.4 7.9 1.6
> fread(valuePath) %>% transpose(keep.names="names")
names V1 V2 V3 V4
1: V1 PER PBR PCR PSR
2: x 16.7 1.4 7.9 1.6
https://github.com/Rdatatable/data.table/wiki/Getting-started
https://stackoverflow.com/questions/1299871/how-to-join-merge-data-frames-inner-outer-left-right
https://stackoverflow.com/questions/8508482/what-does-sd-stand-for-in-data-table-in-r
https://www.analyticsvidhya.com/blog/2016/05/data-table-data-frame-work-large-data-sets/
Use of lapply .SD in data.table R
HTML vignettes: https://github.com/Rdatatable/data.table/wiki/Getting-started
예제
#http://onesixx.com/data-nycflights13/
flights <- nycflights13::flights %>% as.data.table()
#Calculate total number of rows by month and then sort on descending order
flights[, .N, by = month] [order(-N)]
#Find top 3 months with high mean arrival delay
flights[, .(mean_delay=mean(arr_delay, na.rm=T)), by=month][order(-mean_delay)][1:3]
#Find 출발공항(origin) having average total delay is greater than 20 minutes
flights[, lapply(.SD, mean, na.rm=T), .SDcols=c("arr_delay", "dep_delay"), by=origin][(arr_delay+dep_delay)>20]
#Extract average of arrival and departure delays for carrier == 'DL' by 'origin' and 'dest' variables
flights[carrier=='DL', lapply(.SD, mean, na.rm=T), by=.(origin, dest), .SDcols=c("arr_delay", "dep_delay")]
#Pull first value of 'air_time' by 'origin' and then sum the returned values when it is greater than 300
mydata[, .SD[1], .SDcols="air_time", by=origin][air_time > 300, sum(air_time)]
> example(data.table)
dt.tbl> DF = data.frame(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9)
dt.tbl> DT = data.table(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9)
# ---------------------------------------------------------
dt.tbl> DF
x y v
1 b 1 1
2 b 3 2
3 b 6 3
4 a 1 4
5 a 3 5
6 a 6 6
7 c 1 7
8 c 3 8
9 c 6 9
dt.tbl> DT
x y v
1: b 1 1
2: b 3 2
3: b 6 3
4: a 1 4
5: a 3 5
6: a 6 6
7: c 1 7
8: c 3 8
9: c 6 9
dt.tbl> identical(dim(DT), dim(DF)) # TRUE
dt.tbl> identical(DF$a, DT$a) # TRUE
dt.tbl> is.list(DF) # TRUE
dt.tbl> is.list(DT) # TRUE
dt.tbl> is.data.frame(DT) # TRUE
dt.tbl> tables()
NAME NROW NCOL MB COLS KEY
1: DT 9 3 0 x,y,v
# ---------------------------------------------------------
# basic row subset operations
dt.tbl> DT[2] # 2nd row
x y v
1: b 3 2
dt.tbl> DT[3:2] # 3rd and 2nd row
x y v
1: b 6 3
2: b 3 2
dt.tbl> DT[y>2] # all rows where DT$y > 2
x y v
1: b 3 2
2: b 6 3
3: a 3 5
4: a 6 6
5: c 3 8
6: c 6 9
dt.tbl> DT[y>2 & v>5] # compound logical expressions
x y v
1: a 6 6
2: c 3 8
3: c 6 9
dt.tbl> DT[!2:4] # all rows other than 2:4
dt.tbl> DT[-(2:4)] # same
x y v
1: b 1 1
2: a 3 5
3: a 6 6
4: c 1 7
5: c 3 8
6: c 6 9
dt.tbl> DT[order(x)] # no need for order(DT$x)
dt.tbl> DT[order(x), ] # same as above. The ',' is optional
x y v
1: a 1 4
2: a 3 5
3: a 6 6
4: b 1 1
5: b 3 2
6: b 6 3
7: c 1 7
8: c 3 8
9: c 6 9
# ---------------------------------------------------------
# select|compute columns data.table way
dt.tbl> DT[, v] # v column (as vector)
[1] 1 2 3 4 5 6 7 8 9
dt.tbl> DT[, list(v)] # v column (as data.table)
dt.tbl> DT[, .(v)] # same as above, .() is a shorthand alias to list()
dt.tbl> DT[, c("v")]
dt.tbl> DT[, c(3)]
dt.tbl> DT[, c(FALSE,FALSE,TRUE)]
v
1: 1
2: 2
3: 3
4: 4
5: 5
6: 6
7: 7
8: 8
9: 9
dt.tbl> DT[, sum(v)] # sum of column v, returned as vector
[1] 45
dt.tbl> DT[, .(sum(v))] # same, but return data.table (column autonamed V1)
V1
1: 45
dt.tbl> DT[, .(sv=sum(v))] # same, but column named "sv"
sv
1: 45
dt.tbl> DT[, .(v, v*2)] # return two column data.table, v and v*2
v V2
1: 1 2
2: 2 4
3: 3 6
4: 4 8
5: 5 10
6: 6 12
7: 7 14
8: 8 16
9: 9 18
# ---------------------------------------------------------
# subset rows and select|compute data.table way
dt.tbl> DT[2:3, sum(v)] # sum(v) over rows 2 and 3, return vector
[1] 5
dt.tbl> DT[2:3, .(sum(v))] # same, but return data.table with column V1
V1
1: 5
dt.tbl> DT[2:3, .(sv=sum(v))] # same, but return data.table with column sv
sv
1: 5
dt.tbl> DT[2:5, cat(v, "\
")] # just for j's side effect
2 3 4 5
NULL
# ---------------------------------------------------------
# select columns the data.frame way
dt.tbl> DT[, 2] # 2nd column, returns a data.table always
y
1: 1
2: 3
3: 6
4: 1
5: 3
6: 6
7: 1
8: 3
9: 6
dt.tbl> colNum = 2 # to refer vars in `j` from the outside of data use `..` prefix
dt.tbl> DT[, ..colNum] # same, equivalent to DT[, .SD, .SDcols=colNum]
dt.tbl> DT[["v"]] # same as DT[, v] but much faster
[1] 1 2 3 4 5 6 7 8 9
# ---------------------------------------------------------
# grouping operations - j and by
dt.tbl> DT[, sum(v), by=x] # ad hoc by, order of groups preserved in result
x V1
1: b 6
2: a 15
3: c 24
dt.tbl> DT[, sum(v), keyby=x] # same, but order the result on by cols
x V1
1: a 15
2: b 6
3: c 24
dt.tbl> DT[, sum(v), by=x][order(x)] # same but by chaining expressions together
x V1
1: a 15
2: b 6
3: c 24
# ---------------------------------------------------------
# fast ad hoc row subsets (subsets as joins)
dt.tbl> DT[x=="a"] # same, single "==" internally optimised to use binary search (fast)
x y v
1: a 1 4
2: a 3 5
3: a 6 6
dt.tbl> DT["a", on="x"] # same as x == "a" but uses binary search (fast)
dt.tbl> DT["a", on=.(x)] # same, for convenience, no need to quote every column
dt.tbl> DT[.("a"), on="x"] # same
x y v
1: a 1 4
2: a 3 5
3: a 6 6
> DT
x y v
1: b 1 1
2: b 3 2
3: b 6 3
4: a 1 4
5: a 3 5
6: a 6 6
7: c 1 7
8: c 3 8
9: c 6 9
> DT[.(1:2), on=.(y)]
x y v
1: b 1 1
2: a 1 4
3: c 1 7
4: 2 NA
> DT[.(1:2), on=.(y), nomatch=NULL]
x y v
1: b 1 1
2: a 1 4
3: c 1 7
> DT[.(1:2), on=.(y), roll=Inf]
x y v
1: b 1 1
2: a 1 4
3: c 1 7
4: c 2 7
> DT[.(1:2), on=.(y), roll=-Inf]
x y v
1: b 1 1
2: a 1 4
3: c 1 7
4: b 2 2
dt.tbl> DT[x!="b" | y!=3] # not yet optimized, currently vector scan subset
x y v
1: b 1 1
2: b 6 3
3: a 1 4
4: a 3 5
5: a 6 6
6: c 1 7
7: c 3 8
8: c 6 9
dt.tbl> DT[x=="b" & y==3, ]
dt.tbl> DT[.("b", 3), on=c("x", "y")] # join on columns x,y of DT; uses binary search (fast)
dt.tbl> DT[.("b", 3), on=.(x, y)] # same, but using on=.()
x y v
1: b 3 2
dt.tbl> DT[.("b", 1:2), on=c("x", "y")] # no match returns NA
x y v
1: b 1 1
2: b 2 NA
dt.tbl> DT[.("b", 1:2), on=.(x, y), nomatch=NULL] # no match row is not returned
x y v
1: b 1 1
dt.tbl> DT[.("b", 1:2), on=c("x", "y"), roll=Inf] # locf, nomatch row gets rolled by previous row
x y v
1: b 1 1
2: b 2 1
dt.tbl> DT[.("b", 1:2), on=.(x, y), roll=-Inf] # nocb, nomatch row gets rolled by next row
x y v
1: b 1 1
2: b 2 2
dt.tbl> DT["b", sum(v*y), on="x"] # on rows where DT$x=="b", calculate sum(v*y)
[1] 25
# ---------------------------------------------------------
# all together now
dt.tbl> DT[x!="a", sum(v), by=x] # get sum(v) by "x" for each i != "a"
x V1
1: b 6
2: c 24
dt.tbl> DT[!"a", sum(v), by=.EACHI, on="x"] # same, but using subsets-as-joins
x V1
1: b 6
2: c 24
dt.tbl> DT[c("b","c"), sum(v), by=.EACHI, on="x"] # same
x V1
1: b 6
2: c 24
dt.tbl> DT[c("b","c"), sum(v), by=.EACHI, on=.(x)] # same, using on=.()
x V1
1: b 6
2: c 24
# ---------------------------------------------------------
# joins as subsets
dt.tbl> X = data.table(x=c("c","b"), v=8:7, foo=c(4,2))
x v foo
1: c 8 4
2: b 7 2
dt.tbl> DT[X, on="x"] # right join
x y v i.v foo
1: c 1 7 8 4
2: c 3 8 8 4
3: c 6 9 8 4
4: b 1 1 7 2
5: b 3 2 7 2
6: b 6 3 7 2
dt.tbl> X[DT, on="x"] # left join
x v foo y i.v
1: b 7 2 1 1
2: b 7 2 3 2
3: b 7 2 6 3
4: a NA NA 1 4
5: a NA NA 3 5
6: a NA NA 6 6
7: c 8 4 1 7
8: c 8 4 3 8
9: c 8 4 6 9
dt.tbl> DT[X, on="x", nomatch=NULL] # inner join
x y v i.v foo
1: c 1 7 8 4
2: c 3 8 8 4
3: c 6 9 8 4
4: b 1 1 7 2
5: b 3 2 7 2
6: b 6 3 7 2
dt.tbl> DT[!X, on="x"] # not join
x y v
1: a 1 4
2: a 3 5
3: a 6 6
dt.tbl> DT[X, on=c(y="v")] # join using column "y" of DT with column "v" of X
x y v i.x foo
1: 8 NA c 4
2: 7 NA b 2
dt.tbl> DT[X, on="y==v"] # same as above (v1.9.8+)
x y v i.x foo
1: 8 NA c 4
2: 7 NA b 2
dt.tbl> DT[X, on=.(y<=foo)] # NEW non-equi join (v1.9.8+)
x y v i.x i.v
1: b 4 1 c 8
2: b 4 2 c 8
3: a 4 4 c 8
4: a 4 5 c 8
5: c 4 7 c 8
6: c 4 8 c 8
7: b 2 1 b 7
8: a 2 4 b 7
9: c 2 7 b 7
dt.tbl> DT[X, on="y<=foo"] # same as above
x y v i.x i.v
1: b 4 1 c 8
2: b 4 2 c 8
3: a 4 4 c 8
4: a 4 5 c 8
5: c 4 7 c 8
6: c 4 8 c 8
7: b 2 1 b 7
8: a 2 4 b 7
9: c 2 7 b 7
dt.tbl> DT[X, on=c("y<=foo")] # same as above
x y v i.x i.v
1: b 4 1 c 8
2: b 4 2 c 8
3: a 4 4 c 8
4: a 4 5 c 8
5: c 4 7 c 8
6: c 4 8 c 8
7: b 2 1 b 7
8: a 2 4 b 7
9: c 2 7 b 7
dt.tbl> DT[X, on=.(y>=foo)] # NEW non-equi join (v1.9.8+)
x y v i.x i.v
1: b 4 3 c 8
2: a 4 6 c 8
3: c 4 9 c 8
4: b 2 2 b 7
5: b 2 3 b 7
6: a 2 5 b 7
7: a 2 6 b 7
8: c 2 8 b 7
9: c 2 9 b 7
dt.tbl> DT[X, on=.(x, y<=foo)] # NEW non-equi join (v1.9.8+)
x y v i.v
1: c 4 7 8
2: c 4 8 8
3: b 2 1 7
dt.tbl> DT[X, .(x,y,x.y,v), on=.(x, y>=foo)] # Select x's join columns as well
x y x.y v
1: c 4 6 9
2: b 2 3 2
3: b 2 6 3
dt.tbl> DT[X, on="x", mult="first"] # first row of each group
x y v i.v foo
1: c 1 7 8 4
2: b 1 1 7 2
dt.tbl> DT[X, on="x", mult="last"] # last row of each group
x y v i.v foo
1: c 6 9 8 4
2: b 6 3 7 2
dt.tbl> DT[X, sum(v), by=.EACHI, on="x"] # join and eval j for each row in i
x V1
1: c 24
2: b 6
dt.tbl> DT[X, sum(v)*foo, by=.EACHI, on="x"] # join inherited scope
x V1
1: c 96
2: b 12
dt.tbl> DT[X, sum(v)*i.v, by=.EACHI, on="x"] # 'i,v' refers to X's v column
x V1
1: c 192
2: b 42
dt.tbl> DT[X, on=.(x, v>=v), sum(y)*foo, by=.EACHI] # NEW non-equi join with by=.EACHI (v1.9.8+)
x v V1
1: c 8 36
2: b 7 NA
# ---------------------------------------------------------
# setting keys
dt.tbl> kDT = copy(DT) # (deep) copy DT to kDT to work with it.
dt.tbl> setkey(kDT,x) # set a 1-column key. No quotes, for convenience.
dt.tbl> setkeyv(kDT,"x") # same (v in setkeyv stands for vector)
dt.tbl> v="x"
dt.tbl> setkeyv(kDT,v) # same
dt.tbl> # key(kDT)<-"x" # copies whole table, please use set* functions instead
dt.tbl> haskey(kDT) # TRUE
[1] TRUE
dt.tbl> key(kDT) # "x"
[1] "x"
dt.tbl> # fast *keyed* subsets
dt.tbl> kDT["a"] # subset-as-join on *key* column 'x'
x y v
1: a 1 4
2: a 3 5
3: a 6 6
dt.tbl> kDT["a", on="x"] # same, being explicit using 'on=' (preferred)
x y v
1: a 1 4
2: a 3 5
3: a 6 6
dt.tbl> # all together
dt.tbl> kDT[!"a", sum(v), by=.EACHI] # get sum(v) for each i != "a"
x V1
1: b 6
2: c 24
dt.tbl> # multi-column key
dt.tbl> setkey(kDT,x,y) # 2-column key
dt.tbl> setkeyv(kDT,c("x","y")) # same
dt.tbl> # fast *keyed* subsets on multi-column key
dt.tbl> kDT["a"] # join to 1st column of key
x y v
1: a 1 4
2: a 3 5
3: a 6 6
dt.tbl> kDT["a", on="x"] # on= is optional, but is preferred
x y v
1: a 1 4
2: a 3 5
3: a 6 6
dt.tbl> kDT[.("a")] # same, .() is an alias for list()
x y v
1: a 1 4
2: a 3 5
3: a 6 6
dt.tbl> kDT[list("a")] # same
x y v
1: a 1 4
2: a 3 5
3: a 6 6
dt.tbl> kDT[.("a", 3)] # join to 2 columns
x y v
1: a 3 5
dt.tbl> kDT[.("a", 3:6)] # join 4 rows (2 missing)
x y v
1: a 3 5
2: a 4 NA
3: a 5 NA
4: a 6 6
dt.tbl> kDT[.("a", 3:6), nomatch=NULL] # remove missing
x y v
1: a 3 5
2: a 6 6
dt.tbl> kDT[.("a", 3:6), roll=TRUE] # locf rolling join
x y v
1: a 3 5
2: a 4 5
3: a 5 5
4: a 6 6
dt.tbl> kDT[.("a", 3:6), roll=Inf] # same as above
x y v
1: a 3 5
2: a 4 5
3: a 5 5
4: a 6 6
dt.tbl> kDT[.("a", 3:6), roll=-Inf] # nocb rolling join
x y v
1: a 3 5
2: a 4 6
3: a 5 6
4: a 6 6
dt.tbl> kDT[!.("a")] # not join
x y v
1: b 1 1
2: b 3 2
3: b 6 3
4: c 1 7
5: c 3 8
6: c 6 9
dt.tbl> kDT[!"a"] # same
x y v
1: b 1 1
2: b 3 2
3: b 6 3
4: c 1 7
5: c 3 8
6: c 6 9
dt.tbl> # more on special symbols, see also ?"special-symbols"
dt.tbl> DT[.N] # last row
x y v
1: c 6 9
dt.tbl> DT[, .N] # total number of rows in DT
[1] 9
dt.tbl> DT[, .N, by=x] # number of rows in each group
x N
1: b 3
2: a 3
3: c 3
dt.tbl> DT[, .SD, .SDcols=x:y] # select columns 'x' through 'y'
x y
1: b 1
2: b 3
3: b 6
4: a 1
5: a 3
6: a 6
7: c 1
8: c 3
9: c 6
dt.tbl> DT[ , .SD, .SDcols = !x:y] # drop columns 'x' through 'y'
v
1: 1
2: 2
3: 3
4: 4
5: 5
6: 6
7: 7
8: 8
9: 9
dt.tbl> DT[ , .SD, .SDcols = patterns('^[xv]')] # select columns matching '^x' or '^v'
x v
1: b 1
2: b 2
3: b 3
4: a 4
5: a 5
6: a 6
7: c 7
8: c 8
9: c 9
dt.tbl> DT[, .SD[1]] # first row of all columns
x y v
1: b 1 1
dt.tbl> DT[, .SD[1], by=x] # first row of 'y' and 'v' for each group in 'x'
x y v
1: b 1 1
2: a 1 4
3: c 1 7
dt.tbl> DT[, c(.N, lapply(.SD, sum)), by=x] # get rows *and* sum columns 'v' and 'y' by group
x N y v
1: b 3 10 6
2: a 3 10 15
3: c 3 10 24
dt.tbl> DT[, .I[1], by=x] # row number in DT corresponding to each group
x V1
1: b 1
2: a 4
3: c 7
dt.tbl> DT[, grp := .GRP, by=x] # add a group counter column
x y v grp
1: b 1 1 1
2: b 3 2 1
3: b 6 3 1
4: a 1 4 2
5: a 3 5 2
6: a 6 6 2
7: c 1 7 3
8: c 3 8 3
9: c 6 9 3
dt.tbl> X[, DT[.BY, y, on="x"], by=x] # join within each group
x V1
1: c 1
2: c 3
3: c 6
4: b 1
5: b 3
6: b 6
dt.tbl> # add/update/delete by reference (see ?assign)
dt.tbl> print(DT[, z:=42L]) # add new column by reference
x y v grp z
1: b 1 1 1 42
2: b 3 2 1 42
3: b 6 3 1 42
4: a 1 4 2 42
5: a 3 5 2 42
6: a 6 6 2 42
7: c 1 7 3 42
8: c 3 8 3 42
9: c 6 9 3 42
dt.tbl> print(DT[, z:=NULL]) # remove column by reference
x y v grp
1: b 1 1 1
2: b 3 2 1
3: b 6 3 1
4: a 1 4 2
5: a 3 5 2
6: a 6 6 2
7: c 1 7 3
8: c 3 8 3
9: c 6 9 3
dt.tbl> print(DT["a", v:=42L, on="x"]) # subassign to existing v column by reference
x y v grp
1: b 1 1 1
2: b 3 2 1
3: b 6 3 1
4: a 1 42 2
5: a 3 42 2
6: a 6 42 2
7: c 1 7 3
8: c 3 8 3
9: c 6 9 3
dt.tbl> print(DT["b", v2:=84L, on="x"]) # subassign to new column by reference (NA padded)
x y v grp v2
1: b 1 1 1 84
2: b 3 2 1 84
3: b 6 3 1 84
4: a 1 42 2 NA
5: a 3 42 2 NA
6: a 6 42 2 NA
7: c 1 7 3 NA
8: c 3 8 3 NA
9: c 6 9 3 NA
dt.tbl> DT[, m:=mean(v), by=x][] # add new column by reference by group
x y v grp v2 m
1: b 1 1 1 84 2
2: b 3 2 1 84 2
3: b 6 3 1 84 2
4: a 1 42 2 NA 42
5: a 3 42 2 NA 42
6: a 6 42 2 NA 42
7: c 1 7 3 NA 8
8: c 3 8 3 NA 8
9: c 6 9 3 NA 8
dt.tbl> # NB: postfix [] is shortcut to print()
dt.tbl> # advanced usage
dt.tbl> DT = data.table(x=rep(c("b","a","c"),each=3), v=c(1,1,1,2,2,1,1,2,2), y=c(1,3,6), a=1:9, b=9:1)
dt.tbl> DT[, sum(v), by=.(y%%2)] # expressions in by
y V1
1: 1 9
2: 0 4
dt.tbl> DT[, sum(v), by=.(bool = y%%2)] # same, using a named list to change by column name
bool V1
1: 1 9
2: 0 4
dt.tbl> DT[, .SD[2], by=x] # get 2nd row of each group
x v y a b
1: b 1 3 2 8
2: a 2 3 5 5
3: c 2 3 8 2
dt.tbl> DT[, tail(.SD,2), by=x] # last 2 rows of each group
x v y a b
1: b 1 3 2 8
2: b 1 6 3 7
3: a 2 3 5 5
4: a 1 6 6 4
5: c 2 3 8 2
6: c 2 6 9 1
dt.tbl> DT[, lapply(.SD, sum), by=x] # sum of all (other) columns for each group
x v y a b
1: b 3 10 6 24
2: a 5 10 15 15
3: c 5 10 24 6
dt.tbl> DT[, .SD[which.min(v)], by=x] # nested query by group
x v y a b
1: b 1 1 1 9
2: a 1 6 6 4
3: c 1 1 7 3
dt.tbl> DT[, list(MySum=sum(v),
dt.tbl+ MyMin=min(v),
dt.tbl+ MyMax=max(v)),
dt.tbl+ by=.(x, y%%2)] # by 2 expressions
x y MySum MyMin MyMax
1: b 1 2 1 1
2: b 0 1 1 1
3: a 1 4 2 2
4: a 0 1 1 1
5: c 1 3 1 2
6: c 0 2 2 2
dt.tbl> DT[, .(a = .(a), b = .(b)), by=x] # list columns
x a b
1: b 1,2,3 9,8,7
2: a 4,5,6 6,5,4
3: c 7,8,9 3,2,1
dt.tbl> DT[, .(seq = min(a):max(b)), by=x] # j is not limited to just aggregations
x seq
1: b 1
2: b 2
3: b 3
4: b 4
5: b 5
6: b 6
7: b 7
8: b 8
9: b 9
10: a 4
11: a 5
12: a 6
13: c 7
14: c 6
15: c 5
16: c 4
17: c 3
dt.tbl> DT[, sum(v), by=x][V1<20] # compound query
x V1
1: b 3
2: a 5
3: c 5
dt.tbl> DT[, sum(v), by=x][order(-V1)] # ordering results
x V1
1: a 5
2: c 5
3: b 3
dt.tbl> DT[, c(.N, lapply(.SD,sum)), by=x] # get number of observations and sum per group
x N v y a b
1: b 3 3 10 6 24
2: a 3 5 10 15 15
3: c 3 5 10 24 6
dt.tbl> DT[, {tmp <- mean(y);
dt.tbl+ .(a = a-tmp, b = b-tmp)
dt.tbl+ }, by=x] # anonymous lambda in 'j', j accepts any valid
x a b
1: b -2.3333333 5.6666667
2: b -1.3333333 4.6666667
3: b -0.3333333 3.6666667
4: a 0.6666667 2.6666667
5: a 1.6666667 1.6666667
6: a 2.6666667 0.6666667
7: c 3.6666667 -0.3333333
8: c 4.6666667 -1.3333333
9: c 5.6666667 -2.3333333
dt.tbl> # expression. TO REMEMBER: every element of
dt.tbl> # the list becomes a column in result.
dt.tbl> pdf("new.pdf")
dt.tbl> DT[, plot(a,b), by=x] # can also plot in 'j'
Empty data.table (0 rows) of 1 col: x
dt.tbl> dev.off()
pdf
2
dt.tbl> # using rleid, get max(y) and min of all cols in .SDcols for each consecutive run of 'v'
dt.tbl> DT[, c(.(y=max(y)), lapply(.SD, min)), by=rleid(v), .SDcols=v:b]
rleid y v y a b
1: 1 6 1 1 1 7
2: 2 3 2 1 4 5
3: 3 6 1 1 6 3
4: 4 6 2 3 8 1
dt.tbl> # Support guide and links:
dt.tbl> # https://github.com/Rdatatable/data.table/wiki/Support
dt.tbl>
dt.tbl> ## Not run:
dt.tbl> ##D if (interactive()) {
dt.tbl> ##D vignette("datatable-intro")
dt.tbl> ##D vignette("datatable-reference-semantics")
dt.tbl> ##D vignette("datatable-keys-fast-subset")
dt.tbl> ##D vignette("datatable-secondary-indices-and-auto-indexing")
dt.tbl> ##D vignette("datatable-reshape")
dt.tbl> ##D vignette("datatable-faq")
dt.tbl> ##D
dt.tbl> ##D test.data.table() # over 6,000 low level tests
dt.tbl> ##D
dt.tbl> ##D # keep up to date with latest stable version on CRAN
dt.tbl> ##D update.packages()
dt.tbl> ##D
dt.tbl> ##D # get the latest devel version
dt.tbl> ##D update.dev.pkg()
dt.tbl> ##D # compiled devel binary for Windows available -- no Rtools needed
dt.tbl> ##D update.dev.pkg(repo="https://Rdatatable.github.io/data.table")
dt.tbl> ##D # read more at:
dt.tbl> ##D # https://github.com/Rdatatable/data.table/wiki/Installation
dt.tbl> ##D }
dt.tbl> ## End(Not run) 