json to pandas
JSON과 Dictionary의 차이
JSON은 데이터를 교환하기 위한 형식으로, Dictionary는 자료형 중 하나
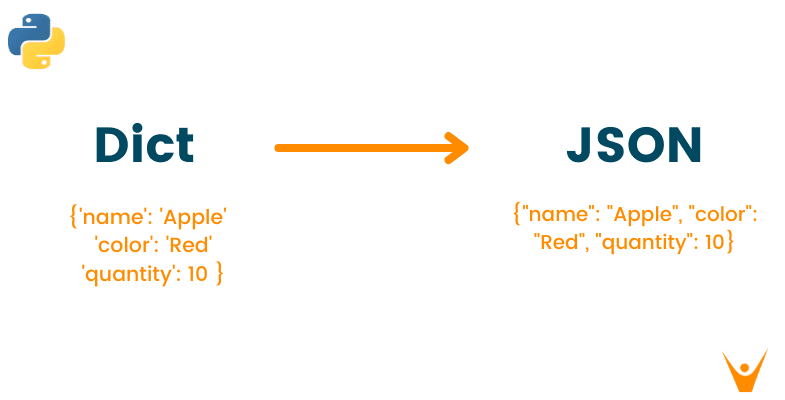
json.dump()를 하면, 데이터가 str타입으로 되기 때문에,
json(str)을 dictionary로 변환후, Key를 활용해 접근하는 방법이 일반적.
import json import requests url = 'localhost:8000/api/example' res = requests.get(url) type(res.text)\t# str res.['key-name']\t# 오류 res = json.loads(res.text) type(res.text)\t# dictionary res.['key-name'] # 가능
JSON을 Pandas DataFrame로 변환하는방법
json_normalize()를 사용read_json()을 사용- DataFrame.from_dict()
JSON(JavaScript Object Notation)
중첩 된 목록과 사전의 조합
{
"Results":[
{ "id": "01", "Name": "Jay" },
{ "id": "02", "Name": "Mark" },
{ "id": "03", "Name": "Jack" }
],
"status": ["ok"]
}
json_normalize() 사용
json_normalize()함수는 중첩 된 JSON 문자열을 읽고 DataFrame을 반환하는 데 매우 널리 사용됩니다. 이 함수를 사용하려면 먼저 Python의 JSON 라이브러리에있는json.loads()함수를 사용하여 JSON 문자열을 읽어야합니다. 그런 다음이 JSON 객체를json_normalize()에 전달하면 필요한 데이터가 포함 된 Pandas DataFrame이 반환됩니다.
import pandas as pd
import json
from pandas import json_normalize
data = '''
{
"Results":
[
{ "id": "1", "Name": "Jay" },
{ "id": "2", "Name": "Mark" },
{ "id": "3", "Name": "Jack" }
],
"status": ["ok"]
}
'''
# dict만들기
info = json.loads(data)
df = json_normalize(info['Results']) #Results contain the required data
print(df)
# id Name
# 0 1 Jay
# 1 2 Mark
# 2 3 Jack
json_normalize은 그 내용이 json인지 알지 못한다. 미리 load해서 알려주고 시작
df = info['Results'].apply(json_to_series) ==> df = info['Results'].apply(json.loads) df = pd.json_normalize(expanded_datascope)
read_json()
read_json()에는 많은 매개 변수가 있으며,
그중orient는 JSON 문자열의 형식을 지정합니다.
단점은 중첩된 JSON 문자열과 함께 사용하기 어렵다는 것입니다.
따라서read_json()을 사용하기 위해 아래와 같이 훨씬 더 간단한 예제를 사용합니다.
data = '''
{
"0":{"Name": "Jay", "Age": "17"},
"1":{"Name": "Mark", "Age": "15"},
"2":{"Name": "Jack", "Age": "16"}
}
'''
df = pd.read_json(data, orient ='index')
print(df)
# Name Age
# 0 Jay 17
# 1 Mark 15
# 2 Jack
JSON 문자열 fromat이 패턴과 {index: {column: value}}와 일치하기 때문에orient를'index'로 설정합니다.
DataFrame.from_dict()
pd.DataFrame.from_dict(data, orient="index")
key를 index로 활용하여 DataFrame을 만든다.
해당하는 orient 파라미터는 columns으로 세팅하면 key를 column으로 사용
index/ columns/ tight
data = '''
{
"Courses": "Spark",
"Fee": 22000,
"Duration":"40Days"
}
'''
myDic = json.loads(data)
# Use pandas.DataFrame.from_dict() to Convert JSON to DataFrame
df1 = pd.DataFrame.from_dict(myDic, orient="index")
# 0
# Courses\tSpark
# Fee\t22000
# Duration\t40Days
df2 = pd.DataFrame.from_dict([myDic], orient="columns")
# \tCourses\t Fee\tDuration
# 0\t 1\t22000\t40
JSON 문자열 fromat이 패턴과 {index: {column: value}}와 일치하기 때문에orient를'index'로 설정합니다.
from memory_profiler import profile
import multiprocessing as mp
import sys
import time
import string
import math
import re
from datetime import datetime
import json
import ijson
import pandas as pd
import numpy as np
import plotly.graph_objects as go
import plotly.express as px
# pd.set_option('display.max_row', 500)
# pd.set_option('display.max_columns', 100)
# pd.set_option('display.max_seq_items', None)
# pd.options.plotting.backend = "plotly" # matplotlib
# pd.options.display.float_format = '{:.2f}'.format
# pd.options.display.float_format = '{:.5f}'.format
BasePath = '../app/data/'
filePath = BasePath + f'mobi_data/mobi1/mobility1_01.json'
key_remain = ['mobiId', 'mobiTypCd', 'mobiTypNm', 'userId', 'userNm', # 'interfaceDate',
'created', 'ctrlServId', 'mobiRegiNum', 'battId', 'eventName',
'eventCode', 'rentalState', 'rentalStateName']
alist = []
with open(filePath, "r") as multiline:
for line in multiline:
jdict = json.loads(line)
jdata = {}
jdata.update({k: v for k, v in jdict.items() if k in key_remain})
jdata.update(jdict['gps'])
jdata.update(jdict['battery'])
alist.append(jdata)
print(len(alist))
data = pd.DataFrame(alist)
# data.memory_usage()
j=1
parquetPath = BasePath + f'mobility1_0{j}.parquet'
data.to_parquet(parquetPath)
if __name__ == "__main__":
args = sys.argv
_time_s = time.time()
result = main(args)
_time_e = time.time()
print(_time_e-_time_s)
print(result)
result.shape
parquetPath = BasePath + f'mobility1_0{j}.parquet'
result.to_parquet(parquetPath)
