IoU(Intersection over Union)
https://ballentain.tistory.com/12
IoU 란?
IOU적용을 위해 필요한 2가지
- Ground-truth 바운딩박스 (TestSet에서 Obj위치를 라벨링한것)
- Predicted 바운딩박스 (model에서 Obj위치 예측값)
Object dectector정확도에 대한 Metric (성능평가지표)
: 모델의 Predicted(예측)값과 ground Truth(실측)가 얼마나 정확하게 겹치는가를 나타내는 지표.
obj. detection에서 사용되는 도구.
IoU = 교집합 영역 넓이 / 합집합 영역 넓이
IoU의 threshold 값으로 0.5를 많이 사용함.
ex) Pascal VOC에서는 IoU가 0.5 이상이면 obj. Detection을 성공했다고 간주함.
box의 크기가 동일하다고 가정하면,
두 box의 2/3는 겹쳐줘야 0.5의 값이 나오기 때문에,


다음과 같이 딥러닝 모델의 성능을 비교 가능
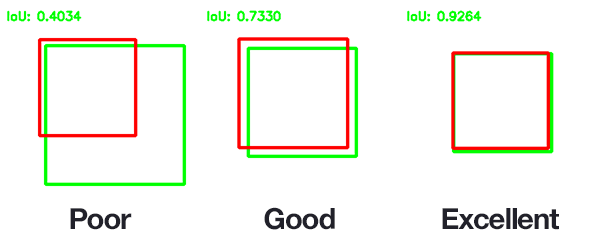
모델의 성능을 높여보고자 IoU threshold 값을 올려서 모델링을 해도 되기는 하는데,
모델 성능이라는 게 IOU이외에도 feature extractor, classifier, regressor, NMS 등 복합적이기 때문에
threshold 값을 올려준다해서 무조건 성능이 올라가는 현상을 기대해서는 안 되는 것 같다.
ground-truth
Ground-truth는 데이터의 label값으로 이해해도 무리는 없지만, 그렇다고, label은 아니다.
https://mac-user-guide.tistory.com/entry/머신러닝AI에서-사용되는-Ground-Truth-뜻
“ground-truth”과 “label”은 같지 않다.
- label : 정답 (명확히 정해진 답)
- ground-truth: 문제에서 정한 정답 (모델이 우리가 원하는 답으로 예측해주길 바라는 답)
예> 모델을 훈련시킬 데이터로 아래 사진이라고 한다면,
label, 즉 정답은 없다. 사람인 것도, 고양인 것도 아니다.
ground-truth는 (분류모델이 아래사진으로 ‘고양이’로 분류하길 원하다면) 원하는 답인 ‘고양이’

더 깊게 알아보자
object detection model 훈련 과정, 예측 과정 등 여러 곳에서 IOU유용하게 쓰인다.
R-CNN에서는
pretrained CNN에 proposed region을 넣어서 뽑아낸 feature map을 SVM으로 분류하기 위해
SVM을 학습 시키는 과정에 사용된다.

R-CNN의 흐름은 다음과 같다.
- selective search 알고리즘으로 한 개의 이미지에서 약 2000개의 Bounding Box(proposed region)를 만든다.
- 잘라낸 약 2000개의 이미지들을 객체후보군으로 가정한 상태로, 훈련을 진행한다.
다시 말하면, object detection을 위해 R-CNN은 classification 문제의 경우 일반적인 classification과 같은 방법을 사용하고, 객체의 위치 추적 기능의 경우 region proposal 알고리즘( = selective search)을 사용한다는 말이다. - 이해를 위해 2000개의 proposed region들 중 한 개로 범위를 좁혀서 봐보자.
ground truth(갈색)이고 proposed region(보라색( 및 회색 영역))들 중 하나에 해당된다.
잘려진 이미지(두번째 이미지)를 pretrained CNN에 넣어 feature map을 뽑아낸 후, 이 feature map으로 두 가지 모델의 학습을 진행한다.
하나는 SVM으로 classification 학습을 진행하는 것이고,
다른 하나는 proposed region에 객체가 포함되어 있을 경우( = 배경이 아닐 경우) proposed region의 좌표가 실제 ground truth와 같아질 수 있도록 regression 학습을 하는 것이다. - 예측 과정에서는 ground truth 없이 오로지 학습된 가중치 값들만을 갖고 예측이 진행된다.
feature map을 SVM에 넣어 classification을 진행해서 배경이 아닌 객체로 분류될 경우,
같은 feature map을 regressor에 넣어 proposed region의 좌표가 실제 객체의 위치를 포함할 수 있도록 회귀분석을 한다.

지금까지 R-CNN 학습 과정에 대해 알아보았는데 이 학습 과정에서 애매한 점이 있다
바로 proposed region에 대한 label은 어떤 것이냐 하는 점이다. 제공되는 데이터셋에는 객체에 대한 ground truth만 달려있을 뿐 proposed regions에 대한 label이 따로 존재하지 않는다.
위의 예시에서만 봐도 그렇다. 잘려진 이미지를 SVM classifier과 regressor에 넣어 학습시켜야 하는데 학습의 기준이 되는 label이 존재하질 않는다. 그래서 사용하는 게 바로 IoU이다.
R-CNN에서는 ground truth와 proposed region 사이의 IoU 값을 계산해 0.5 이상인 경우,
해당 region을 객체로 바라보고 ground truth와 같은 class로 labelling을 한다.
따라서 R-CNN에서는 IoU가 labelling 과정에서 핵심적으로 사용된다 말할 수 있을 것 같다.
def get_iou(a, b, epsilon=1e-5):
# COORDINATES OF THE INTERSECTION BOX
x1 = max(a[0], b[0])
y1 = max(a[1], b[1])
x2 = min(a[2], b[2])
y2 = min(a[3], b[3])
# AREA OF OVERLAP - Area where the boxes intersect
width = (x2 - x1)
height = (y2 - y1)
# handle case where there is NO overlap
if (width<0) or (height <0):
return 0.0
area_overlap = width * height
# COMBINED AREA
area_a = (a[2] - a[0]) * (a[3] - a[1])
area_b = (b[2] - b[0]) * (b[3] - b[1])
area_combined = area_a + area_b - area_overlap
# RATIO OF AREA OF OVERLAP OVER COMBINED AREA
iou = area_overlap / (area_combined+epsilon)
return iou 