Santander Product Recommendation
https://www.kaggle.com/c/santander-product-recommendation/kernels
Data 살펴보기 > Cleansing
https://www.kaggle.com/apryor6/detailed-cleaning-visualization
우선 엑셀에 데이터를 표로 구성하고, datatype을 정하고, 특징을 정리한다.
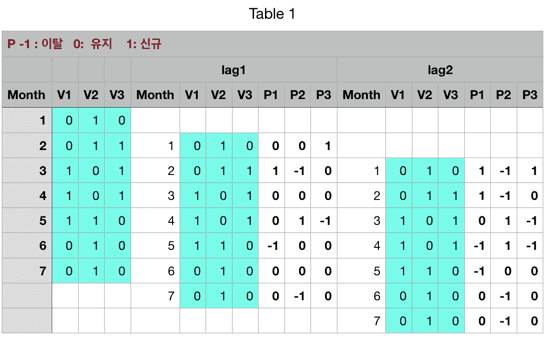
d0<- data.table(Month=c(1:7),
V1=c(0,0,1,1,1,0,0),
V2=c(1,1,0,0,1,1,1),
V3=c(0,1,1,1,0,0,0))
# way1
d0.lag1 <- copy(d0)
d0.lag1[, Month:=Month+1]
names(d0.lag1)[2:4] <- str_c(names(d0.lag1)[2:4],"_lag1")
d1 <- merge(d0, d0.lag1, by="Month", all.x=T, roll=Inf)
#d1[is.na(d1)] <- 0
# way2
d0.lag1 <-d0[ , lapply(.SD, function(x) lag(x)), .SDcols=str_subset(names(d0), "V")]
#d0.lag1 <-d0[ , lapply(.SD, lag)][, 2:4]
names(d0.lag1) <- str_c(names(d0.lag1),"_lag1")
d1 <- cbind(d0, d0.lag1)
#cols <- str_c("p",1:3,"_lag1")
#d0[ , P1:=V1-V1_lag1]
#d0[ , ':='(P1=V1-V1_lag1,P2=V2-V2_lag1, P3=V3-V2_lag1)]
for(i in 1:3){
cols <- c(str_c("V",i), str_c("V",i,"_lag1"))
d1[, str_c("P", i):=.SD[[1]]-.SD[[2]], .SDcols=cols]
}
> d0.lag1
Month V1_lag1 V2_lag1 V3_lag1
1: 2 0 1 0
2: 3 0 1 1
3: 4 1 0 1
4: 5 1 0 1
5: 6 1 1 0
6: 7 0 1 0
7: 8 0 1 0> d1
Month V1 V2 V3 V1_lag1 V2_lag1 V3_lag1
1: 1 0 1 0 NA NA NA
2: 2 0 1 1 0 1 0
3: 3 1 0 1 0 1 1
4: 4 1 0 1 1 0 1
5: 5 1 1 0 1 0 1
6: 6 0 1 0 1 1 0
7: 7 0 1 0 0 1 0> d1
Month V1 V2 V3 V1_lag1 V2_lag1 V3_lag1 P1 P2 P3
1: 1 0 1 0 NA NA NA NA NA NA
2: 2 0 1 1 0 1 0 0 0 1
3: 3 1 0 1 0 1 1 1 -1 0
4: 4 1 0 1 1 0 1 0 0 0
5: 5 1 1 0 1 0 1 0 1 -1
6: 6 0 1 0 1 1 0 -1 0 0
7: 7 0 1 0 0 1 0 0 0 0